KafkaUtils.createDirectStream方式(推荐使用createDirectStream,不推荐使用createDstream)
1.createDirectStream方式不同于createDstream的Receiver接收数据的方式,createDirectStream定期地从kafka的topic下对应的partition中查询最新的偏移量,
再根据偏移量范围在每个batch(批次)里面处理数据,Spark通过调用kafka简单的消费者Api(低级api)读取一定范围的数据。
2.createDirectStream方式相比基于Receiver的createDstream方式有几个优点:
1.简化并行
不需要创建多个kafka输入流,然后union它们,sparkStreaming将会创建和kafka中的topic分区数相同的rdd的分区数,
而且会从kafka中并行读取数据,spark中RDD的分区数和kafka中的topic分区数是一一对应的关系。
2.高效
createDstream方式实现数据的零丢失是将数据预先保存在WAL中,会复制一遍数据,会导致数据被拷贝两次,
第一次是接受kafka中topic的数据,另一次是写到WAL中。而不使用createDstream的receiver的这种方式则消除了这个问题。
3.恰好一次语义(Exactly-once-semantics,即EOS)
createDstream方式的Receiver读取kafka数据是通过 kafka的高级api 把偏移量写入zookeeper中,
虽然这种方法可以通过把数据保存在WAL中保证数据不丢失,但是可能会因为Spark Streaming和zookeeper中保存的偏移量不一致
而导致数据被消费了多次。
createDirectStream方式的恰好一次语义(Exactly-once-semantics,即EOS) 则通过实现 kafka低级api,
topic中的偏移量仅仅被StreamingContext保存在客户端程序的checkpoint目录中,topic中的偏移量则不再保存在zookeeper中,
那么程序只需要到checkpoint目录中读取topic中的偏移量即可,便从而消除了zookeeper和StreamingContext中偏移量不一致的问题,
但是同时也造成无法使用基于zookeeper的kafka监控工具来读取到topic的相关信息。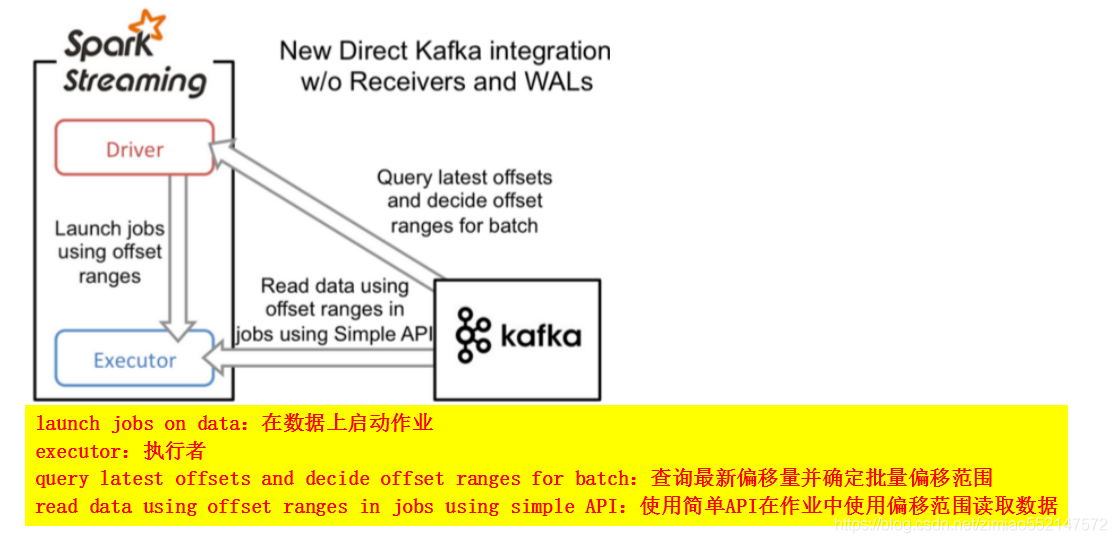
3.编写Spark Streaming应用程序(createDirectStream方式的版本)
package cn.itcast.dstream.kafka
import kafka.serializer.StringDecoder
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
// 利用sparkStreaming对接kafka实现单词计数:createDirectStream 采用Direct(低级API)
object SparkStreamingKafka_Direct
{
def main(args: Array[String]): Unit =
{
//1、创建sparkConf。setMaster("local[2]"):本地模式运行
//setMaster("local[2]"):本地模式运行,启动两个线程
//设置master的地址local[N] ,n必须大于1,其中1个线程负责去接受数据,另一线程负责处理接受到的数据
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingKafka_Direct").setMaster("local[2]")
//2、创建sparkContext
val sc = new SparkContext(sparkConf)
//设置日志输出的级别
sc.setLogLevel("WARN")
//3、构建StreamingContext对象,每个批处理的时间间隔,即以多少秒内的数据划分为一个批次 ,当前设置 以5秒内的数据 划分为一个批次
val ssc = new StreamingContext(sc, Seconds(5))
