链表学习小结
与数组的对比
基本介绍
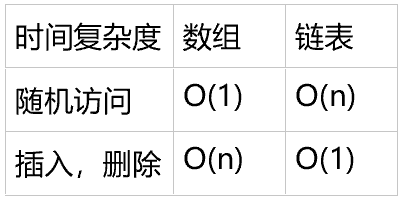
说到数据结构的储存方式,我们很容易就想到了数组和链表这两个最基本的存储方式,在进行相关内容的学习后,我们也很容易的想到二者的优缺点:
数组:
适合数据的查找,但是进行数据的删除和插入却十分耗费时间。在申请内部空间的时候,必须要确定具体的大小,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配给它,导致“内存不足”,当然在C++中vector数组解决了这个问题,相应的Java中Arraylist也解决这个问题,但是在超过其容量,他们的处理机制是怎么样的呢?它们会再申请一个更大的空间,然后将原来的数据全部拷贝进去,我们知道,拷贝数据也是一个很耗时的工作,因此这仍然也有一个劣势。
链表:
适合数据的插入和删除,但是查找数据却显得比较困难,遍历耗时比较长。链表本身没有大小的限制,天然地支持动态扩容,我觉得这也是它与数组最大的区别,它存储数据不像数组那样,不必需要一个连续的空间,它是通过指针将不同的空间连接起来。
分析
数组再进行随机访问只要知道序号,我们就可以直接访问,但是如果要进行插入时,假设插入的序号为k,那么我们需要把k后面的元素全部向后移一位,如果是最后一个数,我们直接将数据插入到最后一个位置即可,此时时间复杂度是O(1),如果是第一个数,时间复杂度就是O(n),综合平均时间复杂度就是O(n),删除的话就全部向前面移一位,平均时间复杂度就是O(n);
