手写数字识别这个例子是学tensorflow必经的小练习喔
话不多说来个正确率的图,测试集正确率96%

啥?看着不好看?没看到过程?莫急,看下图,tensorboard可视化,多帅喔。
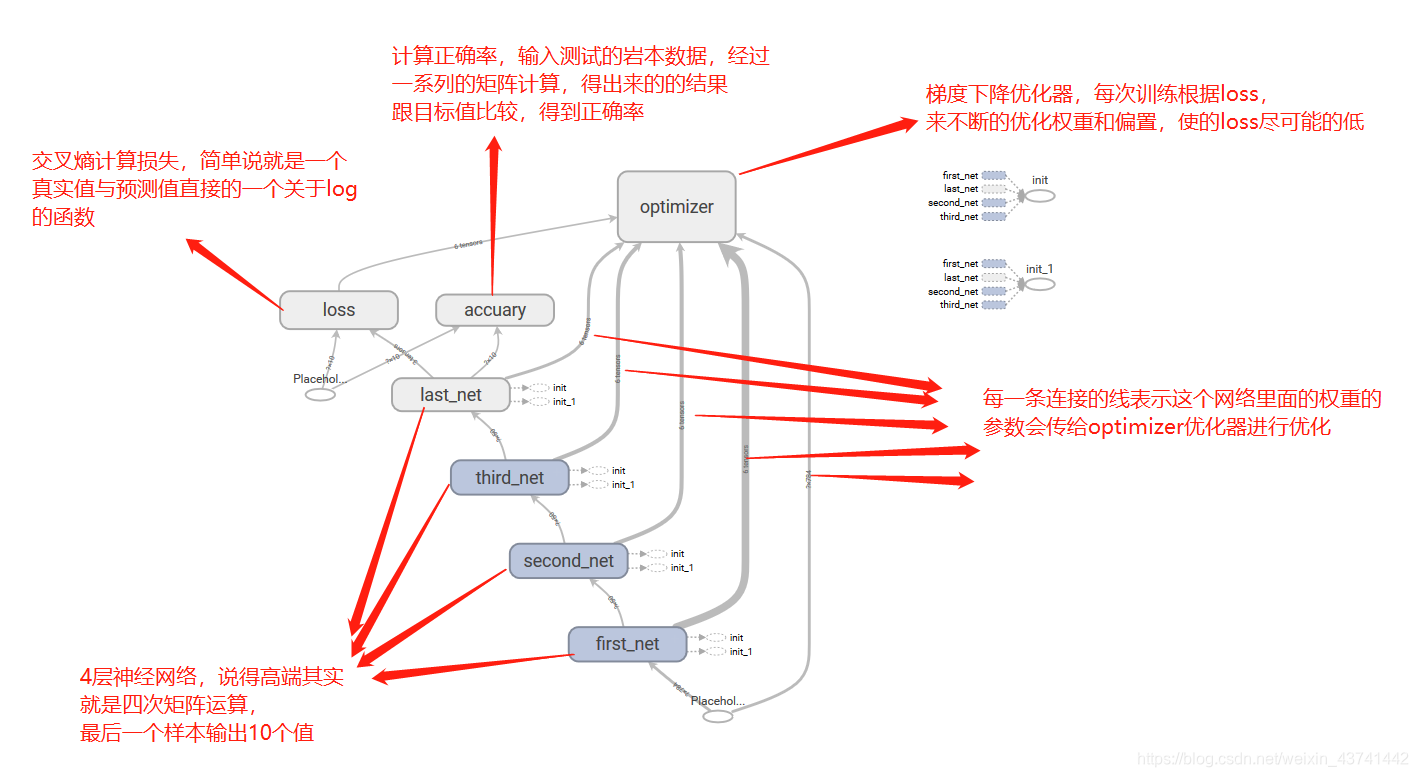
这是网络的结构图
训练过程中的数据的变化
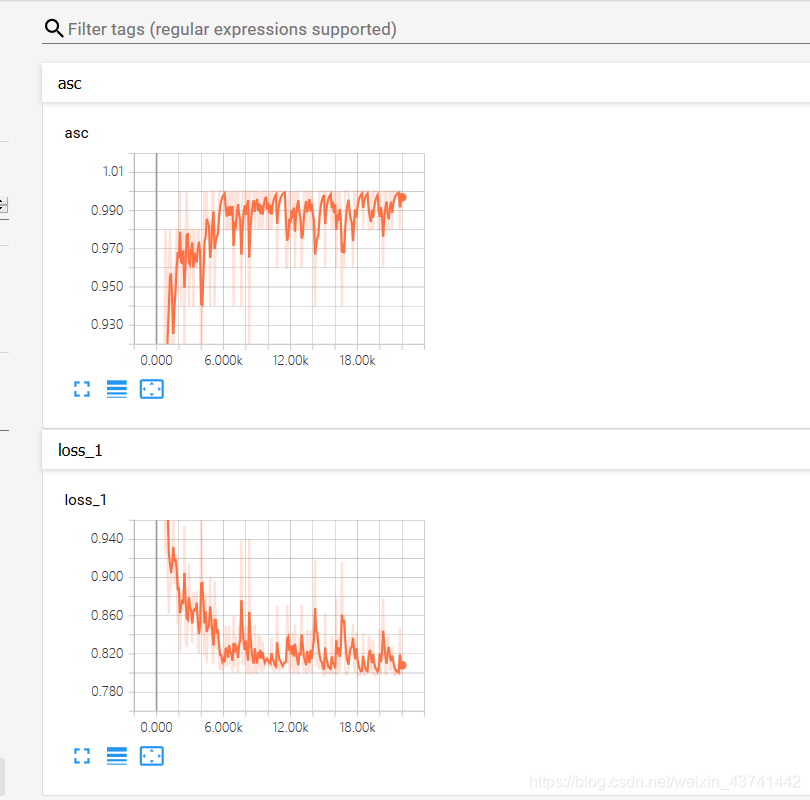
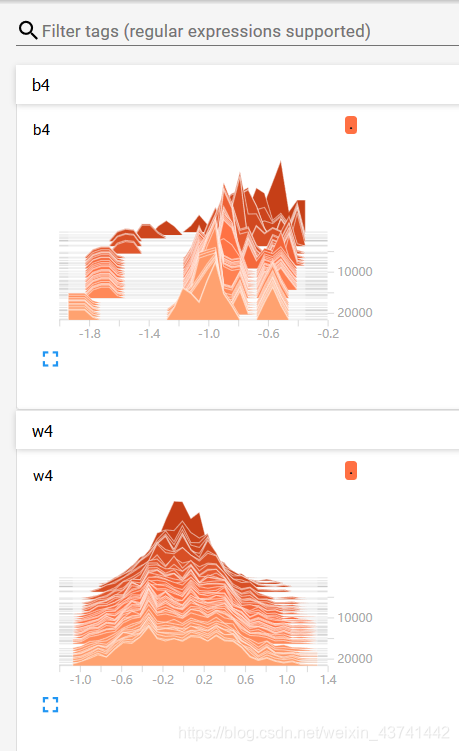
图中可以看到asc(正确率)在随着训练不断的上升,loss损失值也在不断的下降,其中用到的
下面是code部分,大部分内容可以看代码
创建一个简单的神经网络
# 这里所说的神经网络就是一些矩阵相乘,还要偏置的相加,最后保证输出10个值,因为手写数字只有10个类别
# 可以自行改一下里面中间层的神经元个数之类的,不过要注意确保可以矩阵相乘的条件
# 里面你可以加一层,两层也可以的,注意输出矩阵的格式呀求就好
# 就好比如:输入的为[None, 784], 因为图片有784个像素,也就是有784个特征,
#所以第一层的权重必须是是 [784, 神经元的个数],偏置则是跟神经元个数一样就行了。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("../../tensorflow_code/mnist/", one_hot=True)
batch_size = 50
n_batch = mnist.train.num_examples // batch_size
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
with tf.variable_scope("first_net"):
W1 = tf.Variable(tf.random_normal([784, 50], stddev=0.1))
b1 = tf.Variable(tf.zeros([50]))
prediction1 = tf.nn.tanh(tf.matmul(x, W1) + b1)
L1_drop = prediction1
with tf.variable_scope("second_net"):
W2 = tf.Variable(tf.random_normal([50, 50], stddev=0.1))
b2 = tf.Variable(tf.zeros([50]))
prediction2 = tf.nn.tanh(tf.matmul(L1_drop, W2) + b2)
L2_drop = prediction2
with tf.variable_scope("third_net"):
W3 = tf.Variable(tf.random_normal([50, 50], stddev=0.1))
b3 = tf.Variable(tf.zeros([50]))
prediction3 = tf.nn.tanh(tf.matmul(L2_drop, W3) + b3)
L3_drop = prediction3
