参考文献引用来源:
1.XGBoost论文翻译和理解
2.CART,回归树,GBDT,XGBoost,LightGBM一路理解过来
Question1. 从论文本身表述看,xgboost有哪些工作点?
【1】设计和构建高度可扩展的端到端提升树系统。
【2】提出了一个理论上合理的加权分位数略图。 这个东西就是推荐分割点的时候用,能不用遍历所有的点,只用部分点就行,近似地表示,省时间。
【3】引入了一种新颖的稀疏感知算法用于并行树学习。 令缺失值有默认方向。
【4】提出了一个有效的用于核外树形学习的缓存感知块结构。 用缓存加速寻找排序后被打乱的索引的列数据的过程。
除了这些主要的贡献之外,还提出了一个改进正则化学习的方法。
Question2. 相较于GBDT,xgboost在算法层面的改进点有哪些?
【1】改进残差函数,不用Gini作为残差,用二阶泰勒展开+树的复杂度(正则项)
带来如下好处:
1.可以控制树的复杂度
2.带有关于梯度的更多信息,获得了二阶导数
3.可以用线性分类器
【2】采用预排序
因为每一次迭代中,都要生成一个决策树,而这个决策树是残差的决策树,所以传统的不能并行
但是陈天奇注意到,每次建立决策树,在分裂节点的时候,比如选中A特征,就要对A进行排序,再计算残差,这个花很多时间。于是陈天奇想到,每一次残差计算好之后,全部维度预先排序,并且此排序是可以并行的,并行排序好后,对每一个维度,计算一次最佳分裂点,求出对应的残差增益,于是只要不断选择最好的残差作为分裂点就可以。也就是说,虽然森林的建立是串行的没有变,但是每一颗树枝的建立就变成是并行的了,带来的好处:
1.分裂点的计算可并行了,不需要等到一个特征的算完再下一个了
2.每层可以并行:
当分裂点的计算可以并行,对每一层,比如分裂了左儿子和右儿子,那么这两个儿子上分裂哪个特征及其增益也计算好了
【3】Shrinkage(缩减)
相当于学习速率(XGBoost中的eta)。XGBoost在进行完一次迭代时,会将叶子节点的权值乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。(GBDT也有学习速率)
【4】列抽样
XGBoost借鉴了随机森林的做法,支持列抽样,不仅防止过 拟合,还能减少计算。
Question3. xgboost说了什么?
首先我们知道,在gbdt中,针对的是损失函数进行的梯度计算,在xgboost中,就是对误差函数进行了泰勒二阶展开,并且添加了正则化项。
(上面最后一个公式变换是相当于从样本视角转入回归树视角,需要想清楚)

关于上面公式中的参数介绍:
数据集是n*m的,就是有n个数据,每个数据有m维特征;
F就是组合成的回归树模型,共k棵树组成了F;
每棵树fk有T片叶子,gamma是这一项的系数,lambda是所有叶子节点的权值的L2正则之和的系数。当正则项系数为0时,整体的目标就退化为了GBDT;
g为一阶导,h为二阶导,q是树的结构;
关于这个二阶泰勒展开形成的目标公式,陈天奇的解释:
他说:这个目标函数有一个很明显的特点,那就是只依赖于每个数据点的在目标函数上的一阶和二阶导数,有人可能会问,这个材料似乎比我们之前学过的决策树学习难懂。为什么要花这么多力气来做推导呢?因为这样做使得我们可以很清楚地理解整个目标是什么,并且一步一步推导出如何进行树的学习。这一个抽象的形式对于实现机器学习工具也是非常有帮助的。传统的GBDT可能大家可以理解如优化平法残差,但是这样一个形式包含可所有可以求导的目标函数。也就是说有了这个形式,我们写出来的代码可以用来求解包括回归,分类和排序的各种问题,正式的推导可以使得机器学习的工具更加一般。
在推出上面公式后,针对其中叶子j的权重参数wj的计算,可基于下式(5):
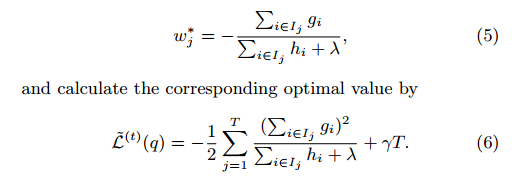
而(6)式可以视为一种不纯度得分函数,用于衡量树结构的合理性。我们知道,树结构对应的具体就是各特征的分割点的确定。很显然不可能去计算所有的树结构。直观上,一种简单的贪婪方法就是从一个单叶子开始,迭代计算并添加分支到树中。具体操作方面,我们令IL为分支左边里的样本集合,IR为分支右边里的样本集合。这样的话,损失函数就可以表示为下式所示,这种形式经常用于候选分割点的计算:
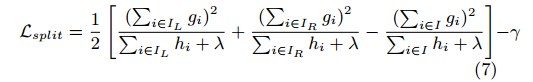
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
上面损失函数算是改进完了。我们知道在学习过程中存在过拟合问题,相应的有两种抑制过拟合的技术:
1.就是GBDT里讲到的Shrinkage技术。简单来说就是对于本轮新加入的树模型,调低权值eta能减少个体的影响,给后续的模型更多学习空间。
2.就是列的重采样技术(column subsampling)。根据一些使用者反馈,列的subsampling比行的subsampling效果好,列的subsampling也加速了并行化的特征筛选。这里应该就跟RF差不多吧,不过论文没说具体怎么column subsampling,API里有个参数能控制subsampe的比例。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
好了,现在来看xgboost核心的分割点选取算法。分割点选取算法正是xgboost算法速度较快的原因之一。
上面公式(5-7)介绍了分割点的衡量标准,直观上可以采用穷举的方法来暴力搜索最优分割点,如下所示:
但是很显然这种方法是很耗时的,而且当数据量过大时,内存方面会承受巨大压力或者完全运行不了,因此为了进行有效可行的分割点选取,需要提出一种近似算法,如下所示:
总的来说,这一算法所做的是:
1.首先基于特征分布的百分比,挑出候选的分割点;
2.而后基于这些分割点,将连续的特征值划分到区间桶内,而后基于汇总的统计数据来确定最优的分割点;
(感觉和采样的思路很像??就是缩小候选集范围)


这里有两种proposal的方式,一种是global的,一种是local的。
【1】global的是在建树之前就做proposal然后之后每次分割都要更新一下proposal;
【2】local的方法是在每次split之后更新proposal。
通常发现local的方法需要更少的candidate,而global的方法在有足够的candidate的时候效果跟local差不多。我们的系统能充分支持exact greedy跑在单台机器或多台机器上,也支持这个proposal的近似算法,并且都能设定global还是local的proposal方式(这个算法的参数我没有在一般的API里看到,可能做超大型数据的时候才会用这个吧,因为前者虽然费时间但是更准确,通常我们跑的小数据用exact greedy就行)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
这里算法在研究特征分布然后做候选分裂点集合提取的时候,用到了加权分位数略图(weighted quantile sketch),原文说不加权的分位数略图有不少了,但是支持加权的以前没人做。
基本思路是用到了百分位这一概念,针对第k个特征,利用其二阶导数值定义了一个排列函数:
(这里需要再消化一下)
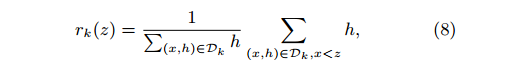

%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
在实际使用中,考虑到输入数据的稀疏表示的现象,使算法能够意识到数据的稀疏模式是很重要的。因此在文中提出在每个树节点中添加一个默认方向,作为值缺失时,能够直接使用的方向。一个值是缺失值时,我们就把他分类到默认方向,每个分支有两个选择,具体应该选哪个?这里提出一个算法,枚举向左和向右的情况,哪个gain大选哪个:

Question4. XGBoost在系统层面做了哪些优化?
这里XGB将所有的列数据都预先排了序。
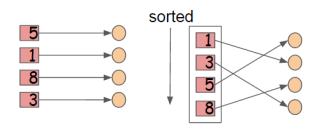
以压缩形式分别存到block里,不同的block可以分布式存储,甚至存到硬盘里。在特征选择的时候,可以并行的处理这些列数据,XGB就是在这实现的并行化,用多线程来实现加速。同时这里陈博士还用cache加了一个底层优化:
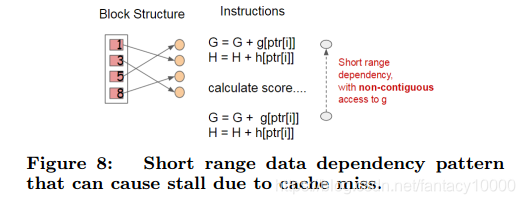
当数据排序后,索引值是乱序的,可能指向了不同的内存地址,找的时候数据是不连续的,这里加了个缓存,让以后找的时候能找到小批量的连续地址,以实现加速!这里是在每个线程里申请了一个internal buffer来实现的!这个优化在小数据下看不出来,数据越多越明显。
一些其他点:
实验数据里提到column subsampling表现不太稳定,有时候sub比不sub要好,有时候sub要好,什么时候该用subsampling呢?当没有重要的特征要选,每个特征值的重要性都很平均的时候,对列的subsampling效果就比较差了。