“大数据”这一术语从2008年开始在科技领域中出现,随之引起学术界的广泛研究兴趣。《Nature》与《Science》杂志分别出版专刊,从互联网技术、互联网经济学、超级计算、环境科学、生物医药等多个方面讨论大数据处理和应用专题。世界各国政府也高度重视大数据领域的研究和探索,并从国家战略的层面推出研究规划以应对其带来的挑战。
大数据作为互联网、物联网、移动计算、云计算之后IT产业又一次颠覆性的技术变革,正在重新定义社会管理与国家战略决策、企业管理决策、组织业务流程、个人决策的过程和方式。随着科技和社会的发展进步加上计算机和网络技术的兴起,社交网络、物联网、云计算以及多种传感器的广泛应用,使数量庞大,种类众多,时效性强为特征的数据的不断涌现,引发了数据规模的爆炸式增长。
国际数据公司(International Data Corporation,IDC)研究报告称:2011 年全球被创建和被复制的数据总量超过1. 8ZB,且增长趋势遵循新摩尔定律(全球数据量大约每两年翻一番),预计 2020 年将达到 35ZB。与此同时,数据复杂性也急剧增长,其多样性(多源、异构、多模态、不连贯语法或语义等) 、低价值密度(大量不相关信息、知识“提纯”难度高)、实时性(数据需实时生成、存储、处理和分析)等复杂特征日益显著。预示着全球已然进入了“大数据”时代。
大数据蕴含着极大的价值,而如何快速有效的获取到这些数据为我们服务,这也是一个大难题,为了解决这一问题,后羿工程师团队经过不断的探索和研发,终于开发出一款基于人工智能技术的网络爬虫软件,只需要输入