with tf.variable_scope("last_net"):
W4 = tf.Variable(tf.zeros([50, 10]))
b4 = tf.Variable(tf.zeros([10]))
prediction = tf.nn.tanh(tf.matmul(L3_drop, W4) + b4)
with tf.variable_scope("loss"):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
with tf.variable_scope("optimizer"):
train_step = tf.train.GradientDescentOptimizer(0.15).minimize(loss)
init = tf.global_variables_initializer()
with tf.variable_scope("accuary"):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar("loss", loss)
tf.summary.scalar("asc", accuracy)
tf.summary.histogram("w4", W4)
tf.summary.histogram("b4", b4)
init_op = tf.global_variables_initializer()
merge = tf.summary.merge_all()
with tf.Session() as sess:
sess.run(init)
filewriter = tf.summary.FileWriter("./model/", graph=sess.graph)
i += 1
for epoch in range(20):
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={x: batch_xs, y: batch_ys})
if i % 100 == 0:
summary = sess.run(merge, feed_dict={x: batch_xs, y: batch_ys})
filewriter.add_summary(summary, i)
test_acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
train_acc = sess.run(accuracy, feed_dict={x: mnist.train.images, y: mnist.train.labels})
print("Iter " + str(epoch) + ",Testing Accuracy " + str(test_acc) + ",Training Accuracy " + str(train_acc))
小结: 这次分享的主要是比较基础的手写数字的识别,写得可能不是很详细,不过可以自行看下注释,以及自己修改一些参数可以帮助理解,对于tensorboard不能显示出图的问题,会在我的另一篇博客中提到,欢迎多多指教。