链表的话如果进行随机访问,必须从第一个数开始向后面一个一个遍历,直到找到我们需要找到的值,假设是第一个数,那么时间复杂度为O(1),如果是最后一个数,则时间复杂度是O(n),平均时间复杂度就是O(n)。
几种常见的链表
首先,先把几种常见的链表展现在下方:
- 单链表
- 循环链表
- 双向链表
- 双向循环链表
单链表
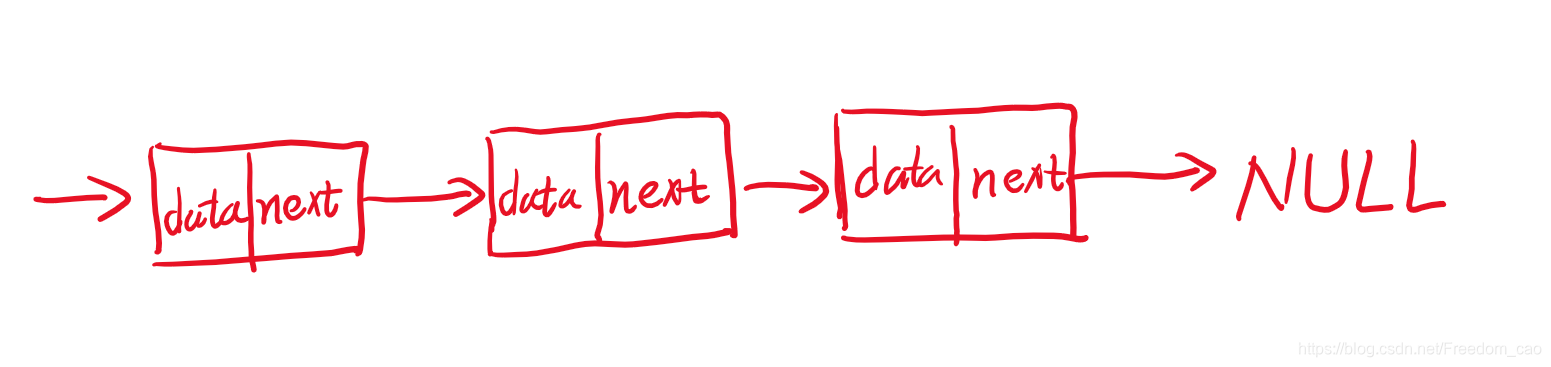
单链表是最基础的链表,所以必须是要掌握的,链表通过指针将一组零散的内存块串联在一起。其中,我们把内存块称为链表的“结点”。为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址。如图所示,我们把这个记录下个结点地址的指针叫作后继指针 next。
循环链表
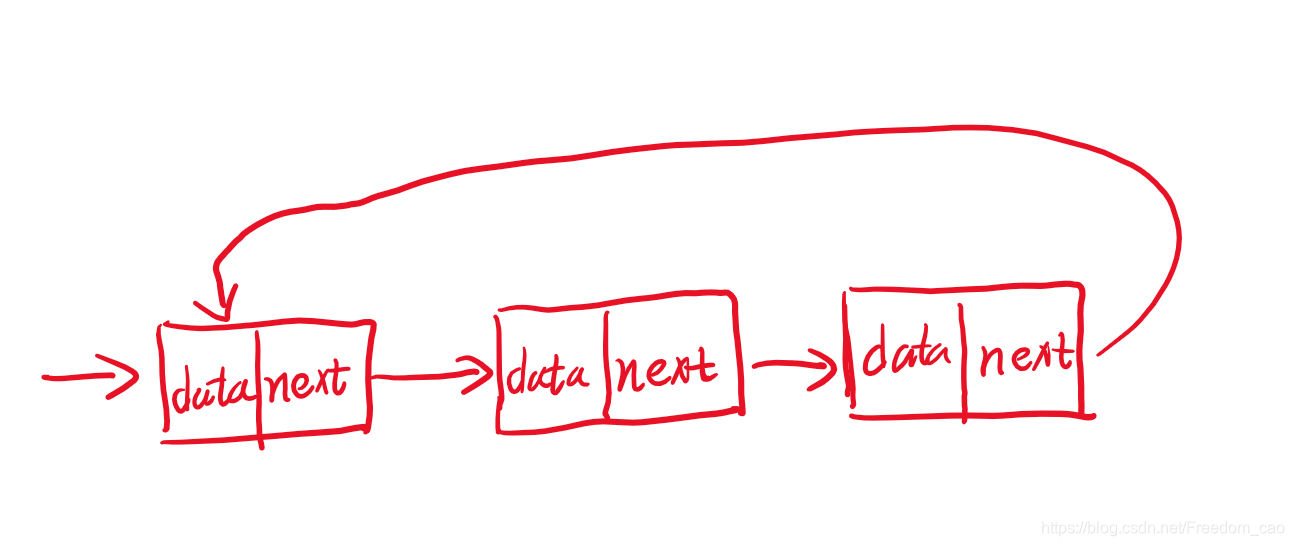
循环链表再单链表的基础上将最后面的指向NULL的指针重新设定为指向头结点,实现一个循环机制。
双向链表
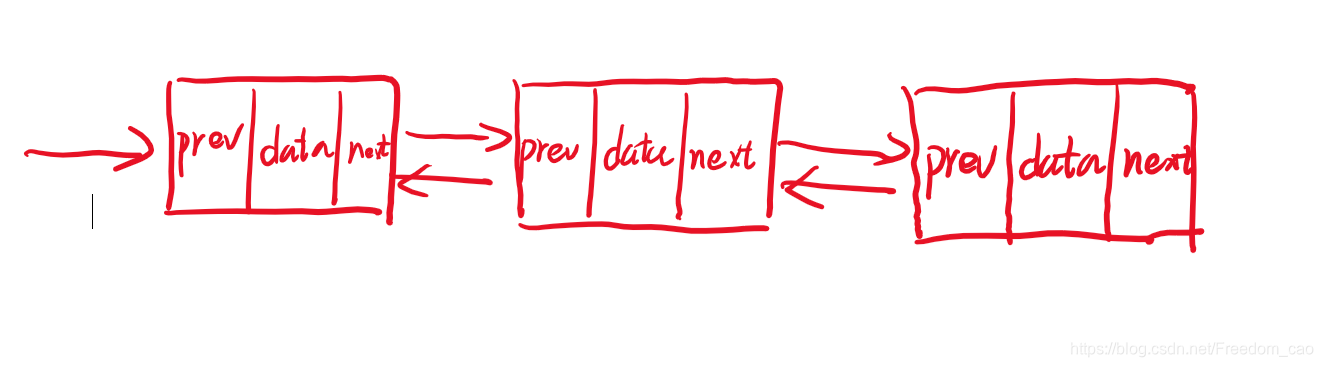
双向链表就是在单链表的基础上,增加了一个prev指针,指向前面一个结点。
双向循环链表
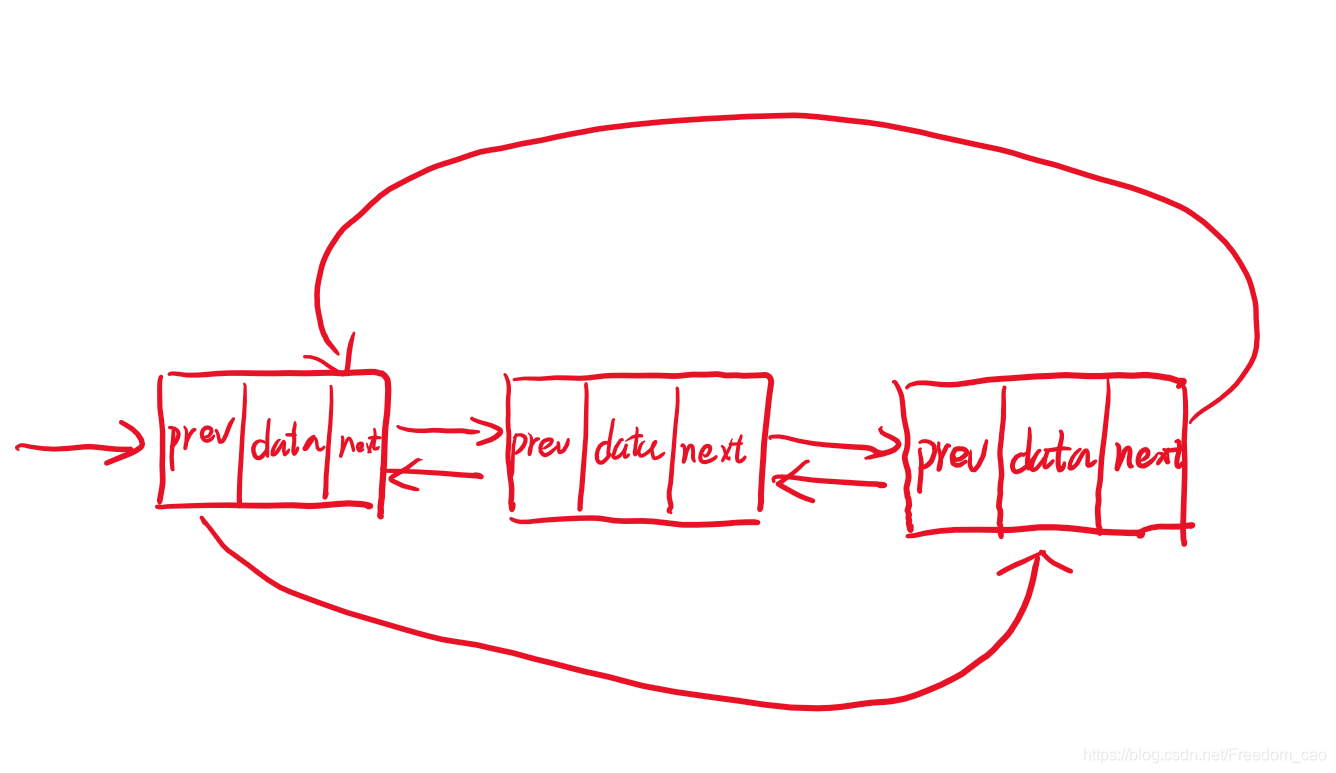
