GAN(一):基本框架
小白的第一篇博客,写的有不对的地方,望各位批评指正;
一、GAN的概念
1)generator:Neural Network
image generation:
给定一个vector,经过NN Generator后,产生一张图片
sentence generation:
给定一个vector,经过NN Generator后,产生一个句子
2)discriminator:Neural Network
image----->Discriminator----->scalar(一个数),这个数越大,表示image越realistic,越小表示image越fake
一个GAN正是包含上述两部分,一个generator,一个discriminator(互相对抗)
generator和discriminator就像是猎食者和猎物之间的关系,一个产生图片,一个辨别图片的真假,互相促进,使得最终产生的图片接近realistic
问题1:为什么generator不通过样本自己学习,而要通过discriminator评分?
解答1:generator是通过产生一个pixel一个pixel来产生整张图像的,因此对于图像局部区域之间的联系不能控制,也就是没有所谓的全局观。而discriminator是对整张图像进行打分,具有全局观,因此用discriminator来促进
问题2:为什么discriminator不自己产生图像,而是只打分呢?
解答2:事实上如果能解决如何取到argmax的问题,discriminator是可以自己产生图像的,但是argmax非常复杂,经常不好解或者根本解不出来,所以也不采用。
二、algorithm
1.Initialize generator and discriminator(随机初始化G,D两个神经网络)
2. In each training iteration:
step1:Fix generator G, and update discriminator D
Discriminator learns to assign high scores to real objects and low scores to generated objects.
(固定G,更新D。随机采样z,输入到G,G产生一系列图像G(z),D将其和database中的图像相比较,学习给真实的图像打高分,给假的图像打低分)
step2:Gix discriminator D, and update generator G
vector–>generator(NN,update)–>image
image–>discriminator(NN,fix)–>score(higher is better)
so, we need Gradient Ascent not Gradient descent
(固定D,更新G)

首先,我们要明确一点:G和D是互相促进的。G的目的是产生的图像让D感到模糊不知道该分成realistic(看起来像是现实的)还是fake(看起来是假的),D的目的是将realistic和fake的图像准确分辨。所以G产生的图像会越来越真,D的辨别能力会越来越强,最终达到一个平衡。
Pdata 表示真实数据的分布,Pg generator产生的分布,最终的目的就是让Pg 的分布尽可能的和Pdata 相同。
我们用D(x)表示真实图像经过discriminator后的分数,G(z)表示随机变量z经过generator后产生的图像,那么有:D(G(z)) 表示generator产生的图像经过discriminator后的分数
我们所希望的是最大化下面这个式子:
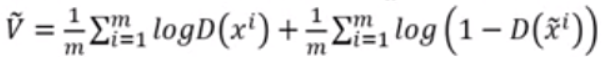
- 从discriminator的角度来看,D(x)越大越好;上式的第二项越大越好(第二项中减号后面那项表示fake图片的得分,自然越小越好,所以带个减号之后就是越大越好CSDN上数学公式难输。。。能懂-这意思就行)
因此,我们希望最大化上面这个式子

2.从generator的角度来看,当然是希望自己产生的图片能够瞒天过海,所以希望上式越大越好
有了这两个式子以后,就可以使用梯度上升或者梯度下降(在两个式子前面加负号)来解决了。