数据预处理是进行数据分析的第一步,如何获取干净的数据是分析效果的前提。
今天学习了几个数据预处理的入门级方法,做笔记啦!工具:python.sklearn
1、行归一化/正则化Normalizer
使每一行的平方和为1,常用于文本分类和聚类中
z=pd.DataFrame({"a":[2.,1.,6.],"b":[3.,0,2.]})
1 from sklearn.preprocessing import Normalizer 2 Normalizer().fit_transform(z) 3 #等价的sklearn函数调用三步 4 a=Normalizer()#函数实例化 5 a.fit(z)#模型拟合 6 a.transform(z)#转换
z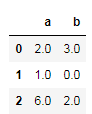 归一化后为
归一化后为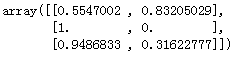
2、列归一化/标准化/无量纲化Standardscaler
该方法要求数据近似为高斯分布,标准化后数据均值为0,方差为1
1 from sklearn.preprocessing import StandardScaler 2 StandardScaler().fit_transform(z)
3、区间缩放/极差变化/无量纲化
将数据映射到[0,1]区间,但新数据加入时,会影响最大/最小值,进而需重新定义,对设计距离度量的机器学习方法不适用
#区间缩放/极差变换/无量纲化 from sklearn.preprocessing import MinMaxScaler MinMaxScaler().fit_transform(z)
4、特征二值化
设定一个阈值,大于阈值的为1,小于等于阈值的为0,。可用于二元分类问题中目标向量的处理
#特征二值化 from sklearn.preprocessing import Binarizer Binarizer(threshold=1).fit_transform(z)#阈值设为1
5、独热编码
分类器常默认数据是连续的有序的,但很多特征是离散的。因此,将所有离散特征的不同取值作为单独一列,1表示离散特征为此列值,0表示离散特征不为此列值
#独热编码 z3=pd.DataFrame({"a":["男","女","男","女"],"b":["大一","大二","大三","大一"]}) from sklearn.preprocessing import OneHotEncoder enc=OneHotEncoder(categories="auto") enc.fit(z3) ans=enc.transform([["男","大一"]]).toarray()#toarray()转化为可显示的数组形式 OneHotEncoder(categories="auto").fit_transform(z3).toarray()
上例,生成["女”,“男”,“大一”,“大三”,“大二”]为列名的4*5的矩阵,
由 
变为
6、缺失值计算
主要是对缺失值的填充
1 z5=pd.DataFrame({"a":[1,5,np.nan],"b":[np.nan,3,5],"c":[1,2,3]}) 2 from sklearn.impute import SimpleImputer 3 SimpleImputer().fit_transform(z5)#默认用均值代替缺失值 4 SimpleImputer(strategy='constant').fit_transform(z5)#参数定义用0来代替缺失值
7、以多项式构建特征
a,b两个特征,则其2次多项式为1,a,b,a^2,b^2,ab
#以多项式构建特征 from sklearn.preprocessing import PolynomialFeatures p1=PolynomialFeatures(degree=2,include_bias=False,interaction_only=False)#产生特征的平方项和交叉项 p2=p1.fit_transform(z) p2_df=pd.DataFrame(p2,columns=p1.get_feature_names())#为p2增加列名 p2_df x0 x1 x0^2 x0 x1 x1^2 0 2.0 3.0 4.0 6.0 9.0 1 1.0 0.0 1.0 0.0 0.0 2 6.0 2.0 36.0 12.0 4.0
figthing!