网址就能够自动识别网页数据,无需配置即可完成数据采集,是业内首家支持三种操作系统(包括Windows、Mac和Linux)的采集软件。同时这是一款真正免费的数据采集软件,对采集结果导出没有任何限制,没有编程基础的小白用户也可轻松实现数据采集要求。
那么这款软件的操作性如何呢,是否简单上手易操作呢?下面我们来为大家演示一下操作流程,我们以当当网为例,为大家演示这款软件的操作流程。
首先,我们复制需要采集的网址,打开软件输入网址,新建智能采集模式。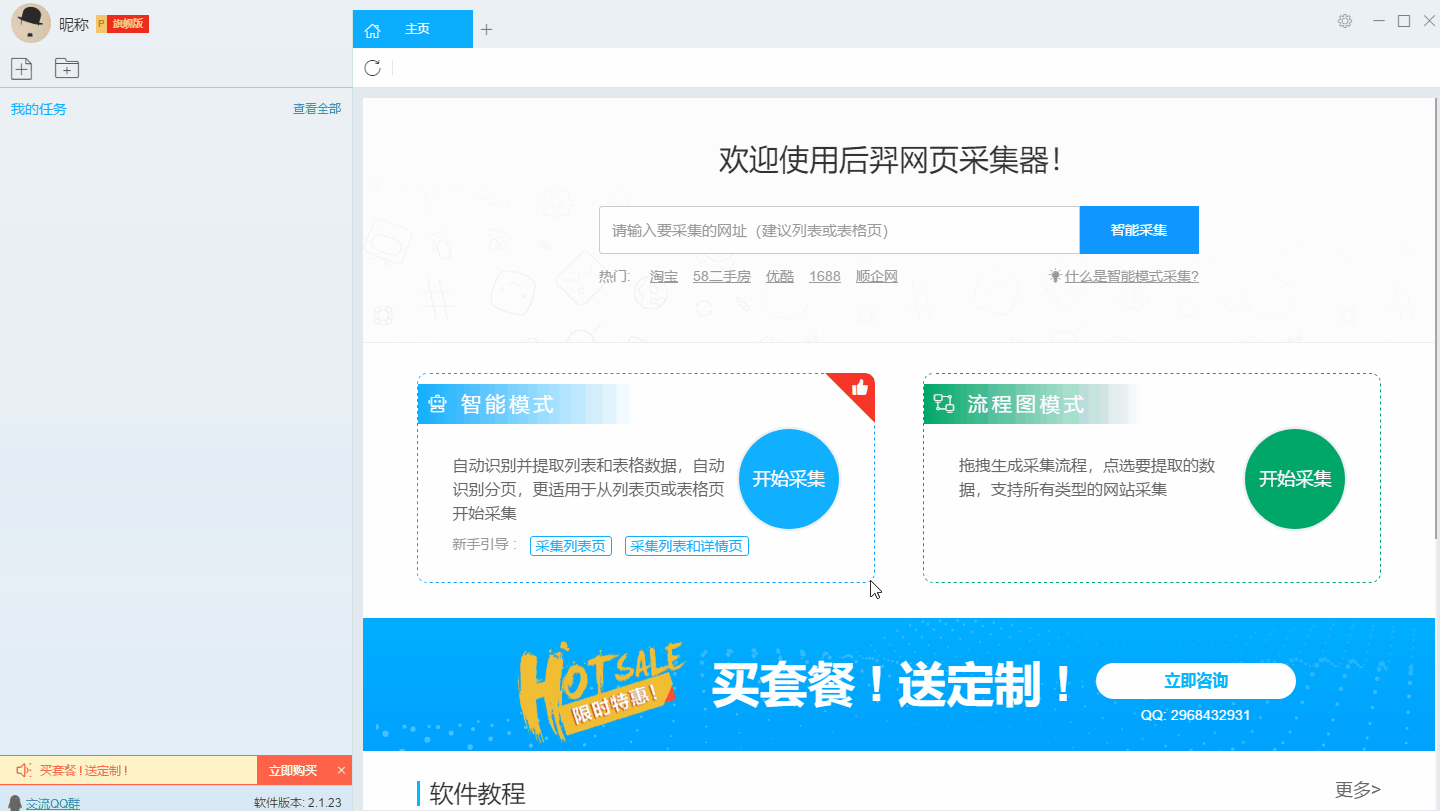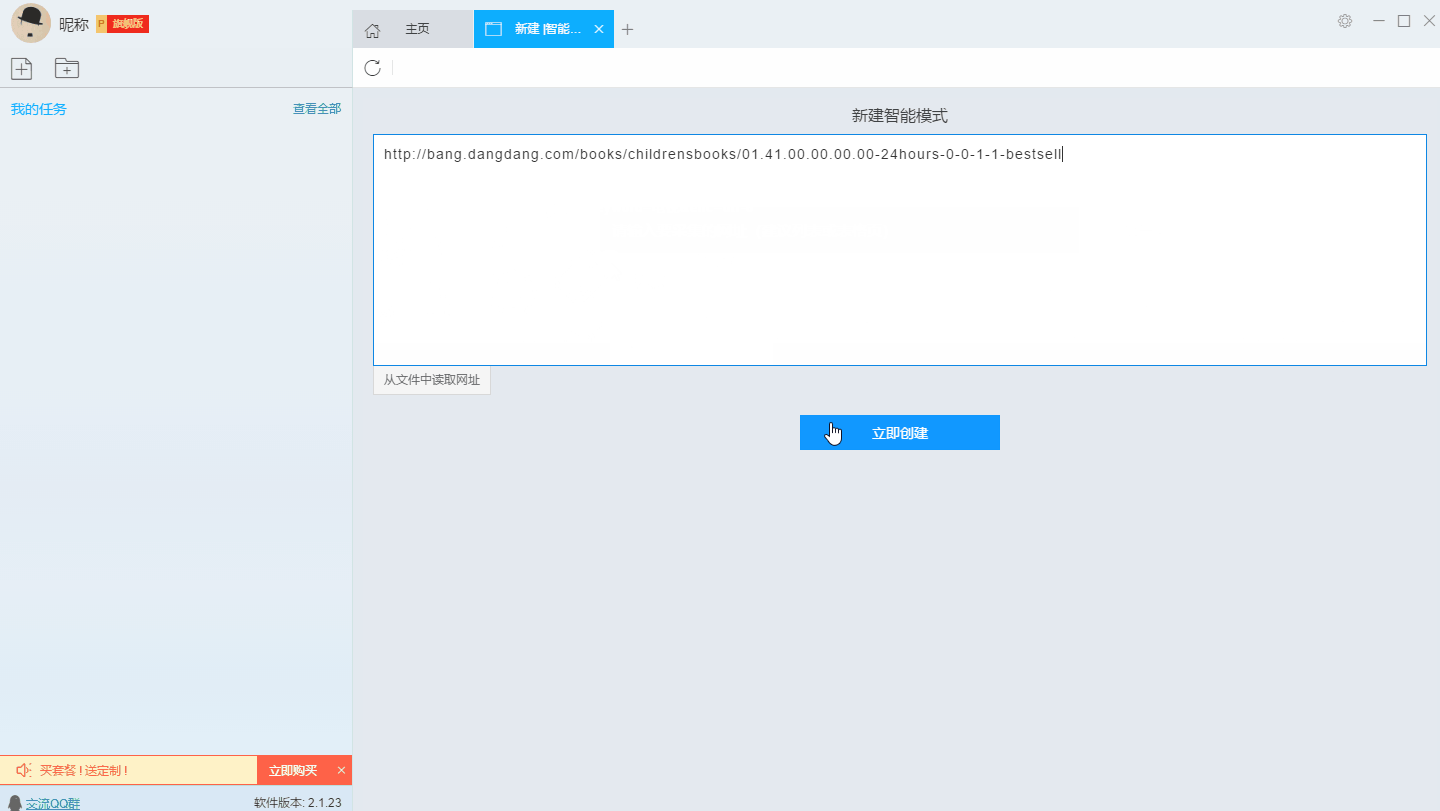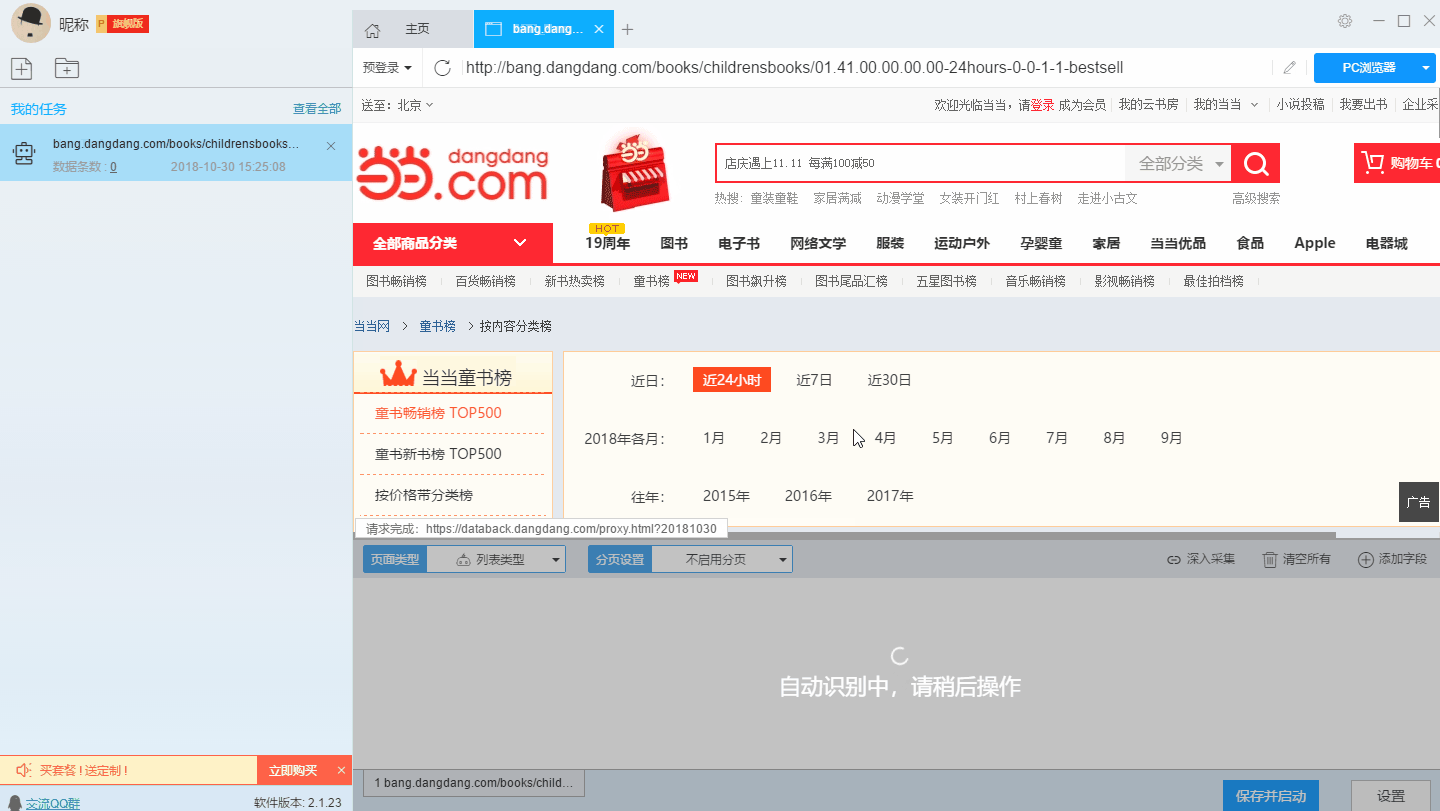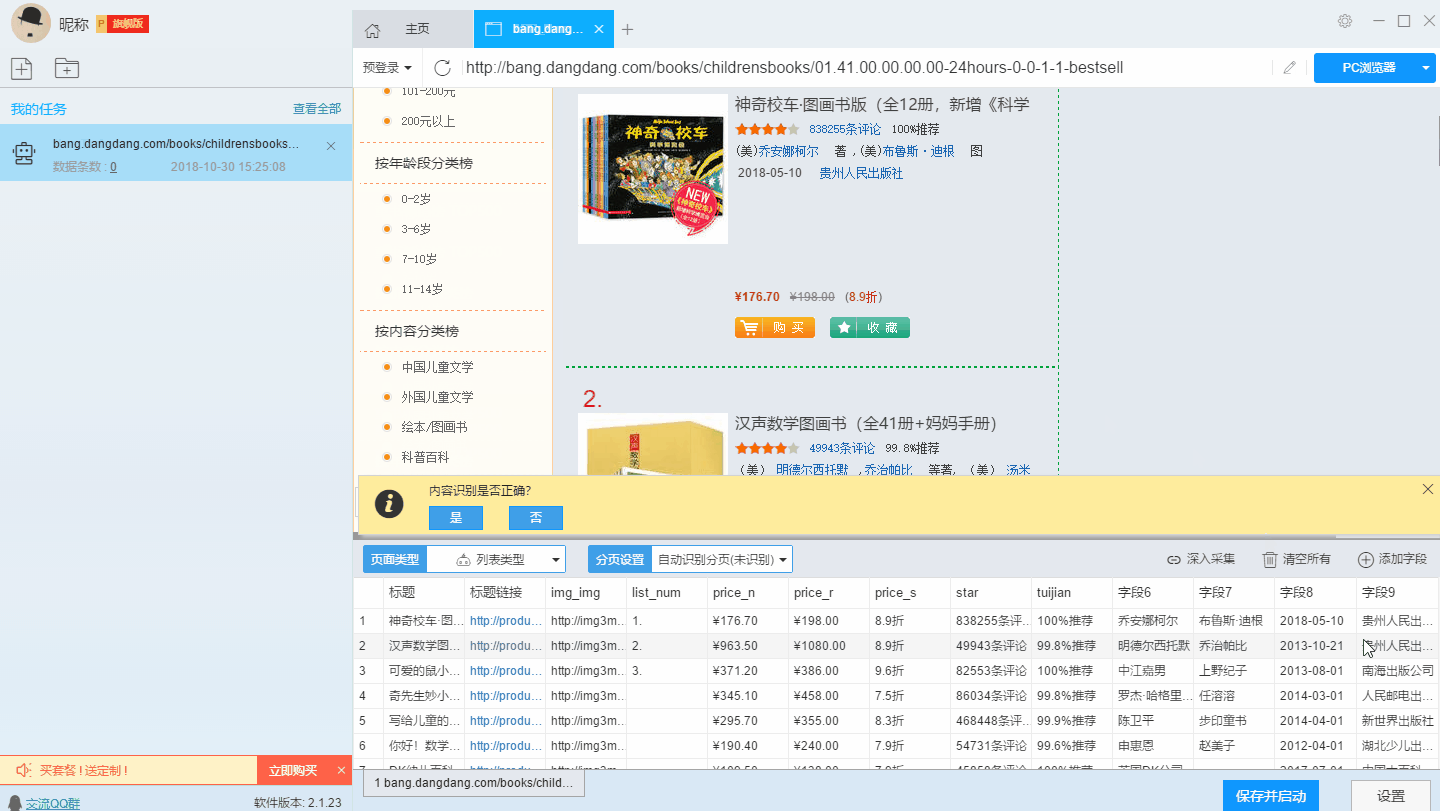
可以看到智能模式已经自动识别出了商品的字段,我们可以在这个基础上对字段进行加工处理,可以修改字段名称、删改字段信息等。
