一.如何创建Scrapy爬虫项目
(1) Win+R 打开cmd,假如我要在F盘的Scrapy文件中创建项目,进入相应的地方,如下。(cd,是进入下一级,cd…是返回上一级,cd\是返回盘符)
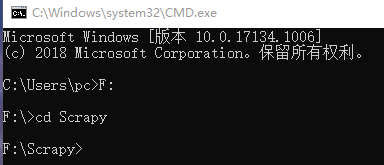
(2)使用指令scrapy startproject dangdang创建名为dangdang的项目。
dangdang这个项目下包括了同项目名dangdang的核心目录和项目的配置文件scrapy.cfg,如下。
 (3) 点击核心目录,又发现了有很多文件,如下。
(3) 点击核心目录,又发现了有很多文件,如下。
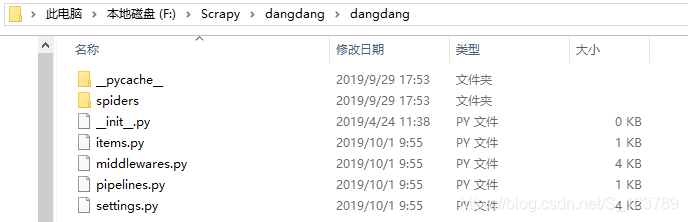
spiders文件夹放置我们的爬虫,可以使用scrapy genspider -t basic 文件名 域名创建爬虫文件,其中basic可以换,因为它是一个模版,还可换成:
Available templates: #模板说明
basic 创建基础爬虫文件
crawl 创建自动爬虫文件
csvfeed 创建爬取csv数据爬虫文件
xmlfeed 创建爬取xml数据爬虫文件
哪个里面写什么,这和Scrapy架构有关系
Spider要做两件事:(1)定义爬取网站的动作 (2)分析爬取下来的网页
_ init_.py:爬虫项目的初始化文件,用来对项目做初始化工作。
items.py:爬虫项目的数据容器文件,用来定义要获取的数据。
middlewares.py:爬虫项目的中间件文件。
pipelines.py:爬虫项目的管道文件,用来对items中的数据进行进一步的加工处理。
settings.py:爬虫项目的设置文件,包含了爬虫项目的设置信息。
(4)运行scrapy项目下的爬虫文件scrapy crawl dd
注:不在scrapy项目下的爬虫文件用scrapy runspider + 文件名.py来运行
二.Scrapy的一些指令说明
(1)输入scrapy -l ,可以查看全局指令
bench 测试电脑当前爬取速度性能
fetch 将网页内容下载下来,然后在终端打印当前返回的内容
genspider 创建spiders文件夹下的.py爬虫文件
runspider 通过runspider命令可以不依托scrapy的爬虫项目,直接运行一个爬虫文件
settings 使用settings命令查看的使用对应的项目配置信息
shell 通过shell命令可以启动Scrapy的交互终端
startproject 创建爬虫项目
version 输出Scrapy版本
scrapy version [-v], 后面加 -v 可以显示scrapy依赖库的版本
view 用于下载某个网页,然后通过浏览器查看
(2)进入创建的爬虫项目,再输入scrapy -l,可以查看全局指令与项目指令
如craw…
(3)scrapy genspider -l 查看scrapy创建爬虫文件可用的模板
三.当当网商品爬取实战
目标:爬取当当网连衣裙第一页商品的名称、链接、评论数;并写入数据库。
(1)利用cmd命令行创建好项目及spiders文件夹下的爬虫文件后,用编辑器打开。
(2)找到item.py文件,定义要获取的数据容器。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
#items.py:爬虫项目的数据容器文件,用来定义要获取的数据。
#爬取当当网连衣裙商品的名字、链接、评论数
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
link = scrapy.Field()
comment = scrapy.Field()
(3)找到自定义的爬虫文件dd.py。
# -*- coding: utf-8 -*-
import scrapy
from dangdang.items import *
from scrapy.http import Request
class DdSpider(scrapy.Spider):
# 一般和爬虫文件名一样
name = 'dd'
# 允许爬取域名为'dangdang.com'的网址
allowed_domains = ['dangdang.com']
# 第一次爬取的网址
start_urls = ['http://category.dangdang.com/cid4008149.html']
# response是爬取网页信息后返回的信息
def parse(self, response):
item = DangdangItem()
# item可理解为一个字典,下面为每个key的value赋值都为一个列表
# response.xpath('//a[@name="itemlist-title"]/@title').extract()返回的是一个列表
item["title"] = response.xpath('//a[@name="itemlist-title"]/@title').extract()
item["link"] = response.xpath('//a[@name="itemlist-title"]/@href').extract()
item["comment"] = response.xpath('//a[@name="itemlist-review"]/text()').extract()
yield item
#上面爬取第一页的信息,那么怎么爬取后面几页的信息呢?
#构造请求要用到scrapy.Request(url, callback)
# url:请求链接
# callback :回调函数,当请求完成后,获取到响应,
#引擎会将该响应作为参数传递给这个回调函数。回调函数进行解析或者生成下一个请求,回调函数如下面的parse。
for i in range(2, 4):
url = 'http://category.dangdang.com/pg' + str(i) + '-cid4008149.html'
yield Request(url, callback=self.parse)
(4)打开命令行输入:scrapy crawl dd --nolog运行爬虫文件,也是运行爬虫项目。
运行结果:
(部分展示)