双向循环链表就是在双向链表和循环链表的结合,这个用的也是最多的,这里采取的是一个用时间换空间的方法,它新增了内存,但是在有些情况下运行速度相对于单链表更快,就比如说删除一个数据吧,常见的一些算法书籍中都会说单项链表得时间复杂度是O(1),但是实际上真是如此吗?咱们来仔细探究一下。
通常心中一个新的数据有两种情况:
- 删除结点中“值等于某个给定值”的结点;
- 删除给定指针指向的结点。
对于情况1,我们用单链表我们首先必须是遍历,找到我们需要删除的那个结点才可,因此,从这种意义上来看,它的时间复杂度实际还是O(n),,当然这时双向循环链表也是一样,没有什么区别。
但是对于情况2就不一样了,想要删除给定位置的结点,必须要找到它前一个结点,所以我们必须要先遍历,直到p->next==q时,才可以进行删除,这里的时间复杂度是O(n),而双向循环链表(双向链表)直接q->prev就可以找到前一个结点,从而进行删除,这里就是O(1)了。
如何实现LRU缓存淘汰算法
LRU缓存淘汰算法
首先在写这个之前,我们首先要知道,什么叫LRU缓存淘汰算法。
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用,比如常见的 CPU 缓存、数据库缓存、浏览器缓存等等。缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。
