目录
一些数据挖掘算法中,特别是某些分类算法(eg:ID3算法、Aprioroi算法等),要求数据是分类属性形式。因此常常需要将连续属性变换成分类属性,即离散化。
离散化就是在数据的取值范围内设定若干个离散的花粉店,将取值范围划分为一些离散化的区间,最后用不同的符号护着整数值代表落在每个区间中的数据值。所以离散化涉及两个过程:确定分类数&将连续属性值映射到n个分类值。
常用的离散化方法:等宽离散、等频离散和聚类离散(一维)。
等宽离散
将属性的值域从最小值到最大值分成具有相同宽度的n个区间,n由数据特点决定,往往是需要有业务经验的人进行评估。
代码实现:
#-*- coding:utf-8 -*-
#数据离散化-等宽离散
import pandas as pd
datafile = u'E:\\pythondata\\hk04.xlsx'
data = pd.read_excel(datafile)
data = data[u'回款金额'].copy()
k = 5 #设置离散之后的数据段为5
#等宽离散
d1 = pd.cut(data,k,labels = range(k))#将回款金额等宽分成k类,命名为0,1,2,3,4,5,data经过cut之后生成了第一列为索引,第二列为当前行的回款金额被划分为0-5的哪一类,属于3这一类的第二列就显示为3
def cluster_plot(d,k):
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize = (12,4))
for j in range(0,k):
plt.plot(data[d==j], [j for i in d[d==j]],'o')
plt.ylim(-0.5, k-0.5)
return plt
cluster_plot(d1, k).show()离散结果:
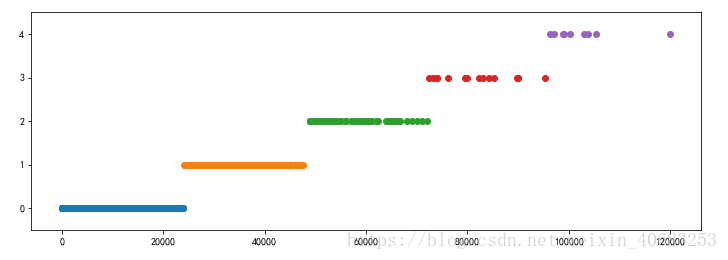
由这个离散结果我们可以直观的看出等宽离散的缺点,其缺点在于对噪点过于敏感,倾向于不均匀的把属性值分布到各个区间,导致有些区间的数值极多,而有些区间极少,严重损坏离散化之后建立的数据模型。
等频离散
将相同数量的记录放在每个区间,保证每个区间的数量基本一致。
代码实现:
#-*- coding:utf-8 -*-
#数据离散化-等频离散
import pandas as pd
datafile = u'E:\\pythondata\\hk04.xlsx'
data = pd.read_excel(datafile)
data = data[u'回款金额'].copy()
k = 5 #设置离散之后的数据段为5
#等频率离散化
w = [1.0*i/k for i in range(k+1)]
w = data.describe(percentiles = w)[4:4+k+1]
w[0] = w[0]*(1-1e-10)
d2 = pd.cut(data, w, labels = range(k))
def cluster_plot(d,k):
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize = (12,4))
for j in range(0,k):
plt.plot(data[d==j], [j for i in d[d==j]],'o')
plt.ylim(-0.5, k-0.5)
return plt
cluster_plot(d2, k).show()
离散结果:

由离散结果看出,等频离散不会像等宽离散一样,出现某些区间极多或者极少的情况。但是根据等频离散的原理,为了保证每个区间的数据一致,很有可能将原本是相同的两个数值却被分进了不同的区间,这对最终模型的损坏程度一点都不亚于等宽离散。
聚类离散
一维聚类离散包括两个过程:通过聚类算法(K-Means算法)将连续属性值进行聚类,处理聚类之后的到的k个簇,得到每个簇对应的分类值(类似这个簇的标记)。
代码实现:
#-*- coding:utf-8 -*-
#数据离散化-聚类离散
import pandas as pd
datafile = u'E:\\pythondata\\hk04.xlsx'
data = pd.read_excel(datafile)
data = data[u'回款金额'].copy()
k = 5 #设置离散之后的数据段为5
#聚类离散
from sklearn.cluster import KMeans
kmodel = KMeans(n_clusters = k, n_jobs = 4)
kmodel.fit(data.reshape((len(data), 1)))
c = pd.DataFrame(kmodel.cluster_centers_, columns=list('a')).sort_values(by='a')
#rolling_mean表示移动平均,即用当前值和前2个数值取平均数,
#由于通过移动平均,会使得第一个数变为空值,因此需要使用.iloc[1:]过滤掉空值。
w = pd.rolling_mean(c, 2).iloc[1:]
w = [0] + list(w[0]) + [data.max()]
d3 = pd.cut(data, w, labels = range(k))
def cluster_plot(d,k):
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize = (12,4))
for j in range(0,k):
plt.plot(data[d==j], [j for i in d[d==j]],'o')
plt.ylim(-0.5, k-0.5)
return plt
cluster_plot(d3, k).show()离散结果:
**********************************************此图忘记保存了,稍后补上!!!*************************************************
三种离散化方法中,最得本宫心意的便是最后这个聚类离散,但是即便是这般如花似玉,也有她的弊端:无法自己学习得知离散后簇的个数,依然需要内阁大学士来决定。