数据结构实现 8.1:字典树(C++版)
1. 概念及基本框架
字典树 顾名思义,就是用来存放单词的树,也称 Trie树 ,其本质上是一种多叉树,我们可以通过图示说明。
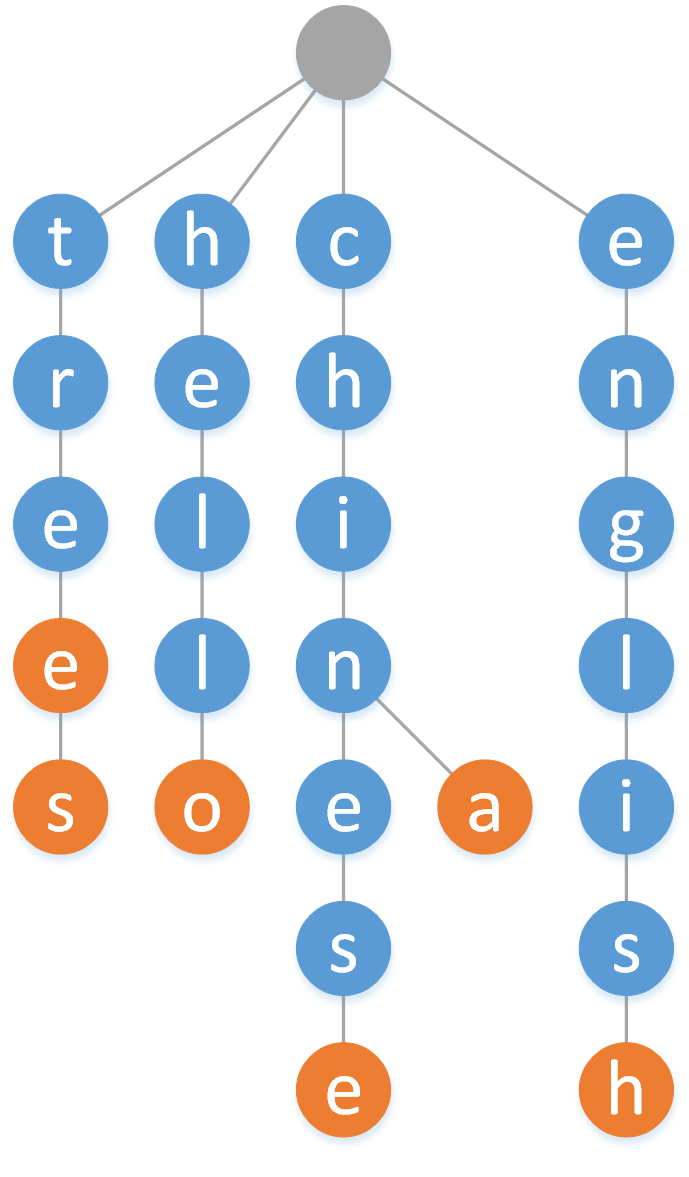
这里有一个灰色的根结点,不存储信息,然后下面的每个结点存储一个字母,利用结点颜色区分从根结点到当前结点构成的字符串是否是一个单词。这样,就可以构成一部字典。很显然,从字典中查找一个单词,与字典 的容量并无关系,而只与单词长度有关。这样只要建立好了字典,那么可以大大减小查找操作的时间复杂度。
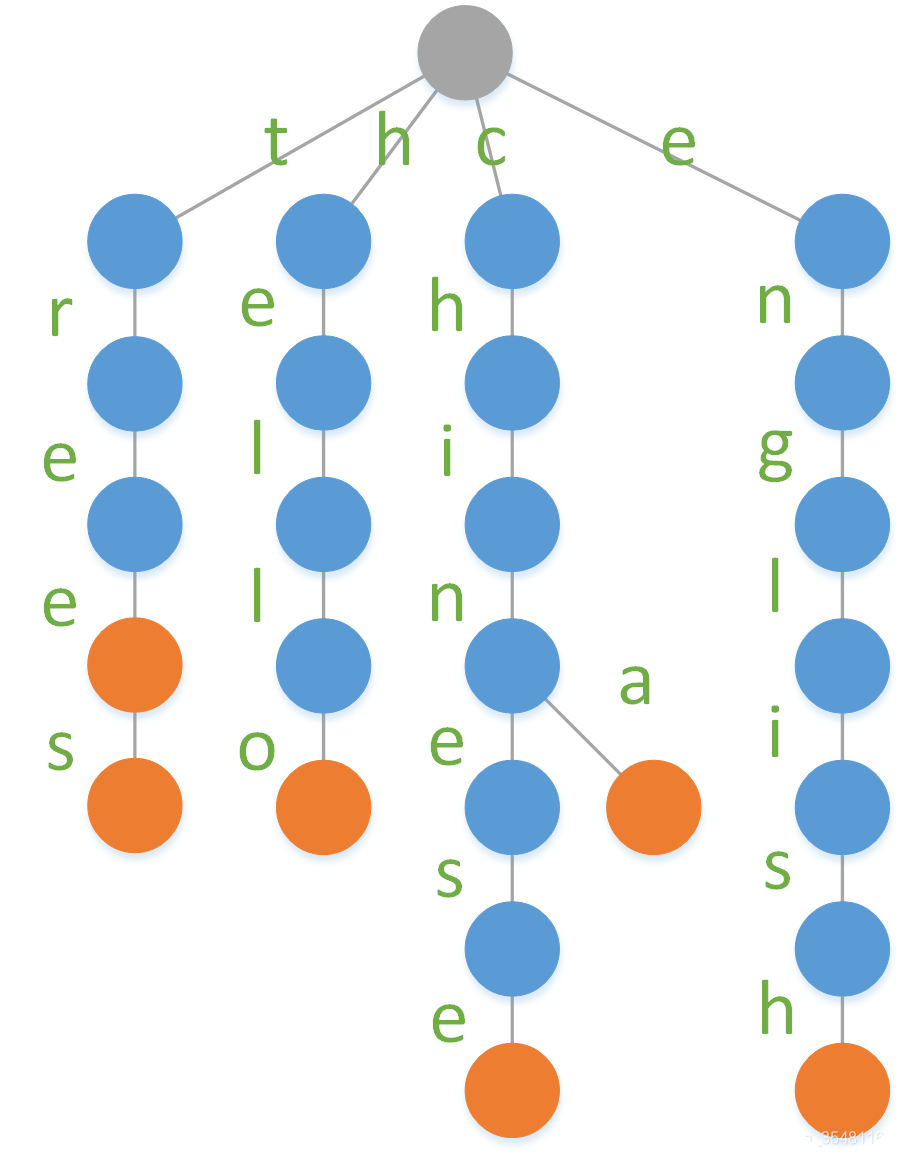
当然,我们也可以把字母存储在路径上,只用结点颜色表示当前结点构成的字符串是否是一个单词。
我们先来定义一个字典树的结点,代码如下:
class TrieNode{
public:
TrieNode(bool isWord = false){
this->isWord = isWord;
BSTMap<char, TrieNode*> *p = new BSTMap<char, TrieNode*>;
next = p;
}
TrieNode operator= (TrieNode& node){
this->isWord = node.isWord;
this->next = node.next;
return *this;
}
public:
bool isWord;
BSTMap<char, TrieNode*> *next;
};
这里使用了我们之前实现的 map 作为结点,其中 key 作为字母,value 用来存储子树。(很显然,每个结点都可以看成一棵多叉树的根)isWord 表示是否是一个单词,初始化默认为 false 。这里对 = 运算符进行了重载,方便我们后面的操作。
有了结点,字典树的大体框架如下:
class Trie{
public:
Trie(){
m_size = 0;
}
...
private:
TrieNode root;
int m_size;
};
root 表示字典树的根,不存储信息。
m_size 表示字典树的大小。
同样,为了保护数据,这些变量都放在 private 区。
接下来我们就对字典树的增加、查询以及一些其他基本操作用代码去实现。
2. 基本操作程序实现
2.1 增加操作
class Trie{
public:
...
void add(std::string word){
TrieNode* cur = &root;
for (int i = 0; i < word.size(); ++i){
char c = word[i];
if (!cur->next->contains(c)){
TrieNode* node = new TrieNode;
cur->next->add(c, node);
}
cur = cur->next->get(c);
}
if (!cur->isWord){
cur->isWord = true;
m_size++;
}
}
...
};
这里添加操作有两个:
第一个是添加字母结点,只有结点不存在才会执行此操作;
第二个是添加新单词,而只有字典中没有当前单词才会记录增加了新单词。
2.2 查找操作
这里我们提供两个查询函数,contains 和 isPrefix ,函数实现代码如下。
class Trie{
public:
...
bool contains(std::string word){
TrieNode* cur = &root;
for (int i = 0; i < word.size(); ++i){
char c = word[i];
if (!cur->next->contains(c)){
return false;
}
cur = cur->next->get(c);
}
return cur->isWord;
}
bool isPrefix(string prefix){
TrieNode *cur = &root;
for (int i = 0; i < prefix.size(); ++i){
char c = prefix[i];
if (!cur->next->contains(c)){
return false;
}
cur = cur->next->get(c);
}
return true;
}
...
};
contains 用于查找字典中是否包含该单词。
isPrefix 用于查找字典中是否包含该前缀串。
2.3 其他操作
字典树还有一些其他的操作,包括 字典树大小 等的查询操作。
class Trie{
public:
...
int size()const{
return m_size;
}
bool isEmpty()const{
return m_size == 0;
}
...
};
3. 算法复杂度分析
因为字典树的增加、查找操作只与单词长度有关,所以时间复杂度均是 O(1) 级别的。
3.1 增加操作
| 函数 | 最坏复杂度 | 平均复杂度 |
|---|---|---|
| add | O(1) | O(1) |
3.2 查找操作
| 函数 | 最坏复杂度 | 平均复杂度 |
|---|---|---|
| contains | O(1) | O(1) |
| isPrefix | O(1) | O(1) |
总体情况:
| 操作 | 时间复杂度 |
|---|---|
| 增 | O(1) |
| 查 | O(1) |
4. 完整代码
程序完整代码(这里使用了头文件的形式来实现类)如下:
这里不再给出 BSTMap 实现代码,如有需要可查看 5.1 。
字典树 类代码:
#ifndef __TRIE_H__
#define __TRIE_H__
#include <string>
#include "BSTMap.h"
class TrieNode{
public:
TrieNode(bool isWord = false){
this->isWord = isWord;
BSTMap<char, TrieNode*> *p = new BSTMap<char, TrieNode*>;
next = p;
}
TrieNode operator= (TrieNode& node){
this->isWord = node.isWord;
this->next = node.next;
return *this;
}
public:
bool isWord;
BSTMap<char, TrieNode*> *next;
};
class Trie{
public:
Trie(){
m_size = 0;
}
int size()const{
return m_size;
}
bool isEmpty()const{
return m_size == 0;
}
void add(std::string word){
TrieNode* cur = &root;
for (int i = 0; i < word.size(); ++i){
char c = word[i];
if (!cur->next->contains(c)){
TrieNode* node = new TrieNode;
cur->next->add(c, node);
}
cur = cur->next->get(c);
}
if (!cur->isWord){
cur->isWord = true;
m_size++;
}
}
bool contains(std::string word){
TrieNode* cur = &root;
for (int i = 0; i < word.size(); ++i){
char c = word[i];
if (!cur->next->contains(c)){
return false;
}
cur = cur->next->get(c);
}
return cur->isWord;
}
bool isPrefix(string prefix){
TrieNode *cur = &root;
for (int i = 0; i < prefix.size(); ++i){
char c = prefix[i];
if (!cur->next->contains(c)){
return false;
}
cur = cur->next->get(c);
}
return true;
}
private:
TrieNode root;
int m_size;
};
#endif