在B站找的搭建Hadoop的视频,以下是步骤
感觉很简练,有一篇博客讲的更加详细
1.准备好jar包和Hadoop包
兼容情况如下:
hadoop版本>=2.7:要求Java 7(openjdk/oracle)
hadoop版本<=2.6:要求Java 6(openjdk/oracle)
2.上传jar包以及配置环境变量
我的在安装系统时勾选了安装java,通过java -version直接看到1.7.0_45,似乎可以省略这一步
后面发现还是不能省,上传到/usr/local解压之后,在/etc/profile里修改环境变量
在最后面加上两行
export JAVA_HOME=/usr/local/jdk1.8.0_191

export PATH=$PATH:$JAVA_HOME/bin
3.上传Hadoop包并解压
我找同学拷的2.9.1版本,用rz上传到/usr/local/hadoop文件夹 然后tar -xzvf
在centos下使用rz 首先要通过yum安装

网络连接问题
据说这个是因为虚拟机没有连上外网,解决中。
看了无数个虚拟机网络配置的博客,眼花缭乱,还是找不到解决的路子。
终于通过一个博客 用ifconfig看了下,发现没有网卡eth0,参照https://www.imooc.com/qadetail/59155,发现我的eth0中没有IP地址,当执行service network restart会报错fail,猜测可能是dhcp没有自动为她分配,参考他的分配区间192.168.138.128-192.168.138.255之间,用ifconfig eth0 192.168.138.128手动配置了eth0的IP地址,再service network restart就成功联网了!
但是rz下载之后执行,报错waiting to receive...网上说因为没有端到端,所以跳不出图形界面
所以我用bitvise连接虚拟机,ip为刚才设置的,端口号22
4.创建无密码的公钥
原理:NameNode是通过SSH(Secure Shell)来启动和停止各个DataNode上的各种守护进程的。这就必须在节点之间执行指令的时候是不需要输入密码的形式,故我们需要配置SSH运用无密码公钥认证的形式,这样NameNode使用SSH无密码登录并启动DataName进程,同样原理,DataNode上也能使用SSH无密码登录到NameNode。
操作如下:
ssh-keygen -t dsa -P ' ' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
测试:ssh localhost
第一次询问要输入yes,下一次就可以直接输出了

(1)注意:master无密码登录本机已经设置完毕,接下来的事儿是把公钥复制所有的Slave机器上,用scp命令

然后在slave这边执行

![]()
则master可以通过ssh无密码登录slave

(2)配置所有Slave无密码登录Master
和上面同理,把Slave的公钥追加到Master的".ssh"文件夹下的"authorized_keys,不过是调换过来
5.修改主机名和ip
vi /etc/hostname 改为Master或者slave (后面namenode格式化时发现并没有修改成功,可能因为当时我打开 /etc/hostname 这个文件是空的和视频里不同,后来换了种方法更改主机名,即在/etc/sysconfig/network下更改,不过需要重启后才生效,可通过hostname命令查看主机名)
vi /etc/hosts 注释掉原有的,添加上映射,譬如 192.168.50.154 Master (改成自己对应IP)
注意:要进行多项映射,进行这项之后master和slave之间是否可以ping通

6.创建文件夹(之后会用到)
mkdir /usr/local/hadoop/tmp
mkdir -p /usr/local/hadoop/hdfs/name
mkdir -p /usr/local/hadoop/hdfs/data
7.修改环境变量
vi ~/.bash_profile
原有基础上添加三行:
HADOOP_HOME=/usr/local/hadoop/hadoop-2.9.1(自己版本号)
PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_HOME PATH
source ~/.bash_profile 使得环境变量生效
8.配置Hadoop
(1)找到Hadoop etc目录下的Hadoop下的hadoop-env.sh
注释掉里面的export JAVA_HOME=$JAVA_HOME
添上export JAVA_HOME=/usr/local/jdk1.8.0_191 jdk在的目录
通过java -verbose查找位置

后面证明了这个路径是错误的
https://www.cnblogs.com/YatHo/p/7526852.html 重新更换java版本
(2)同一个目录下 yarn-env.sh 同样添上export JAVA_HOME=/usr/local/jdk1.8.0_191 jdk在的目录(在 some Java parameters后面添上就行)
(3)core-site.xml
放入<configuration></configuration>里面(前面不需要空格之类的)
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
在slave中换成了这个,应该是主机名+端口号
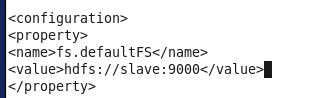
(4)hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value> #设置副本个数
</property>
4)配置mapred-site.xml文件
(如果只有mapred.xml.template文件,可以用 cp mapred-site.xml.template mapred-site.xml进行重命名)
首先在 mapred-site.xml中添加(不用property标签)
<name>mapreduce.framework.name</name>
<value>yarn</value>
然后在yarn-site.xml中添加:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(各处标注的配置文件修改方法不尽相同,我这里是参照视频写的)
9.格式化namenode
进入hadoop 2.9.1的 bin目录下 ./hdfs namenode -format
这里报了错,后来发现是jdk路径问题,找了半天搞不清楚自带的这个jdk路径是哪,故重新装了jdk1.8.0_191,
更改了前面三处java_home的路径
10.启动Hadoop
退出,进入hadoop 2.9.1下的sbin目录中 ./start-all.sh
jps查看是否启动成功,如下图就可以
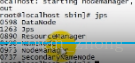

之前只显示jps resoure/node manager三个,把主机名修改成功后,就没有问题啦!
在浏览器中输入192.168.138.130:8080 看是否能访问(ip是前面设的),如果不能,可能是防火墙的问题
注意:
11.查看防火墙状态 firewall -cmd --state
如果显示running的话可以用 systemctl stop firewalld.service关掉防火墙
然后应该就也可以访问了 或者访问192.168.50.154:8080/cluster或者192.168.50.154:50070