2.1.get方式获取单页面数据
eg:如我们想获取中国旅游网站的首页所有的标题和链接
方法1:get方式
pip install requests #安装requests库
import requests #加载库
url='http://www.cntour.cn/' #以中国旅游网站为例
strhtml=requests.get(url) #此时strhtml只是一个url对象
print(strhtml.text) #strhtml.text表示网页源码
以上只是简单抓到了网页源码,接下来要从源码中找到并提取数据。即解析源码。
我们使用Beautiful Soup解析网页。Beautiful Soup在bs4库中,所以我们首先要安装bs4库。
pip install bs4
from bs4 import BeautifulSoup #从bs4库中导入BeautifulSoup
url='http://www.cntour.cn'
strhtml=requests.get(url)
soup=BeautifulSoup(strhtml.text,'lxml') #lxml解析网页文档
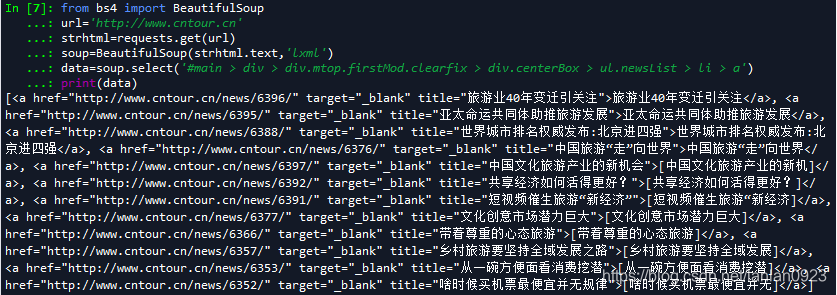
data=soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a') #获取数据路径,下面有补充说明
print(data)
跑出结果:
对获取数据路径的补充说明:
打开我们想要抓取数据的网址,上述代码是中国旅游网站http://www.cntour.cn,然后点击中间任意一个醒目的大标题>然后右键>检查。会出现开发者界面,然后点击左侧高亮部分>右键>【copy】>【copy Selector】
这里补充一下:(因为对网页结构啥的,我其实也不是很懂),所以我们把每一种copy出来的东西对比一下,看看到底是个什么鬼。
1.【copy outerHTML】<a target="_blank" href="http://www.cntour.cn/news/6396/" title="旅游业40年变迁引关注">旅游业40年变迁引关注</a>
2.【copy selector 】#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a
3.【copy Xpath】://*[@id="main"]/div/div[4]/div[2]/ul[1]/li[1]/a
4.【cut element】:<a target="_blank" href="http://www.cntour.cn/news/6396/" title="旅游业40年变迁引关注">旅游业40年变迁引关注</a>
5.【copy element】:<a target="_blank" href="http://www.cntour.cn/news/6396/" title="旅游业40年变迁引关注">旅游业40年变迁引关注</a>
嗯,果然,这样一看,好像稍微懂了一点。
此时得到的路径应该是长这样:
#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a
将 li:nth-child(1) 冒号及后面部分删掉,得到
#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a
注意:
删除的时候一定要注意在每一个“>”符号前后都有一个空格,不然待会会报错。
至此,我们已经获得中国旅游网站首页的所有标题和链接信息。但是结果中
还有很多html的语言,我们需要删除这部分冗余的信息,对结果做个简单的清洗。
首先明确我们要爬的内容:标题+链接。在简单了解html网页结构后,我们知道,标题在标签中,提取该标签文字用get_text()方法;链接在标签的herf属性中,提取该部分用get(‘herf’)。
for item in data: #soup匹配到的有多个数据,用for循环取出
result={
'title':item.get_text(),
'link':item.get('href'),
}
print (result)
最后得到结果如下: