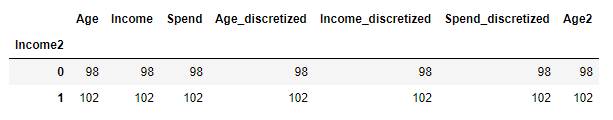版权声明:本文为博主原创文章,如若转载请注明出处 https://blog.csdn.net/tonydz0523/article/details/84555686
何为离散化:
一些数据挖掘算法中,要求数据是分类属性形式。因此常常需要将连续属性的数据通过断点进行划分最后归属到不同的分类,即离散化。
为什么要离散化:
- 调高计算效率
- 分类模型计算需要
- 给予距离计算模型(k均值、协同过滤)中降低异常数据对模型的影响
- 图像处理中的二值化处理
ps:离散化也可以用于已经离散化的数据,就是值域的重新划分,一切都是看业务需要
连续数据离散化方法:
- 分位数法:使用四分位、五分位、十分位等进行离散
- 距离区间法:等距区间或自定义区间进行离散,有点是灵活,保持原有数据分布
- 频率区间法:根据数据的频率分布进行排序,然后按照频率进行离散,好处是数据变为均匀分布,但是会更改原有的数据结构
- 聚类法:使用k-means将样本进行离散处理
- 卡方:通过使用基于卡方的离散方法,找出数据的最佳临近区间并合并,形成较大的区间
- 二值化:数据跟阈值比较,大于阈值设置为某一固定值(例如1),小于设置为另一值(例如0),然后得到一个只拥有两个值域的二值化数据集。
ps:卡方检验就是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,卡方值越大,越不符合;卡方值越小,偏差越小,越趋于符合,若两个值完全相等时,卡方值就为0,表明理论值完全符合。
python实现
import pandas as pd
from sklearn.cluster import KMeans
from sklearn import preprocessing
#######时间序列离散#######
# 创造时间数据
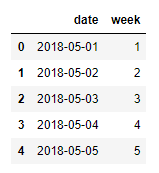
date = pd.date_range('5/1/2018','11/26/2018')
df_t = pd.DataFrame(date, columns=['date'])
# 转化为周
df_t['week'] = df_t['date'].apply(lambda x:x.weekday())
df_t.head()
# 导入数据
df = pd.read_csv('https://raw.githubusercontent.com/ffzs/dataset/master/Mall_Customers.csv', usecols=['Age', 'Annual Income (k$)', 'Spending Score (1-100)'])
# 更改列名
df.columns = ['Age', 'Income', 'Spend']
#######等距离散#######
df['Age_discretized'] = pd.cut(df.Age, 4, labels=range(4))
df.groupby('Age_discretized').count()
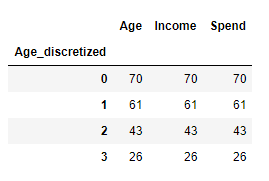
#####使用聚类实现离散化#######
# 数据准备
data = df['Income']
# 改变数据形状
data_re = data.reshape((data.index.size, 1))
# 创建k-means模型并指定聚类数量
km_model = KMeans(n_clusters=4, random_state=2018)
# 模型导入数据
result = km_model.fit_predict(data_re)
# 离散数据并入原数据
df['Income_discretized'] = result
df.groupby('Income_discretized').count()
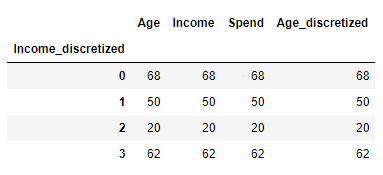
#####使用4分位离散数据#######
df['Spend_discretized'] = pd.qcut(df.Spend, 4, labels=['C', 'B', 'A', 'S'])
df.groupby('Spend_discretized').count()
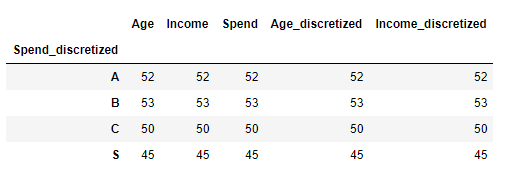
#####等频率离散#######
# 设置离散区间数
k =4
# 获取数据
data = df.Age
# 设置频率范围
w = [1.0*i/k for i in range(k+1)]
# 使用describe获取频率区域的分界点
w = data.describe(percentiles = w)[4:4+k+1]
w[0] = w[0]*(1-1e-10)
# 根据分界点进行数据离散处理
df['Age2'] = pd.cut(data, w, labels = range(k))
df.groupby('Age2').count()
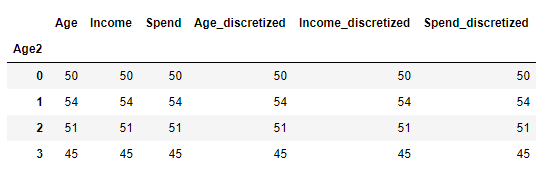
#####数据二值化######
# 建立模型 根据平均值作为阈值
data = df['Income']
binarizer_scaler = preprocessing.Binarizer(threshold=data.mean())
# 二值化处理
result = binarizer_scaler.fit_transform(data.reshape(-1, 1))
# 数据合并
df['Income2'] = result
df.groupby('Income2').count()