参考文章引用来源:
1.GBDT入门教程之原理、所解决的问题、应用场景讲解
2.《统计学习方法》李航
3.GBDT的小结
4.决策树模型组合之随机森林与GBDT
Question1. 首先明确,GBDT是做什么用的??
GBDT (Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就和SVM一起被认为是泛化能力(generalization)较强的算法。近些年更因为被用于搜索排序的机器学习模型而引起大家关注。
(归纳:从大类分,GBDT就是一种回归算法;细化一下,GBDT是迭代的决策树算法;)
Question2. GBDT的整体结构是什么样的??
DT+GB+Shrinkage
GBDT主要由三个概念组成:
[1] Regression Decistion Tree(即DT),
[2] Gradient Boosting(即GB),
[3] Shrinkage (算法的一个重要演进分枝,目前大部分源码都按该版本实现)。
Question3. GBDT在机器学习发展脉络中是从哪个分支出来的??
刚开始在这里迷糊好久,《统计学习方法》倒是看了几遍,但是注意力都在分裂决策树上,完全忘了CART还有回归的用法。。。
我们知道CART全名是Classification and Regression Tree。从来源来说,GBDT背景就是源自这里的RT,即回归决策树。
Question4. 回归决策树是什么??简述一下。



%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
上面是《统计学习方法》关于回归决策树建立的算法描述。(注意这是个二叉决策树!!)
总结起来就是:
【1】首先对于输入的训练数据集,我们知道x是多维度的,不同维度代表不同的特征,那么现在问题就是选择哪个特征作为划分依据?更具体的,选择的这个特征依据哪个值来进行划分?算法的解决方法是:外层遍历所有的特征,内层在外层特征固定的情况下,遍历不同的取值。目标函数定义为MSE,就是当特征j和值s都确定后,数据集可以划分为两个部分,那么这两个部分可以分别计算出y的均值c1和c2。式5.21就是来最小化这个均方误差,以此MSE的值来作为这一层j和s的确定依据。
【2】第一步确定了划分所选特征以及特征值后,相应的划分后的两个部分,各部分的回归预测值就是属于该部分的样本的输出均值。
【3】重复上述步骤,逐层划分,直到满足停止条件,生成决策树。而后预测用法就是:对于输入的x,在经过回归决策树处理后,对应的输出为M个叶子结点(就是划分的M个区域)的加权和。
Question5. GBDT说了什么??
GBDT解决的是方程近似问题,这也是ML的根本问题。就是基于给定输入输出训练数据样本(x,y),得出方程表示输入输出关系y=F(x)的形式。常规的做法就是最小化目标函数(一般是误差函数),通过最小化y和F(x)间的差值,以达到选取最合适的F的目标。对于模型F的选择,**一种很简单的思想是采用“累加表示”的形式,就是一系列函数累加构成。**这种思想是神经网络、SVM、小波等热门技术的核心所在。
一般来说,模型的选择优化问题,是可以转化为参数优化问题的,因为模型由一组参数确定,我们通过最小化误差函数来学习得到这一组参数,这样也就得到了模型的具体形式。(就像下面这样,模型F的表示需要参数P的支持,而P的获取需要基于最小化第2个误差函数)
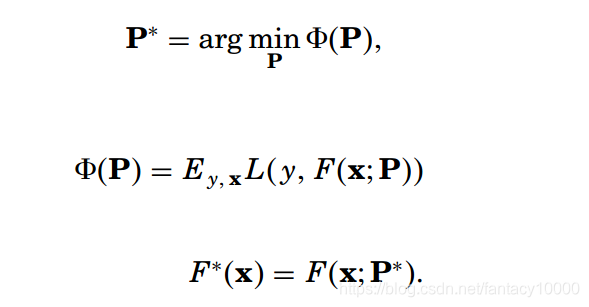
我们说了,对于模型F的选择,一种很简单的思想是采用“累加表示”的形式,就是一组函数累加构成。那么对应的,参数P*也可以由一组P累加得到。
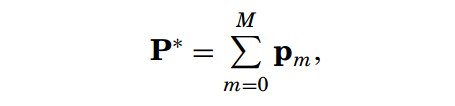
那么现在模型确定的问题就变为了如何确定参数P的累加的问题。
插播一个最速下降法:%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
最速下降法是很常见也很熟悉的,首先可以计算损失函数对于参数P的倒数,由于P是多维向量(j):
因此对P的倒数表示如下:
那么求完导数后,相当于确定了负梯度方向,我们知道还要确定一下步长,才能进行更新,考虑到P的累加表示为:
下一阶段要累加的部分pm为:
对于步长rou的确定,采用“线性搜索”即可获得。线性搜索这个叫法来自:
当Pm-1,gm都已知后,对rou的计算就相当于对rou的线性函数。
rou确定后,就得到了P的更新方法,进而得到了模型F的表示。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
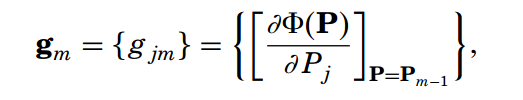

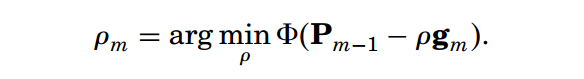
好了,基于上面的最速下降法,可以获得参数的更新方法。现在我们将这一方法应用到函数空间。什么叫应用到函数空间呢?就是说在下面函数中,F(x)可以视为函数的参数。
我们知道,对于模型F,来一个输入x,就会有一个输出F(x)。那么如果把F(x)视为参数的话,那么这个参数是无限的,而考虑到实际应用场景,无论是训练集还是测试集都是有限数据组成的集合,因此F(x)也是有限的。
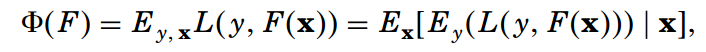
在这种情况下,参数F(x)就相当于上面最速下降法里的P啊!!我们说P是可以基于累加思想表示的,那么同样的F也是可以通过累加思想表示的,所以有:
那么直接搬用前面最速下降法的流程就有了:
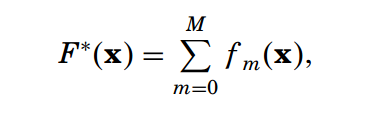
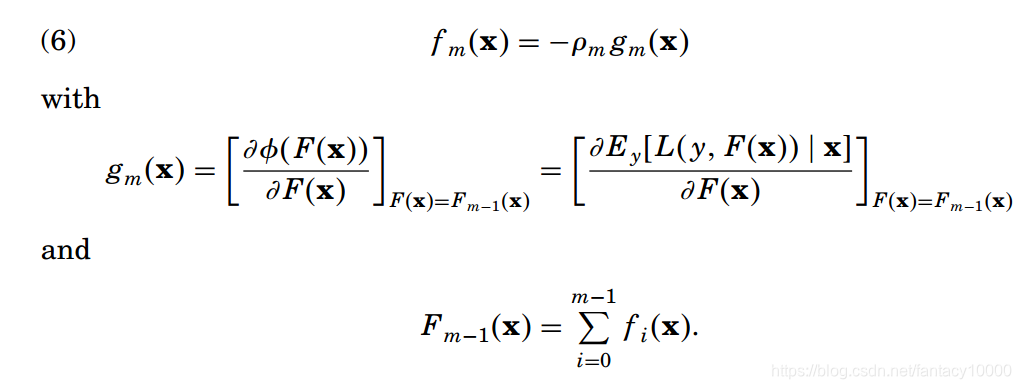
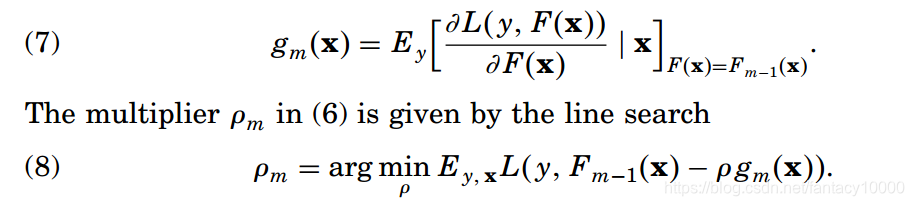
到这里好像问题已经可以解决了,但是这是考虑数据集无穷时的情况。我们知道,实际场景的训练集是有限的,这造成什么后果?看上面式(7),这个梯度值是基于期望得到的,而期望的求取是基于统计原理,有限的数据集是不能支撑这一求取的。因此上面这一流程在实际场景是用不了的。
那么怎么改呢?为了还能使用梯度下降方法,我们需要借助邻近点来增强解的平滑性。具体实现这一思想的方式如下:
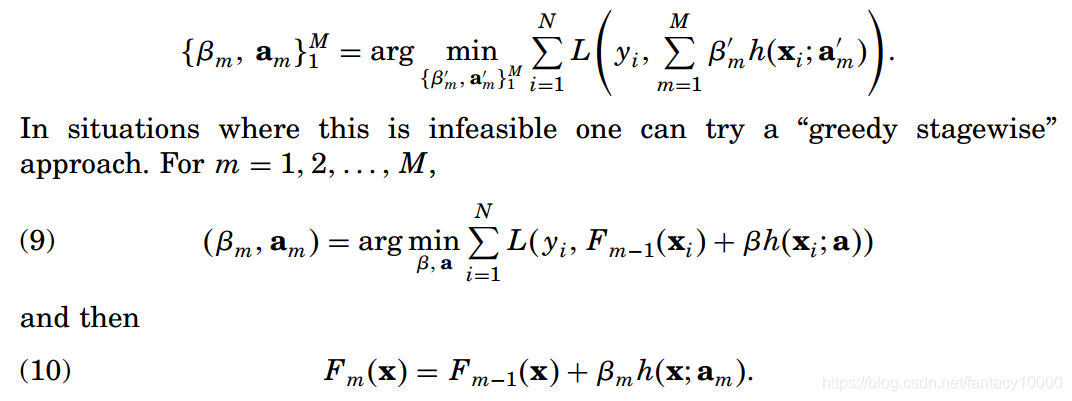
总结这一做法,就是:基于累加的形式表示模型(公式(10)),这种表示区别于另一种“在加入新模型后,对此前整体模型都进行调整”,而是仅对新加入的模型m进行加权操作。这种被称为Boosting的方法广泛应用于机器学习领域,其中h就是一个弱学习器,如回归树。
基于这种boosting思想,(10)式可以视为最佳贪婪朝向基于数据估计的最佳F模型(这是很显然的,因为梯度方向是最速更新方向,选择梯度方向是合理的)
既然方法确定了,那么求解流程和最速梯度下降基本一致:

模型累加形式由上式表示,(11)式计算模型参数,(12)式计算最优步长。
**为什么用(11)式来计算模型参数??**我们知道梯度g是基于N个训练数据样本得到的,从误差函数L的角度考虑,第m轮决策树h的选择,指导原则是当模型F累加上h后,所造成的误差(即L的值)能够尽可能进一步减小。这一指导原则得出了负梯度的值(梯度是最速方向嘛,下降最多),那么当我们确定h的参数时,就是为了尽可能使h符合L的负梯度的方向,这样才能使得L进一步减小(也就是说h学习的是前面m-1轮的残差!!目的是进一步拟合这个残差,使得残差尽可能趋于0(当然也可以说h学习的是前面m-1轮残差的梯度下降方向,两者意思是一样的,因为都是为了进一步降低残差值,使得模型F更好的拟合数据)),就相当于下式:
而下式的负梯度方向g已经求得,因此h是要尽可能和这个负梯度同向的,这样才能符合上式。
我们知道h也是一个学习器,就是说h也是学出来的,因此h的学习目标就是上式的负梯度方向,公式表示就是公式(11)。
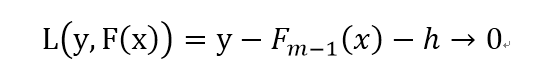
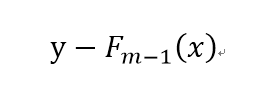
我们总结一下算法:
1.梯度版本(上面是按这种思想解释的)

2.残差版本

总结起来就是:学习负梯度or拟合上一轮残差(代表两种思想,两个版本,意思是一样的)
两个版本的GBDT
目前GBDT有两个不同的描述版本,网上写GBDT的大都没有说清楚自己说的是哪个版本,以及不同版本之间的不同是什么,读者看不同的介绍会得到不同的算法描述,实在让人很头痛。
残差版本把GBDT说成一个残差迭代树,认为每一棵回归树都在学习前N-1棵树的残差,前面所说的主要在描述这一版本。
梯度版本把GBDT说成一个梯度迭代树,使用梯度下降法求解,认为每一棵回归树在学习前N-1棵树的梯度下降值。
读完greedy function approximation :a gradient boosting machine.后,发现4.1-4.4写的是残差版本的GBDT,这一个版本主要用来回归;4.5-4.6写的是Gradient版本,它在残差版本的GBDT版本上做了Logistic变换,Gradient版本主要是用来分类的。
Question6. 关于正则化
正则化是针对过拟合问题的常规手段,通过约束拟合过程来抑制过拟合发生。具体操作可以直接控制M的值,也就是模型组成中学习器的个数。而对于最优M值的确定,需要通过某些模型选择方法(如试触或者交叉验证等)
后期研究发现,通过收缩(Shrinkage)操作的正则化比通过限制组件数量M获得的结果更好。(具体针对算法1中的line 6,相当于控制学习率)
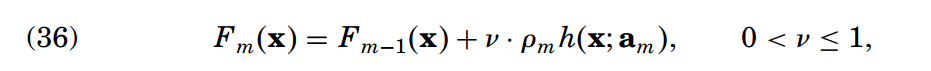
论文中对v和M的值的关系进行了实验分析,结论是:
【1】较小的v效果更好;
【2】v越小使得M越大,并且能够产生越高的精确度(这是显然的,因为v越小,说明单棵回归树起到的作用越有限,因而需要越多的回归树共同作用以保证性能)
这种收缩相较于下面在整体模型上的收缩,效果要好。
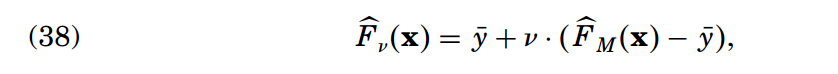
其他方法:
使用缩减训练集
Friedman提出在每次迭代时对base learner从原始训练集中随机抽取一部分(a subsample of the training set drawn at random without replacement)作为本次base learner去拟合的样本集可以提高算法最后的准确率。
限制叶节点中样本的数目
这个在决策树中已经提到过。
剪枝
这个在决策树中已经提到过。
限制每颗树的深度
树的深度一般取的比较小,需要根据实际情况来定。