常见的策略有三种:先进先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)。
假如说,你买了很多本技术书,但有一天你发现,这些书太多了,太占书房空间了,你要做个大扫除,扔掉一些书籍。那这个时候,你会选择扔掉哪些书呢?对应一下,你的选择标准是不是和上面的三种策略神似呢?
如何实现LRU缓存淘汰算法
我们维护一个有序单链表,越靠近链表尾部的结点是越早之前访问的。当有一个新的数据被访问时,我们从链表头开始顺序遍历链表。
当过来一个数据时,我们需要变量,看看是否在链表中出现。
- 出现:将这个数据拿到链表的头部
- 没有出现:
a. 如果此时缓存未满,则将此结点直接插入到链表的头部;
b. 如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部。
这样,我们就用链表实现了LRU缓存淘汰算法.
如何书写链表代码
1.注意指针的含义
由于链表中含有很指针的出现,如果对指针含义一知半解的话,书写链表的代码自然是十分困难的,因此,我们必须要知道指针的含义,那么指针应该如何认识呢?
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
下面来举具体的例子:
p->next=q表示p的next指针存储了q的内存地址
p->next=p->next->next表示p 结点的 next 指针存储了 p 结点的下下一个结点的内存地址。
2.警惕指针丢失和内存泄漏
怎么说呢,大致就是我们再写代码的时候,常常会由于一些错误,导致一个链表变成了一半或者有一些片段不受控制,无法再通过指针进行调动,比如下面的: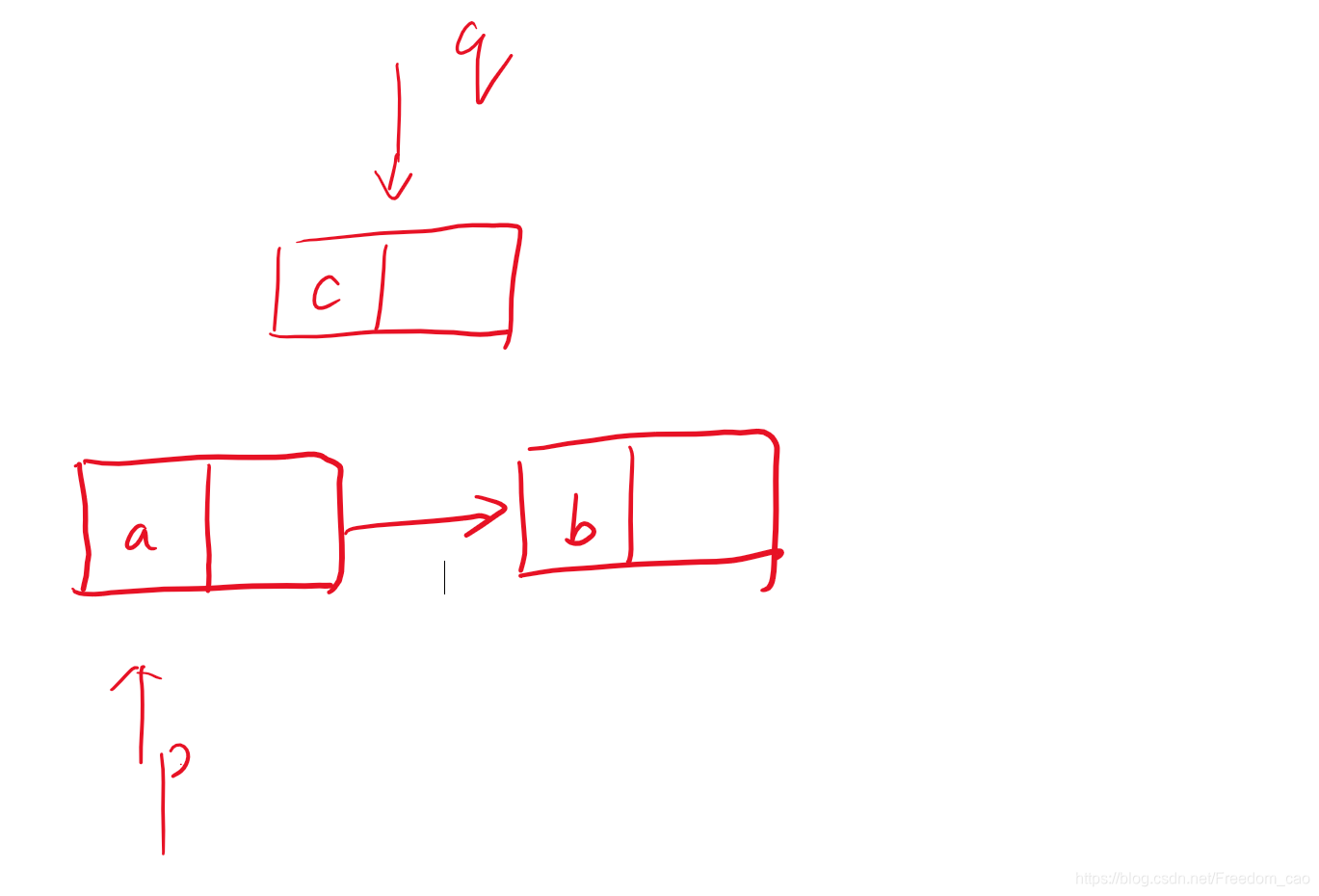
//插入一个结点(将q插到p的下一个)
p->next=q;
q->next=p->next;
这个代码我们很容易发现是一个错的,因为p->next已经时q了,q->next却还是q,这显然是不对,因为原来的p->next已经脱离了我们的链表,那么需要如何改正呢?我们只需要把两个代码的顺序改变一下就OK了,所以,我们插入结点时,一定要注意操作的顺序,必须要将新结点的下一个结点确定,再指向新结点。
同理,删除链表结点时,也一定要记得手动释放内存空间,否则,也会出现内存泄漏的问题。
3.加入一个头结点简化代码
在我们进行正常的操作时,如果我们需要插入一个新的结点,那么我们需要的操作是:
q->next=p->next;
p->next=q;
但是,如果这是这是一个空链表,就不符合上面的代码了,我们应该要这样:
if (p==NULL)
node* p = new node;
同理,如果要进行链表的删除结点操作,我们需要的代码为:
p->next=p->next->next;
但是,如果要删除得是链表的最后一个位置,这样的操作是不是又出现问题了呢?我们应该要这样写:
if(p->next==NULL)
p=NULL;
因此,是不是觉得有一些麻烦,如何解决这个问题呢?加一个头结点即可:
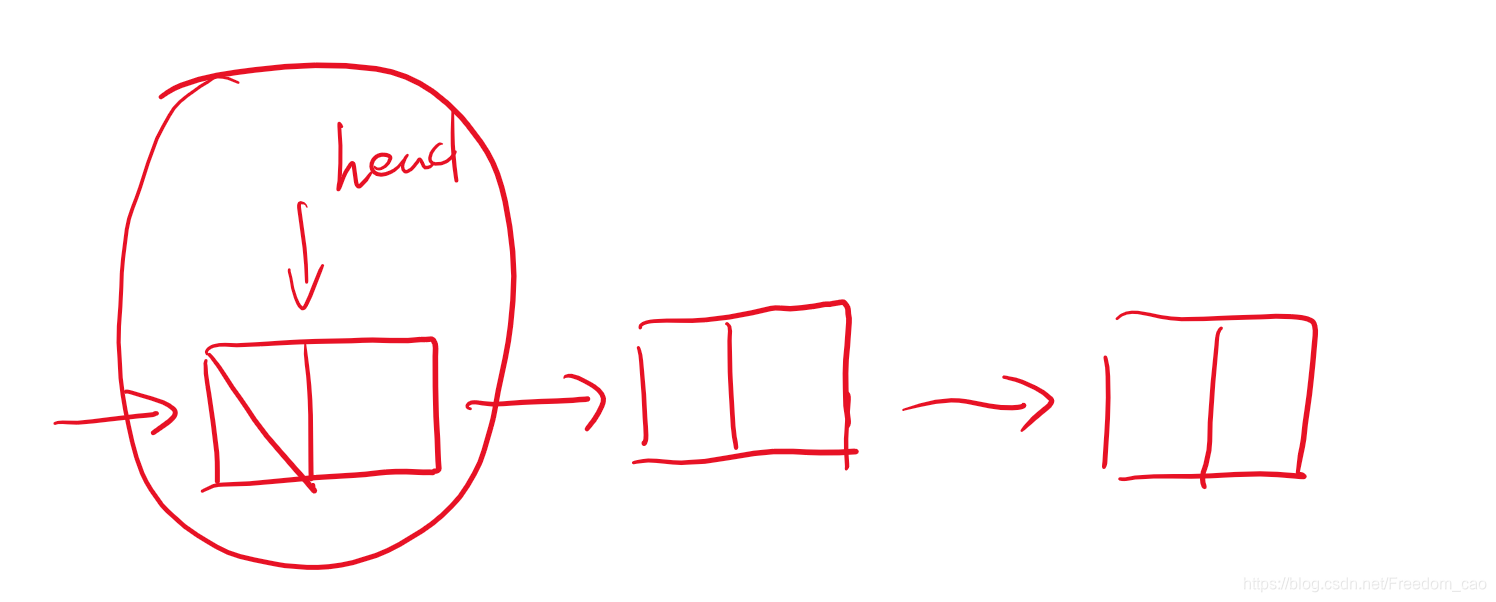
头结点就是一个不包含数据的结点,加上仅仅为了统一代码,方便书写。
4.留意边界条件的处理
就书写链表的代码时,要多多留意所写的代码在边界的范围内是否满足,比如:
- 空链表时是否满足
- 链表只包含一个结点时,代码是否能正常工作
- 链表只包含两个结点时,代码是否能正常工作
- 码逻辑在处理头结点和尾结点的时候,是否能正常工作
如果都没有什么问题,那基本就是没有什么问题了;
5.可以画图像帮助理解以及进行代码的书写
就比如说我上面画的这个图,进行链表的链接,如果有图的话,书写代码可能会变得更加方便且不易出错。
6.多写多练
如果自己不是那种智商特别特别高的的人,建议还是多写一些链表的练习,练习多了,书写起来自然顺畅,下面给几个练习的题目,如果有兴趣可以写一写。
- 单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第 n 个结点
- 求链表的中间结点
在我的另一篇博客中,写了其中的1,3,4,如果有需要的话,可以参考那一篇博客,下面附上它的链接:
链接:C++链表的基本操作——链表的构造,链表的析构,链表的插入,链表的删除,链表的就地逆置,头插法逆置
至此,该篇blog结束了,如果对您有帮助的话,不妨点个赞呗。