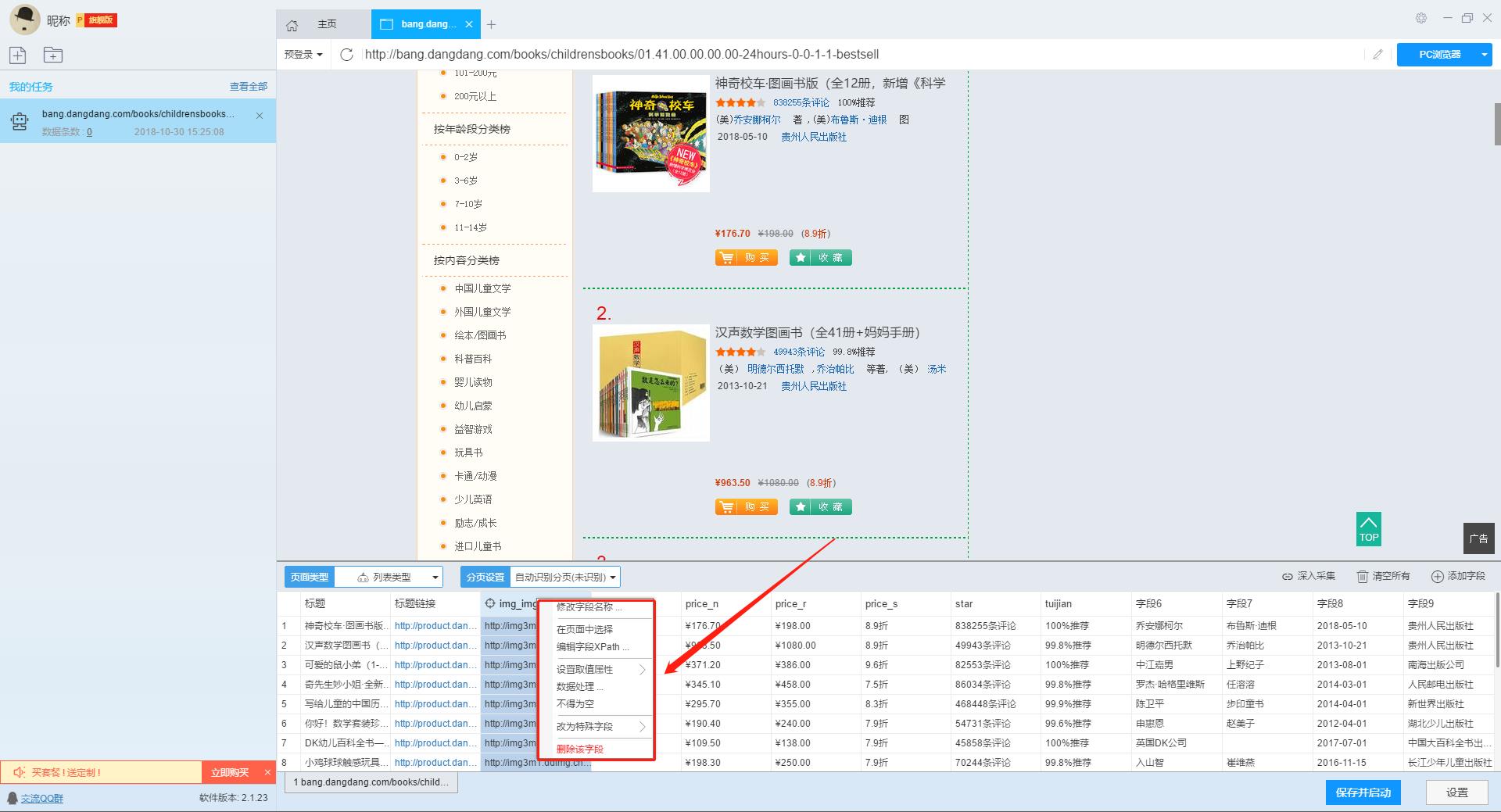
字段设置完毕之后,我们点击“保存并开始”按钮,开始任务抓取工作。

数据采集完毕之后我们可以导出数据,软件支持多种形式的导出方式,且导出都是免费且无限制的,用户可以尽情使用。
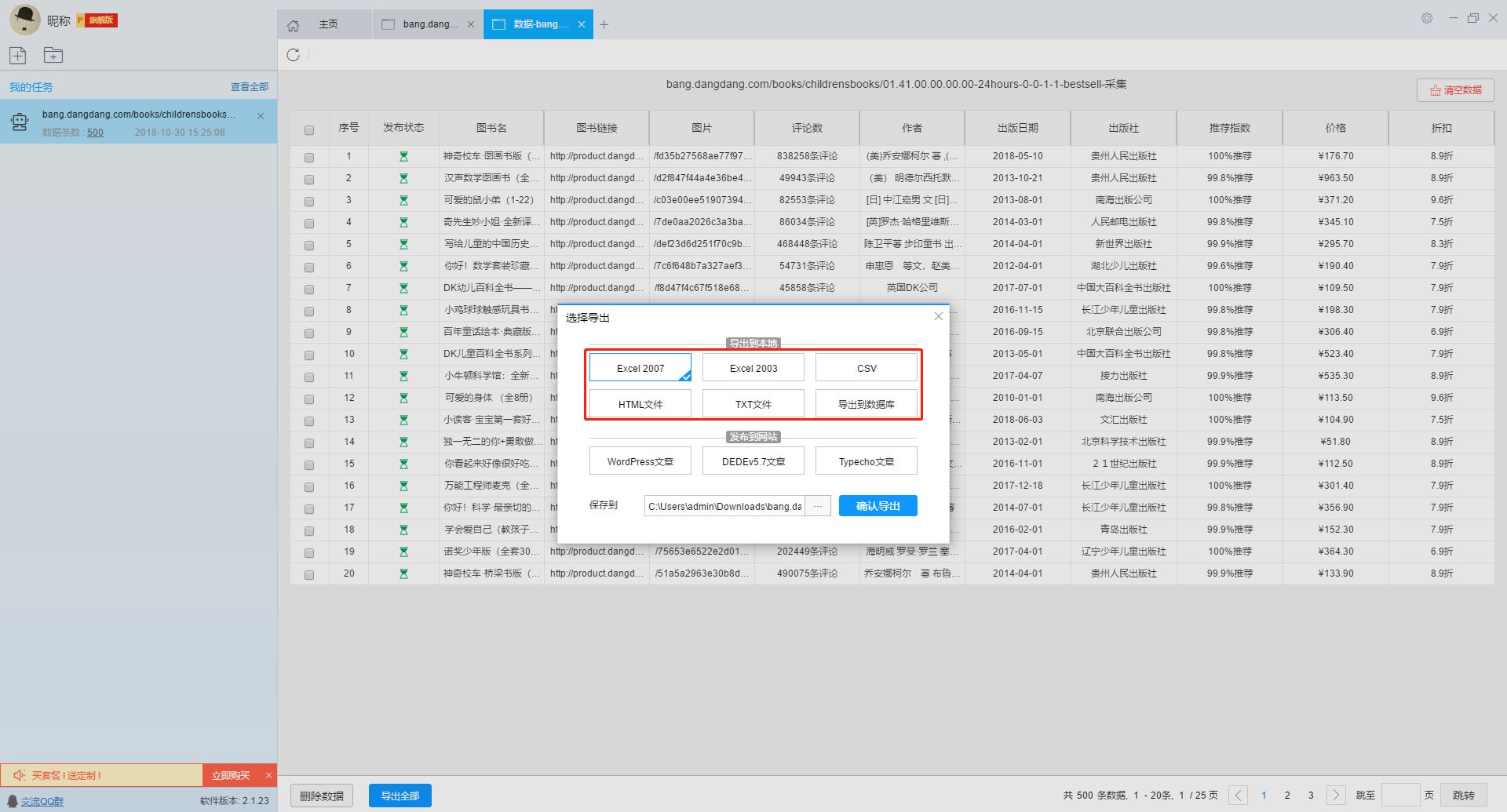
我们导出一个Excel表格的数据,导出效果如下图所示,是不是又方便又快速呢!重点还是完全免费的!免费的!免费的!!!

