数据结构实现 6.1:二叉堆_基于动态数组实现(C++版)
1. 概念及基本框架
二叉堆 是一种高级数据结构,这里我们通过 1.1 中的 动态数组 来实现。
因为二分搜索树操作的时间复杂度(O(logn) 级别)远远低于数组操作的时间复杂度(O(n) 级别),原因在于二叉树结构本身具有的层级效果。(操作次数越多越明显)所以在实现二叉堆时,我们虽然在存储上使用动态数组,但逻辑上会参考二叉树的结构,这样有利于快速操作。
为此,我们需要理解几个与二叉树有关的概念。
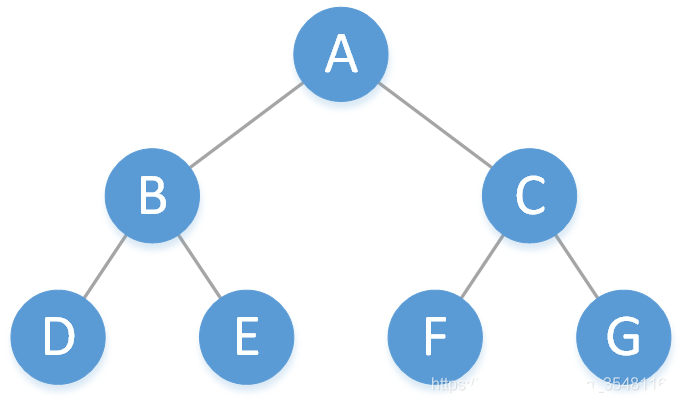
1.1 满二叉树
满二叉树作为二叉树的一种,有着如下特性:
1.最后一层的结点(叶子结点)的左右子结点均为空。
2.除叶子结点外,其他结点的左右两个子结点均不为空。
3.若满二叉树有 k 层,那么整棵满二叉树一共有 2^k - 1 个结点。
4.若记根节点为第 0 层,满二叉树的第 n 层结点一共有 2^n 个结点。
5.满二叉树的前 n 层结点一共有 2^n - 1 个结点。
注:满二叉树对结点保存的数据大小并没有特殊要求。
下图给出的就是一棵满二叉树:
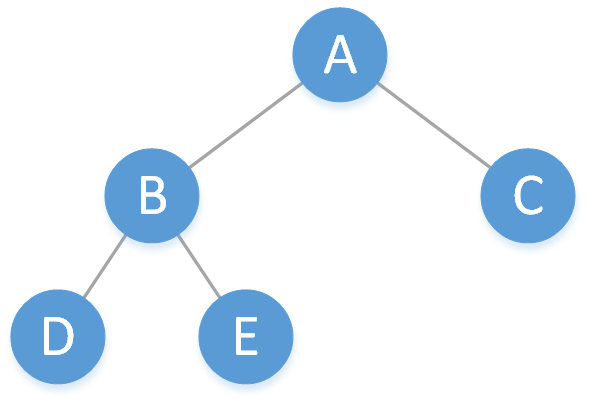
1.2 完全二叉树
完全二叉树也是二叉树的一种,它是由满二叉树引出来的,完全二叉树有如下特性:
1.若完全二叉树有 k 层,那么树的前 k - 1 层是一棵满二叉树。
2.若该树不是满二叉树,那么第 k 层的结点全部连续集中在左边。
3.若完全二叉树有 k 层,那么整棵完全二叉树一共有 2^(k - 1) ~ 2^k - 1 个结点。
注:满二叉树是完全二叉树的一种特例。
下图给出的就是一棵完全二叉树:
接下来,我们尝试用数组的储存结构,完全二叉树的逻辑结构来创建一个二叉堆。
首先,我们先定义一个二叉堆的类,我们不给出构造函数,编译器会默认实现。
template <class T>
class MaxHeap{
...
private:
Array<T> arr;
};
这里为了避免重复设计就可以兼容更多数据类型,引入了 泛型 ,即 模板 的概念。(模板的关键字是 class 或 typename)
对于数组而言,为了降低操作的时间复杂度,我们最好选择在数组的末尾增、删元素;而对于完全二叉树的添加元素操作可以看作是由根结点从左至右一层一层的添加元素,存储上与逻辑上的关系如下:

所以能够得到结点之间索引的关系就显得至关重要。
其实不难发现,若记一个结点的索引为 i ,那么其左边的子结点索引是 2 * i + 1 ,而其有右边的子结点索引是 2 * (i + 1) 。所以,我们可以在类中实现这样的几个函数,来获得逻辑结构上某一结点对应数组位置的索引。
template <class T>
class MaxHeap{
...
private:
int parent(int index){
if (index <= 0 || index >= arr.size()){
return NULL;
}
return (index - 1) / 2;
}
int leftChild(int index){
return index * 2 + 1;
}
int rightChild(int index){
return (index + 1) * 2;
}
...
};
parent :返回父结点的索引
leftChild :返回左边子结点的索引
rightChild :返回右边子结点的索引
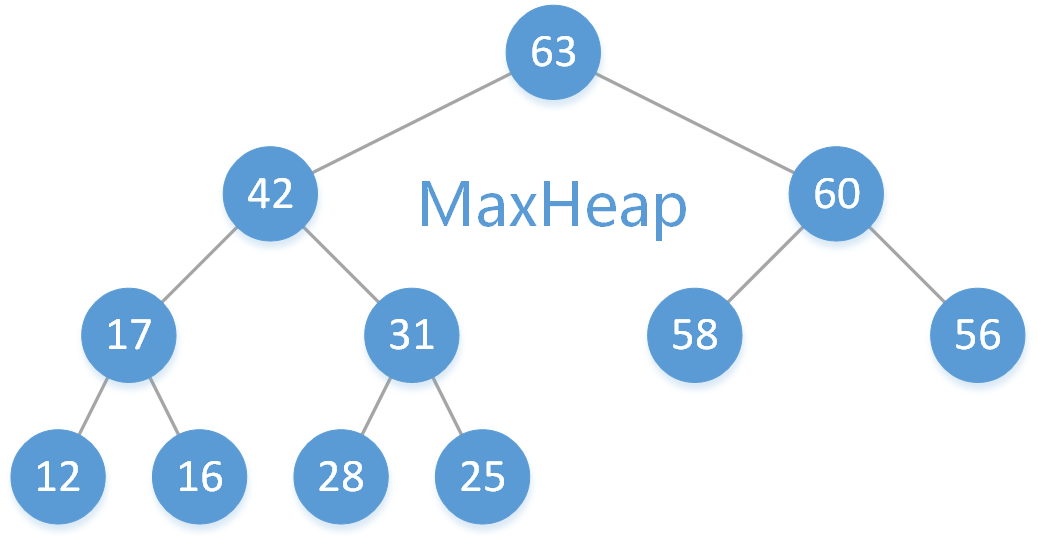
二叉堆有两种,最大堆和最小堆,这里我们要实现的就是一个最大二叉堆。
将最大二叉堆看成二叉树结构会有如下性质:
1.最大二叉堆是一棵完全二叉树。
2.每个结点的值 大于等于 其左右子结点的值,即最大二叉堆存放的数据要具有可比性。
注:最小二叉堆性质可以类比。
下图就是一个最大二叉堆:
接下来我们就对最大二叉堆的增、删、查以及一些其他基本操作用代码去实现。
2. 基本操作程序实现
2.1 增加操作
对于最大二叉堆的增加操作而言我们可以先从逻辑结构上进行推理,然后利用数组去实现。
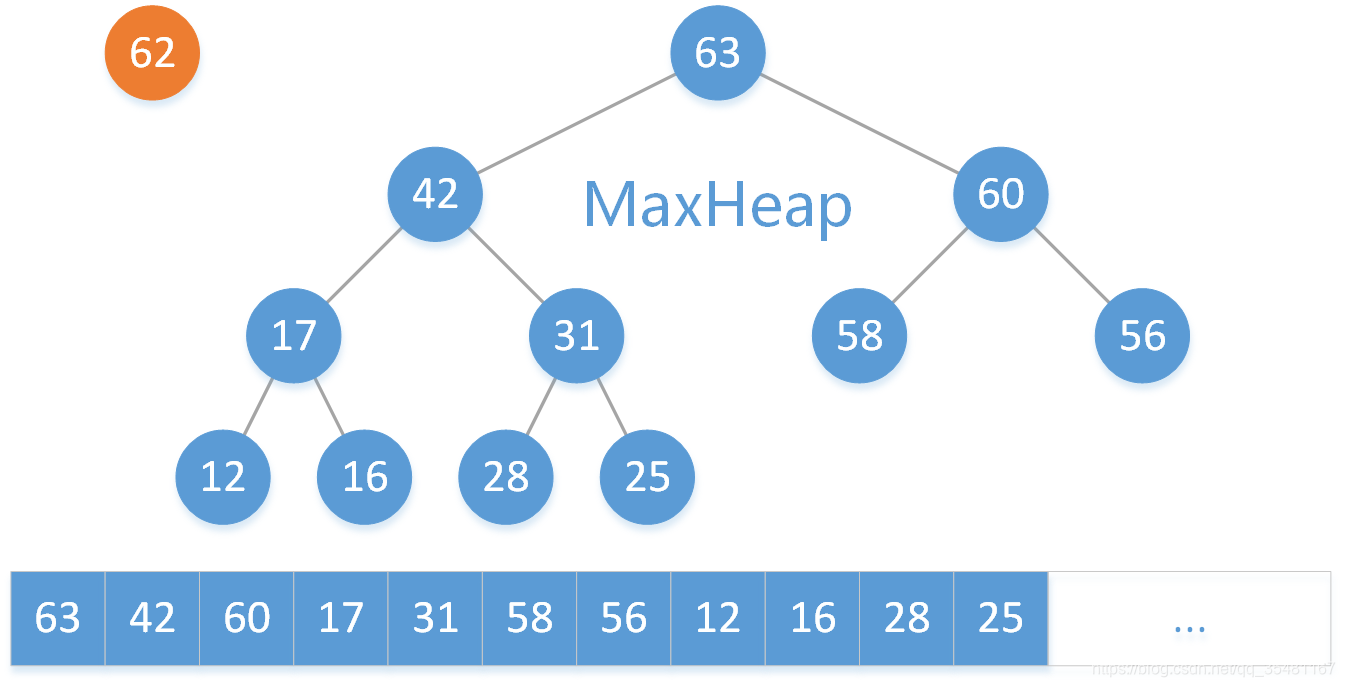
我们有这样最大二叉堆,下面表示的是数组的实际存放位置。这时我们要将 62 这个元素放入数组中。
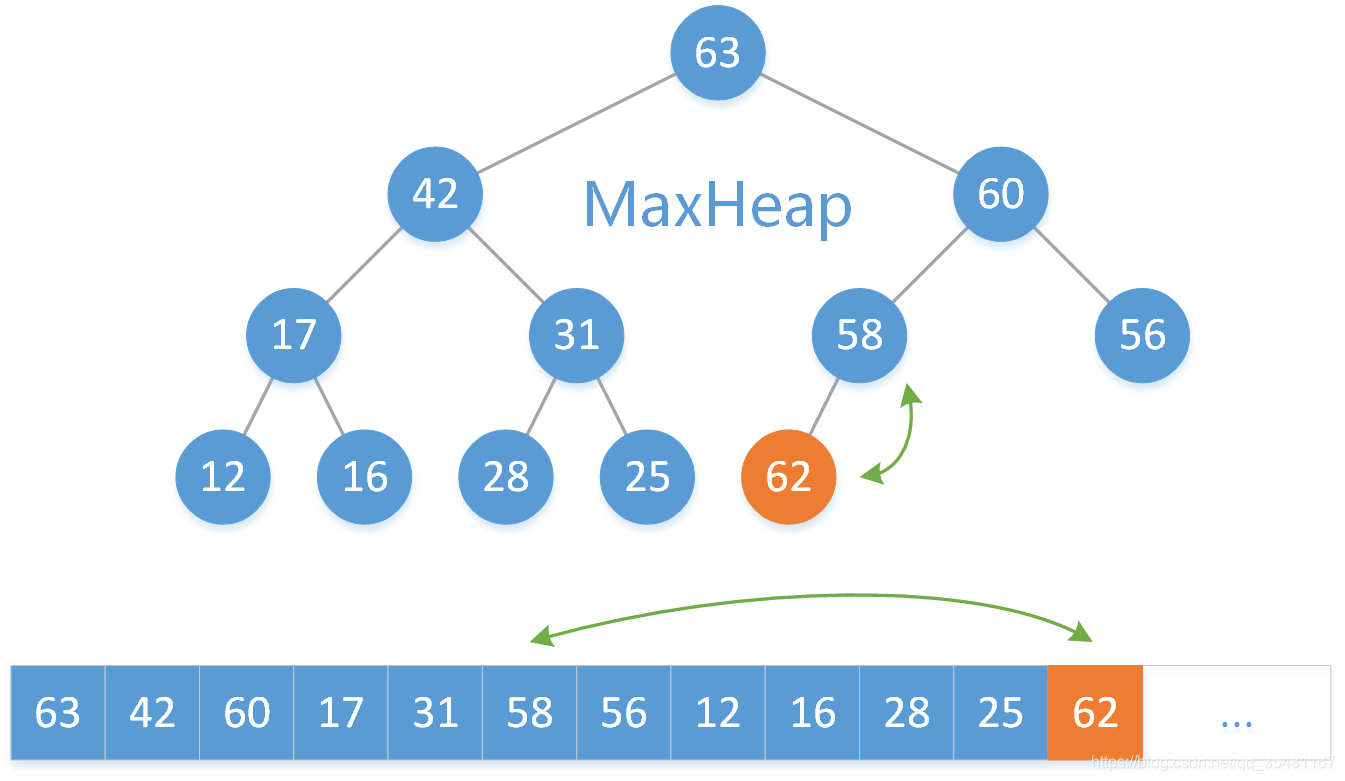
第一步:把 62 放到数组的末尾。
第二步:找到 62 的父结点 58 ,因为 62 > 58 ,不满足最大二叉堆的定义,所以交换 62 和 58 两个元素。
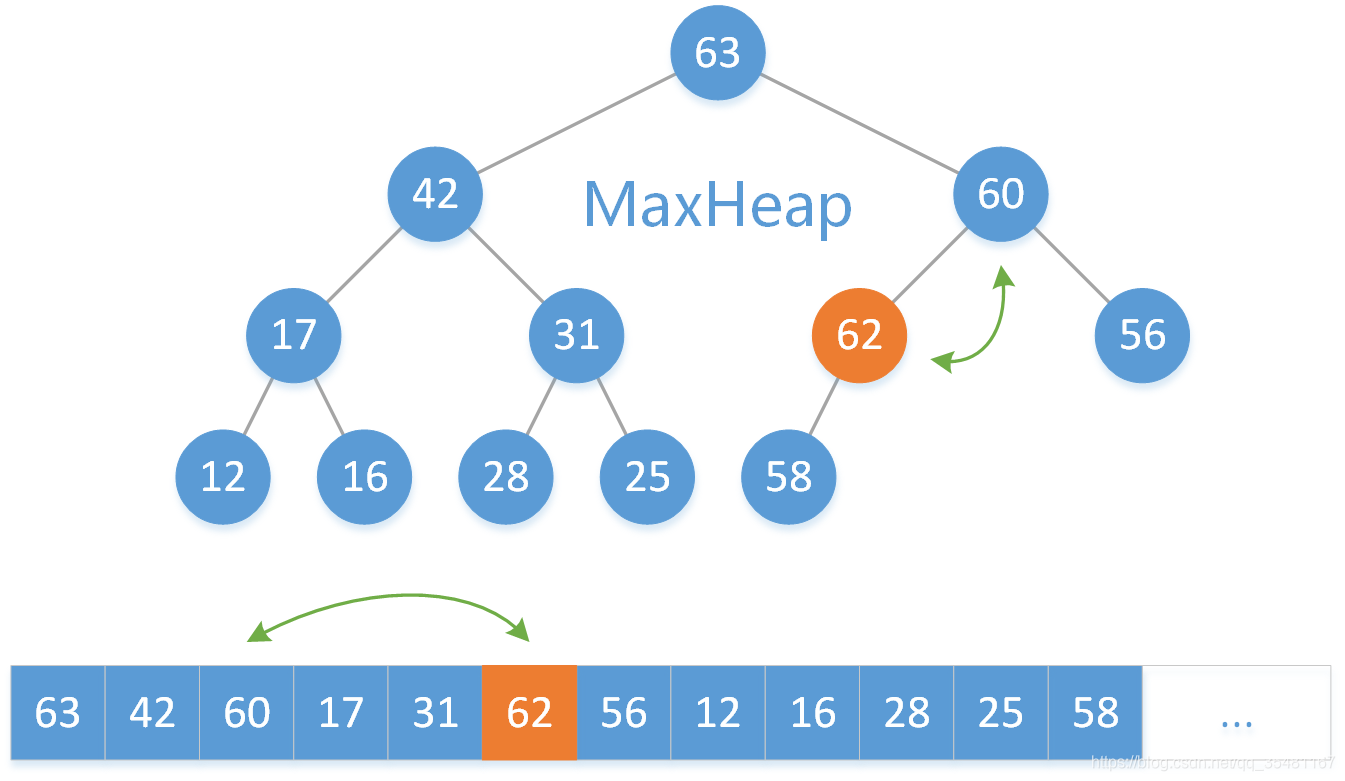
然后继续将 62 与其父结点 60 比较,因为 62 > 60 ,所以交换 62 和 60 两个元素。
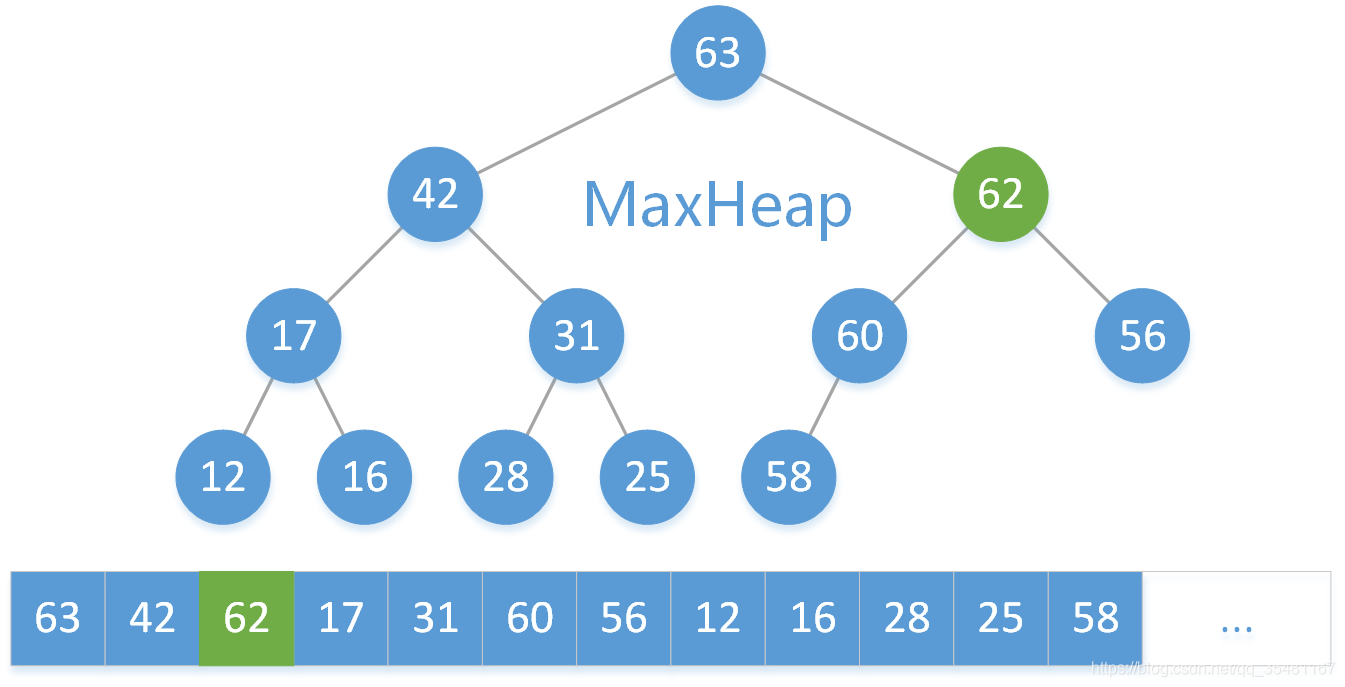
继续将 62 与其父结点 63 比较,因为 62 < 63 ,满足最大二叉堆定义,所以增加操作结束。
通过上面的实例,我们发现,除了数组的增加操作之外,还需要一个逐步交换元素的函数,我们称之为 上浮(siftUp),具体代码如下:
template <class T>
class MaxHeap{
...
private:
...
void siftUp(int index){
while (index && arr.get(index) > arr.get(parent(index))){
swap(index, parent(index));
index = parent(index);
}
}
...
};
这里为了交换方便,编写了一个 swap 函数 ,当然,这个函数也可以定义在数组内部。
template <class T>
class MaxHeap{
...
private:
...
void swap(int i, int j){
if (i < 0 || i >= arr.size() || j < 0 || j >= arr.size()){
return;
}
T t = arr.get(i);
arr.set(i, arr.get(j));
arr.set(j, t);
}
...
};
有了 siftUp 函数,增加操作就变得很简单了。
template <class T>
class MaxHeap{
public:
...
void add(T num){
arr.addLast(num);
siftUp(arr.size() - 1);
}
...
