一、VAE-GAN简介
下图展示了VAE-GAN的大体框架。
所谓“人如其名”,在给gan命名的时候也是如此。VAE-GAN就是VAE和GAN的结合体。
VAE:包含encoder和decoder两部分。
- encoder的作用是编码,也就是将输入的图片image1转换成向量vector
- decoder的作用是解码,也就是将向量vector转换成图片image2
其中,image1和image2要尽量相同,原因是我们希望对同一个东西进行编解码后的产物仍然是自己。
GAN:包含generator和discriminator - generator:就是VAE的decoder,将向量vector转化为image
- discriminator: 评判generator产生的image是realistic还是fake,给出一个scalar(分数或者可能性或者二分类结果)

下面说一下算法的大致运作流程:
- 初始化encoder,decoder,discriminator(其实就是三个神经网络)
- 迭代更新:
·从database中随机采样,x1,x2,xM
·x1,x2,xM输入到encoder中,产生z’ = En(x)
·将z’1,z’2,z’M输入到decoder中,产生x’=De(z’)
·从某个分布(如均匀分布,高斯分布等)取样z1,z2,zM
·将z1,z2,zM输入到decoder中,产生x*=De(z)
(注意,下面这张图此处公式有误,遵循文字叙述)
·最后,按照下图中的式子更新encoder,decoder,discriminator
现在,用通俗的语言来叙述一下更新的理由,方便各位读者理解:
encoder和decoder合起来的目标是:一张图片编解码之后尽量保持原样。因此,
encoder的更新准则是:编解码前后图片的方差尽可能小;编码前图片的分布和解码后图片的分布尽可能一致(分布用KL散度描述);
decoder的更新准则是:编解码前后图片的方差尽可能小;解码后的图片得分尽量高,reconstructed产生的图片的得分也尽量高
discriminator的更新准则是:要尽量能区分generator,reconstructed和realistic的图片;因此对于原始图像的得分要尽量高,对于generator,reconstructed的图片的得分要尽量低。
注意:上面的图片有三种情况:1)原始图片(分布在database中,realistic) 2)原始图片经过编解码之后产生的图片(generator) 3)从某个分布中随机采样得到z,输入解码器中获得的图片(reconstructed)

二、BiGAN简介
之前我们所遇到的auto-encoder都是这样的结构:image1输入到encoder中,产生输出vector,这个vector在输入到decoder中产生image2,然后最小化||image1-image2||
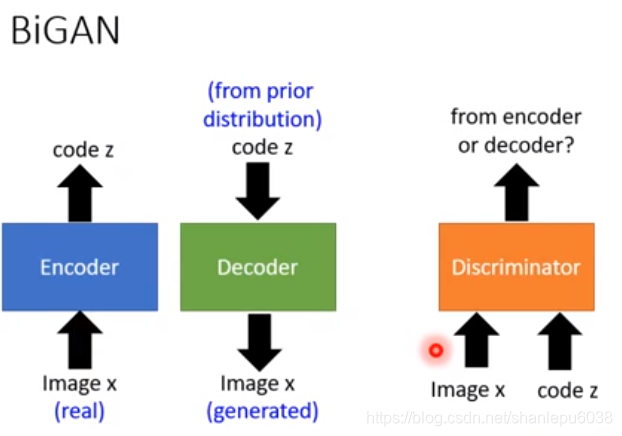
现在,我们换个思路,encoder和decoder将不再连接在一起,而是各自为政,加上一个discriminator后,就成了BiGAN。这种网络框架的思路如下:
- 输入image x(x是realistic的image),经过编码得到code z
- 从某个分布(这个分布可以是任意的,如高斯分布等)中采样z,经过解码得到image x
- 通过上述两步,我们可以得到一系列(x,z),这些(x,z)有的是encoder产生的,有的是decoder产生的,将这些(x,z)输入到discriminator中,让它判断是encoder产生的还是decoder产生的;如果discriminator不能准确判断,那么就成功了。
按照惯例,下面讲一下具体的算法流程:
- 初始化encoder,decoder,discriminator(就是三个独立的神经网络)
- 依次迭代:
·从database中采样x1,x2,xM
·将x1,x2,xM输入到encoder中,产生输出z = En(x)
·从某个分布中采样z’1,z’2,z’M
·将z’1,z’2,z’M输入到decoder中,产生输出 x’ = De(z)
·将(x,z)输入到discriminator中,并更新discriminator(其中一种方式是增加Dis(x,z)的得分,降低Dis(x’,z’)的得分;也可以完全倒过来,无关紧要,因为这里实质上是一个二分类问题,你把那个作为正例都无所谓)
·更新encoder和decoder(其中一种方式是降低Dis(x,z),增加Dis(x’,z’)。注意:这里要和上面更新discriminator的方式相反。因为encode和decoderr做的事情是要尽量迷惑discriminator,所以上一步要降低Dis(x’,z’),这里我们也要降低Dis(x,z),以此来达到一个平衡,不知道我说清楚没有~~~)

那么,说到这里之后,我们就需要考虑一个问题了:如果encoder和decoder能达到一个平衡,那么还需要discriminator吗?
答案是显然的。理想状态即optimal encoder and decoder 的数学表达如下,如果能达到完全理想的状态的话,确实不需要discriminator;而现实是,我们不可能达到理想状态,这也就是为什么auto-encoder模型产生的图片都很模糊的原因了。正是因为不能达到理想状态,所以我们需要discriminator的存在
