首页
移动开发
物联网
服务端
编程语言
企业开发
数据库
业界资讯
其他
搜索
当当网图书
其他
2019-02-19 21:21:20
阅读次数: 0
目标站点需求分析
获取当当网每个图书名字和评论数
涉及的库
scrapy,mysql
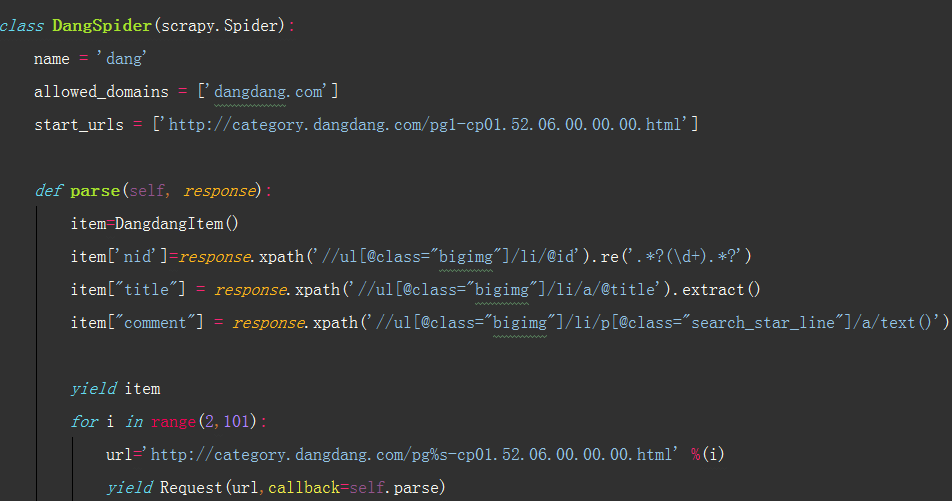
获取解析单页源码
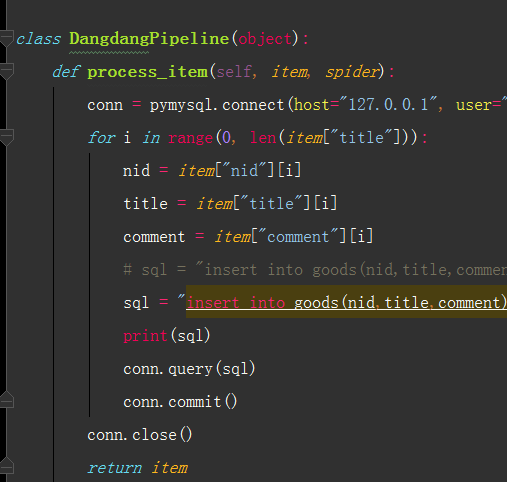
保存到数据库中
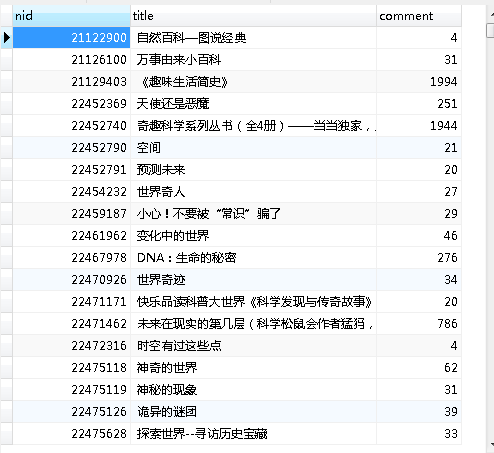
结果
猜你喜欢
转载自
www.cnblogs.com/du-jun/p/10403326.html
当当网图书
当当网
python当当网爬虫
scrapy 当当网 爬虫
Scrapy爬虫(5)爬取当当网图书畅销榜
利用lxml和request完成当当网图书信息提取
分布式爬虫----当当网图书数据爬取
利用python爬虫可视化分析当当网的图书数据!
基于Scrapy框架的当当网编程开发图书定向爬虫
保姆级scrapy框架实践:爬取当当网java图书数据
当当网程序设计类图书信息爬取
Python爬虫实战+Scrapy框架 爬取当当网图书信息
python课程设计——当当网Python图书数据分析
爬虫爬当当网书籍信息
当当网 / sharding-jdbc
当当网的elastic-job
dubbox 当当网编写下载
纪念逝去的当当网
自写当当网1
爬虫实例:当当网书籍介绍
scrapy爬取当当网
(转载)当当网开源的 dubbox 介绍
08年当当网中期项目
windows中搭建当当网
Python 当当网数据分析
爬虫及数据分析--当当网
爬虫基本原理介绍和初步实现(以抓取当当网图书信息为例)
[Python爬虫]爬虫实例:在线爬取当当网畅销书Top500的图书信息
[Python爬虫]爬虫实例:离线爬取当当网畅销书Top500的图书信息
爬取当当网2017畅销书目
今日推荐
Linus “吃狗粮”最积极!
开源日报 | Winamp播放器即将开源;生成式AI之战升级第二轮;Linus“吃狗粮”最积极;AI进入泡沫前期;吴泳铭为阿里云带来了什么?
NetBSD 禁止提交由 AI 生成的代码
Apache Doris 2.0.10 版本正式发布!
开源日报 | 大模型开战;大模型独角兽被曝卖身;周鸿祎建议谷歌开源所有产品;最大开源AI社区提供1000万美元共享GPU
开源日报 | Chrome内置Gemini的意义不在于Gemini;中国AI追随之路的五大误区;ECharts创始人“下海”养鱼;谷歌I/O开发者大会什么都有,只是没有惊喜
微软回应中国区AI团队“打包赴美”传闻
周排行
SVN服务端安装在阿里云
实战 | 相机标定
webpack核心概念
note20——》只要肯低头吃苦,人生就会有救
PAT甲级 1062 Talent and Virtue (25 分)排序
NG Toolset开发笔记--5GNR Resource Grid(26)
如何对待上司
oracle命令
第9章 STL迭代器
logstash使用es映射模板
每日归档
更多
2024-05-20(36)
2024-05-19(0)
2024-05-18(4)
2024-05-17(34)
2024-05-16(6)
2024-05-15(24)
2024-05-14(0)
2024-05-13(18)
2024-05-12(0)
2024-05-11(38)