//createDirectStream采用低级API的关系,topic中的偏移量仅仅被StreamingContext保存在客户端程序的checkpoint目录中,
//topic中的偏移量则不再保存在zookeeper中。此处设置checkpoint路径,当前项目下有一个Kafka_Direct目录
ssc.checkpoint("./Kafka_Direct")
//4、配置kafka相关参数:配置每个kafka服务器的IP:端口,还有"group.id"(消费者组groupId)
//配置group.id:多个Consumer的group.id都相同的话,表示多个Consumer都在同一个消费组group中
val kafkaParams=Map("metadata.broker.list"->"NODE1:9092,NODE2:9092,NODE3:9092","group.id"->"Kafka_Direct")
//5、定义topic的主题名。
//此处没使用topics.split("分隔符").toSet。topic中数据还可设置以分隔符进行切割,进而切割出每行数据
val topics=Set("kafka_spark")
//6、通过 KafkaUtils.createDirectStream 接收 kafka数据,这里采用是kafka低级api偏移量不受zookeeper管理
val dstream: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topics)
//7、获取kafka中topic中的数据
//获取元组中的值格式:元组名._下标。
//map(_._2):表示map遍历出的每个元素是元祖的同时,并获取元祖中下标为2的值,下标从1开始。
//partition.foreach(tuple=>{tuple._2} 和 map(_._2) 均都为“元组名._下标值2”,最终取出的数据才为真正要进行处理的数据。
val topicData: DStream[String] = dstream.map(_._2)
//8、切分每一行,每个单词计为1
//flatMap(_.split(" ")) 流的扁平化,最终输出的数据类型为一维数组Array[String],所有单词都被分割出来作为一个元素存储到同一个一维数组Array[String]
//map((_,1))每个单词记为1,即(单词,1),表示每个单词封装为一个元祖,其key为单词,value为1,返回MapPartitionRDD数据
val wordAndOne: DStream[(String, Int)] = topicData.flatMap(_.split(" ")).map((_,1))
//9、相同单词出现的次数累加
//分组聚合:reduceByKey(_+_) 相同单词出现的次数累加,表示对相同的key(单词)对应的value进行累加计算
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_)
//10、打印输出
result.print()
//开启计算
ssc.start()
ssc.awaitTermination()
}
}
4.查看对应的效果
1.向topic中添加数据,通过shell命令向topic发送消息
cd /root/kafka
格式:bin/kafka-console-producer.sh --broker-list kafka的IP:9092 --topic 主题名
例子:bin/kafka-console-producer.sh --broker-list NODE1:9092 --topic kafka_spark

2.查看控制台的输出:

============================================================
spark streaming从kafka获取数据,计算处理后存储到redis
因为数据要存入redis中,获取redis客户端代码如下
package com.fan.spark.stream
import org.apache.commons.pool2.impl.GenericObjectPoolConfig
import redis.clients.jedis.JedisPool
/**
* Created by http://www.fanlegefan.com on 17-7-21.
*/
object RedisClient {
val redisHost = "127.0.0.1"
val redisPort = 6379
val redisTimeout = 30000
lazy val pool = newJedisPool(newGenericObjectPoolConfig(), redisHost, redisPort, redisTimeout)
lazy val hook = newThread {
override def run = {
println("Execute hook thread: " + this)
pool.destroy()
}
}
sys.addShutdownHook(hook.run)
}
实时计算代码如下
package com.fan.spark.stream
import java.text.SimpleDateFormat
import java.util.Date
import kafka.serializer.StringDecoder
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by http://www.fanlegefan.com on 17-7-21.
*/
object UserActionStreaming
{
def main(args: Array[String]): Unit =
{
val df = newSimpleDateFormat("yyyyMMdd")
//设置master的地址local[N] ,n必须大于1,其中1个线程负责去接受数据,另一线程负责处理接受到的数据
val sparkConf = newSparkConf().setAppName("pvuv").setMaster("local[3]")
val sc = newSparkContext(sparkConf)
//构建StreamingContext对象,每个批处理的时间间隔,即以多少秒内的数据划分为一个批次 ,当前设置 以 1 秒内的数据 划分为一个批次,每一个batch(批次)就构成一个RDD数据集
//DStream就是一个个batch(批次)的有序序列,时间是连续的,按照时间间隔将数据流分割成一个个离散的RDD数据集
val ssc = newStreamingContext(sc, Seconds(10))
ssc.checkpoint("/home/work/IdeaProjects/sparklearn/checkpoint")
val group = "test"
val topics = "test"
val topicSets = topics.split(",").toSet //topic中的数据以","作为分隔符,即相当于把","作为回车换行的标志,进而切割出每行数据
val kafkaParams = Map[String, String](
"metadata.broker.list"-> "localhost:9092",
"group.id"-> group
)
val stream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicSets)
//1.sparkStreaming将会创建和kafka中的topic分区数相同的rdd的分区数,而且会从kafka中并行读取数据,spark中RDD的分区数和kafka中的topic分区数是一一对应的关系。
//2.如果kafka创建topic的命令中指定分区数为3个的话,那么就会有对应的3个RDD,所以必须使用stream.foreachRDD遍历每个RDD。
// 同时每个RDD中又会有多个partition分区,所以必须使用rdd.foreachPartition遍历RDD中的每个partition分区。
// 而每个partition分区中存储有topic中的数据,因此需要使用partition.foreach遍历每个partition分区中的多个元祖tuple,
// 而每个元祖tuple封装一条数据,因此使用tuple._2 即通过“元组名._下标值2”的方式才能获取topic中真正的每行数据。
//3.如果kafka创建topic的命令中不指定分区数的话,那么使用 stream.map(_._2) 即通过“元组名._下标值2”的方式便能获取topic中存储的所有数据。
stream.foreachRDD(rdd=>rdd.foreachPartition(partition=>
{
val jedis = RedisClient.pool.getResource
partition.foreach(tuple=>
{
//获取元组中的值格式:元组名._下标。
//map(_._2):表示map遍历出的每个元素是元祖的同时,并获取元祖中下标为2的值,下标从1开始。
//partition.foreach(tuple=>{tuple._2} 和 map(_._2) 均都为“元组名._下标值2”,最终取出的数据才为真正要进行处理的数据。
//因为使用topics.split(",").toSet,即topic中的数据把","分隔符作为回车换行的标志,所以此处获取出的数据为一行数据
val line = tuple._2
//对一行数据以","分隔符进行切割,一行数据被分为4个小字符串并封装到字符串数组中
val arr = line.split(",")
val user = arr(0) //字符串数组(下标):取出一行字符串数据中的第一个被分割出来的小字符串
val page = arr(1)
val money = arr(2)
val day = df.format(newDate(arr(3).toLong))
//uv
jedis.pfadd(day + "_"+ page , user)
//pv
jedis.hincrBy(day+"_pv", page, 1)
//sum
jedis.hincrByFloat(day+"_sum", page, money.toDouble)
})
}))
ssc.start()
ssc.awaitTermination()
}
}