};
由于底层是动态数组,所以不需要考虑内存方面的问题。
2.2 删除操作
同样,对于最大二叉堆的删除操作,我们也是先从逻辑结构上进行推理,然后利用数组去实现。
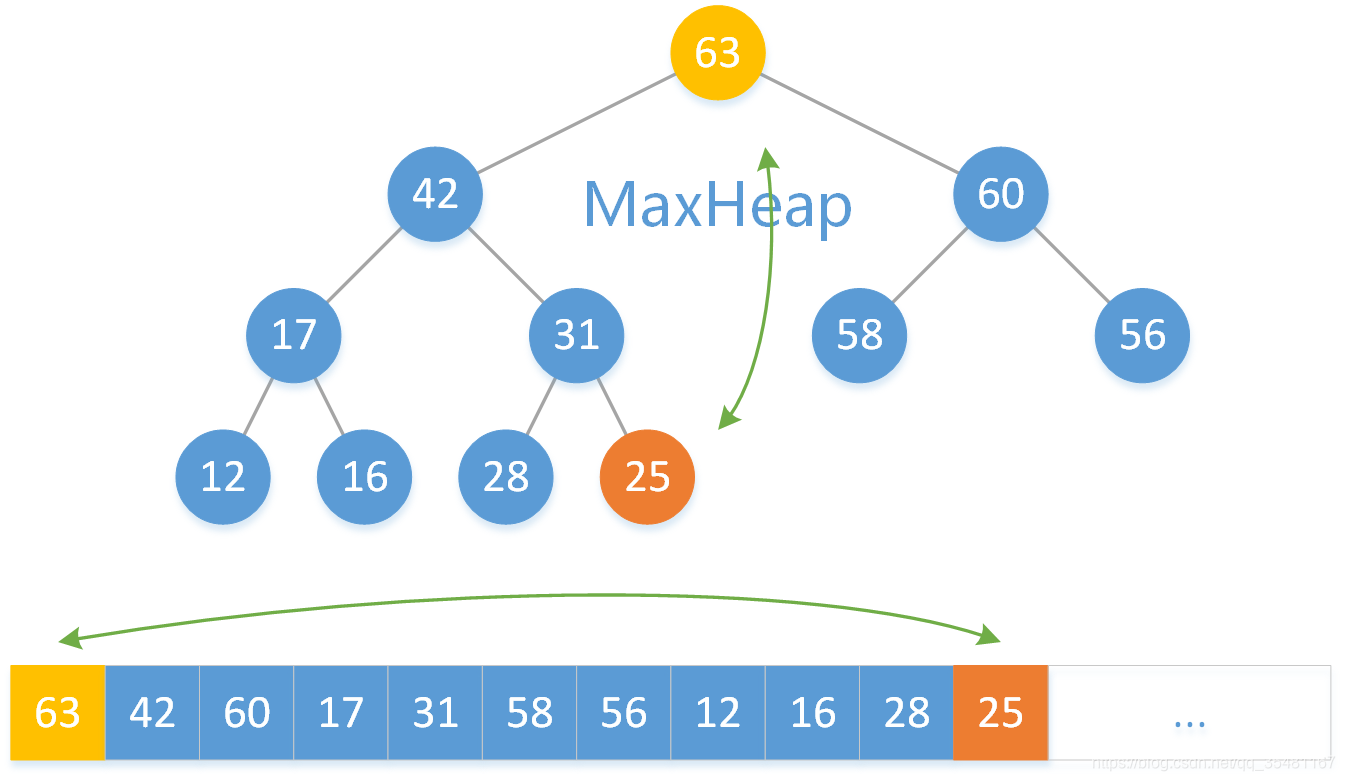
我们要取出最大二叉堆的最大的元素,即根结点元素,而数组操作针对数组末尾操作比较方便,所以现将数组的首尾元素交换。
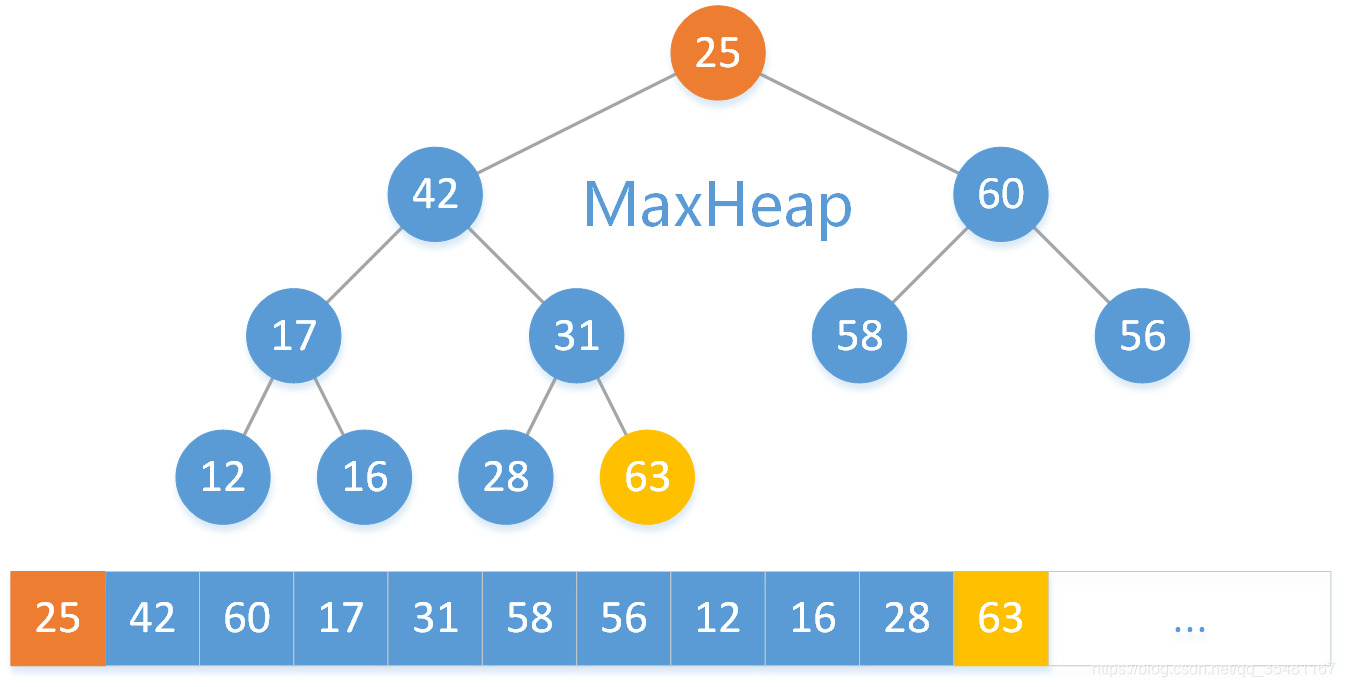
删除掉数组的最后一个元素。
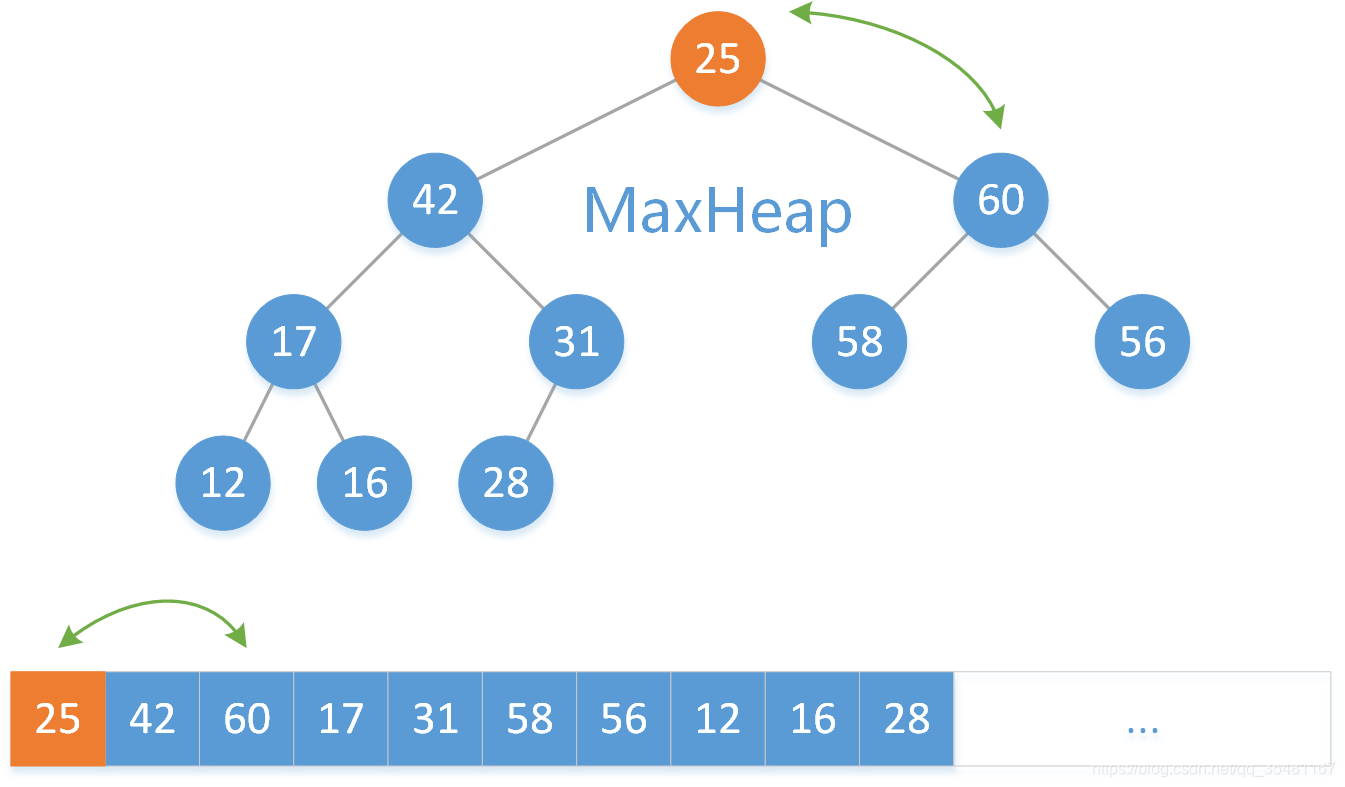
此时根结点是原来数组尾端元素,所以需要判断其位置是否合理。将 25 与其左右子结点元素比较大的那个 60 相比较,25 < 60 ,所以将 25 和 60 交换。
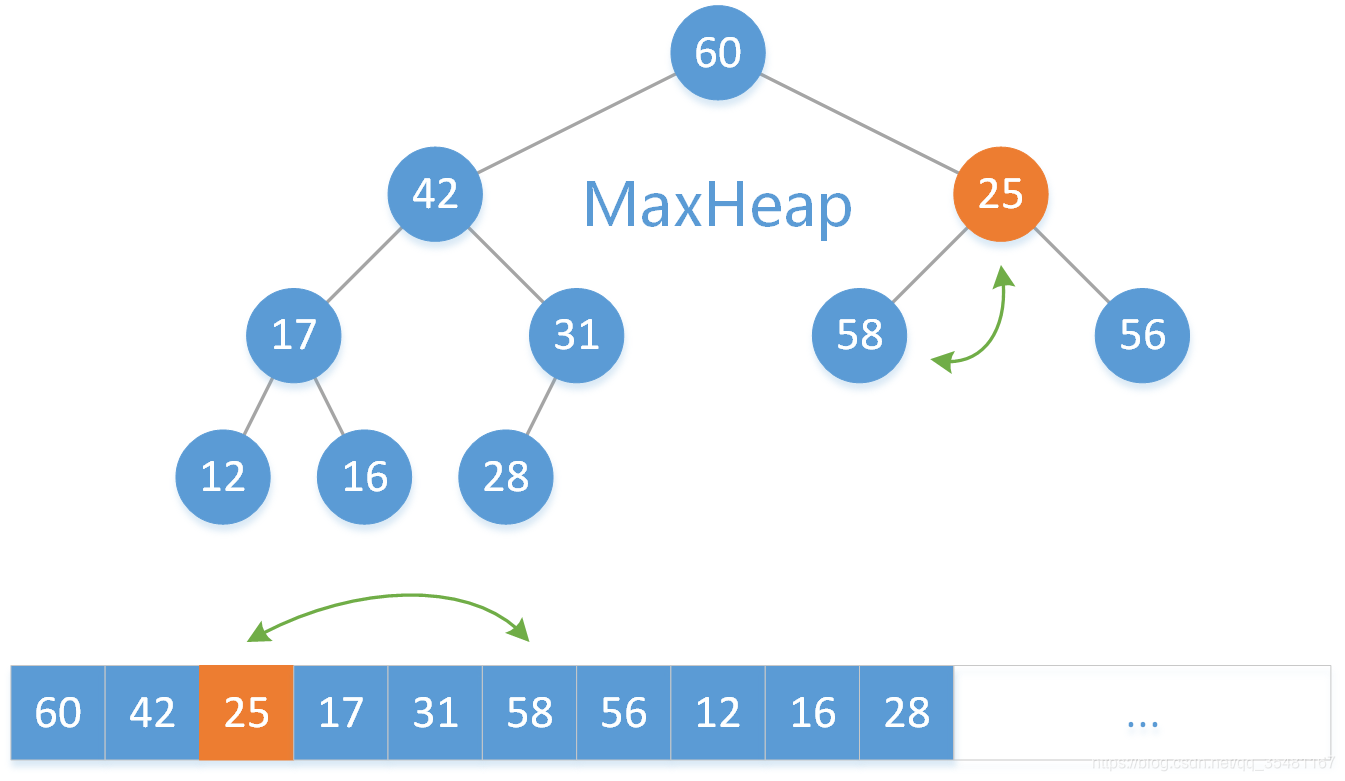
继续把 25 和其左右子结点元素较大的 58 相比,25 < 58 ,所以将 25 和 58 交换。
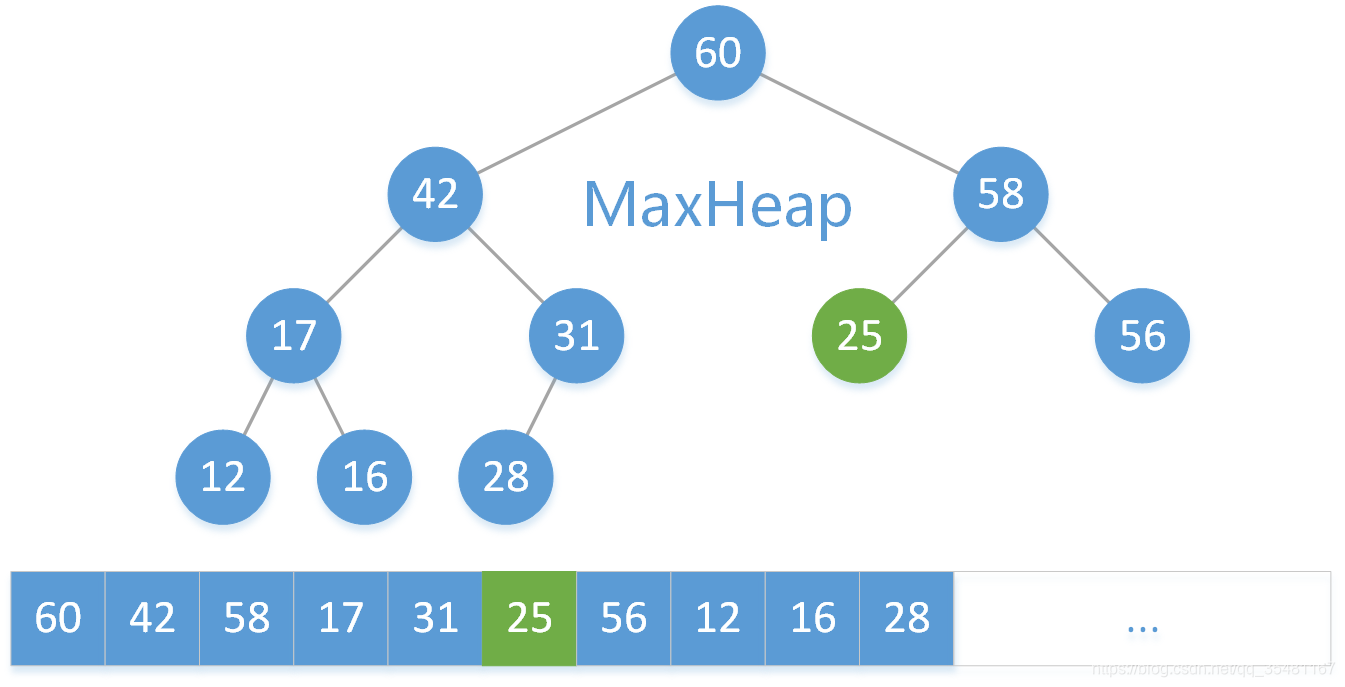
这时,25 的左右子结点均为空,删除操作结束。
与增加操作类似,需要一个逐步交换元素的函数,我们称之为 下沉(siftDown),具体代码如下:
template <class T>
class MaxHeap{
...
