VAE-GAN如下图所示,也就是VAE+GAN的组合。
我们知道VAE是由一个编码器一个解码器组成,编码器可以将数据映射到一个低维的空间分布code c,而解码器可以将这个分布还原回原始数据,因此decoder是很像GAN中的generateor,如果再后面拼接上一个判别器D,这样的话,前两个模块就是VAE,后俩模块就是GAN。

训练的时候,decoder输出的x’要和原始的x尽可能接近(L1或L2距离),x’和真实数据x经过D需要判别出是是否是真实的图片,训练结束后,我们就能直接取出GAN的部分做生成使用,也可以取出VAE的部分,做压缩降维处理。
为什么要这么设计呢?
VAE有一个很大的问题就是,解码产生的图片往往都比较模糊。虽然我们希望decoder输出的x’要和原始的x尽可能接近,也就是loss越小越好,但是很难真的能loss小到0啊,loss越小不代表图片越是看起来越真实啊,因此我们就需要一个判别器来判别图片是不是真实的,可以来帮助VAE提高真实性。
另一方面从GAN的角度来看,之前我们的generateor输入都是随机的,比如采样某个噪声输入,训练起来比较难,现在有了VAE,我么就能准确摸索到generateor的输入的大概空间分布了,这样会变得准确高效一些。
也就是VAE和GAN相辅相成,互帮互组,最后训练完了后,VAE和GAN都是表现的更加优秀。
既然VAE和GAN能相辅相成,我们也可以做出下面的变化,这是不是很熟悉?如下图:

是不是很熟悉?因为这个结构就像是CycleGAN的结构啊,我们希望输入generator的z和经过generator和encoder后得到的z越接近越好,此时也需要判别器D来帮助VAE提高图像真实性。
 P(Z)是我们提前定的一个分布,比如就是一个normal distribution
P(Z)是我们提前定的一个分布,比如就是一个normal distribution
Encoder希望重构的图片和原始图片尽可能接近,且经过encoder后P(Z’|X) 的分布和P(Z)的分布尽可能接近,散度越接近越好。
Decoder/Generator希望重构的图片和原始图片尽可能接近,也希望能欺骗过Discriminator,希望经过Decoder的Z(包括encoder编码出的z和我们自行输入的z),得到的输出图像能被Discriminator判别为真的(包括重构图片和生成图片)。
Discriminator希望能分别出真实图片和虚假图片(包括重构图片和生成图片)。
一些变化:
VAEGAN存在一个问题,就是encoder编码出的z不一定完全符合我们期望的normal z的样式,也就是encoder编码出的z和我们自行输入的z可以存在细微的不同,但是通过generator的处理,它们产生的输出都能够骗过discriminator。
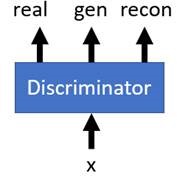
此时呢,Discriminator希望判别出真正来源的图片,得出对应的one-hot输出。但是encoder和decoder都希望自己能输出real图片。也没多大差别了。
真实图片自然不用说,是直接输入给D的数据库样本的真实数据。
其中重构图片X_rec与生成图片的差异是,重构图片是真实图片通过encoder与decoder之后产生的图片,如下图所示。

而生成图片X_g仅仅是一个初始分布z通过decoder之后产生的图片,如下图所示:

于是现在重构图片X_rec与生成图片X_g的差异能够被discriminator学到,又因为generator是共用的,那为了消除这种差异只能让输入z接近一致,也就是encoder编码出的z不断逼近我们给定的输入z,最终几乎完全一样。结果证明,这种模型在实验中比VAEGAN有少量的提升。