private:
...
void siftDown(int index){
while (leftChild(index) < arr.size()){
int left = leftChild(index);
if (left + 1 < arr.size() && arr.get(left + 1) > arr.get(left)){
left++;
}
if (arr.get(index) >= arr.get(left)){
break;
}
swap(index, left);
index = left;
}
}
...
};
相应的删除函数如下:
template <class T>
class MaxHeap{
public:
...
T extractMax(){
T res = findMax();
swap(0, arr.size() - 1);
arr.removeLast();
siftDown(0);
return res;
}
...
};
2.3 查找操作
最大二叉堆的查找比较简单,只能查到根结点(即最大的那个元素)。
template <class T>
class MaxHeap{
...
T findMax(){
if (arr.size() == 0){
cout << "二叉堆为空!" << endl;
return NULL;
}
return arr.get(0);
}
...
};
2.4 其他操作
最大二叉堆还有一些其他的操作,包括 二叉堆大小 等的查询操作。
template <class T>
class MaxHeap{
public:
int size(){
return arr.size();
}
bool isEmpty(){
return arr.isEmpty();
}
...
};
3. 算法复杂度分析
3.1 增加操作
| 函数 | 最坏复杂度 | 平均复杂度 |
|---|---|---|
| add | O(logn) | O(logn) |
add 的最坏复杂度 O(n+n) 中第一个 n 是指元素移动操作,第二个 n 是指 resize 函数,以下同理。
增加可能会引发扩容操作,平均而言,每增加 n 个元素,会扩展一次,会发生 n 个元素的移动,所以平均下来是 O(1) 。
3.2 删除操作
| 函数 | 最坏复杂度 | 平均复杂度 |
|---|---|---|
| extractMax | O(logn) | O(logn) |
同理,删除操作与增加操作类似。
3.3 查找操作
| 函数 | 最坏复杂度 | 平均复杂度 |
|---|---|---|
| findMax | O(1) | O(1) |
总体情况:
| 操作 | 时间复杂度 |
|---|---|
| 增 | O(logn) |
| 删 | O(logn) |
| 查 | O(1) |
由此可以看出,二叉堆操作的时间复杂度相较数组而言更小。
4. 完整代码
最大二叉堆接口函数一览:
| 函数声明 | 函数类型 | 函数功能 |
|---|---|---|
| int size() | public | 返回二叉堆的大小 |
| bool isEmpty() | public | 返回二叉堆是否为空(空返回true) |
| void add(T) | public | 向二叉堆添加元素 |
| T findMax() | public | 返回二叉堆中最大元素 |
| T extractMax() | public | 取出二叉堆最大元素并返回该元素 |
| int parent(int) | private | 返回某索引对应结点父结点索引 |
| int leftChild(int) | private | 返回某索引对应结点左子结点索引 |
| int rightChild(int) | private | 返回某索引对应结点右子结点索引 |
| void swap(int,int) | private | 交换二叉堆中两元素 |
| void siftUp(int) | private | 将二叉堆中某索引元素上浮 |
| void siftDown(int) | private | 将二叉堆中某索引元素下沉 |
程序完整代码(这里使用了头文件的形式来实现类)如下:
注:动态数组 类代码不再赘述,如有需要参见 1.1 。
#ifndef __MAXHEAP_H__
#define __MAXHEAP_H__
#include "Array.h"
template <class T>
class MaxHeap{
public:
int size(){
return arr.size();
}
bool isEmpty(){
return arr.isEmpty();
}
void add(T num){
arr.addLast(num);
siftUp(arr.size() - 1);
}
T findMax(){
if (arr.size() == 0){
cout << "二叉堆为空!" << endl;
return NULL;
}
return arr.get(0);
}
T extractMax(){
T res = findMax();
swap(0, arr.size() - 1);
arr.removeLast();
siftDown(0);
return res;
}
private:
int parent(int index){
if (index <= 0 || index >= arr.size()){
return NULL;
}
return (index - 1) / 2;
}
int leftChild(int index){
return index * 2 + 1;
}
int rightChild(int index){
return (index + 1) * 2;
}
void swap(int i, int j){
if (i < 0 || i >= arr.size() || j < 0 || j >= arr.size()){
return;
}
T t = arr.get(i);
arr.set(i, arr.get(j));
arr.set(j, t);
}
void siftUp(int index){
while (index && arr.get(index) > arr.get(parent(index))){
swap(index, parent(index));
index = parent(index);
}
}
void siftDown(int index){
while (leftChild(index) < arr.size()){
int left = leftChild(index);
if (left + 1 < arr.size() && arr.get(left + 1) > arr.get(left)){
left++;
}
if (arr.get(index) >= arr.get(left)){
break;
}
swap(index, left);
index = left;
}
}
private:
Array<T> arr;
};
#endif