
在Executor类中的TaskRunner是执行Task的入口
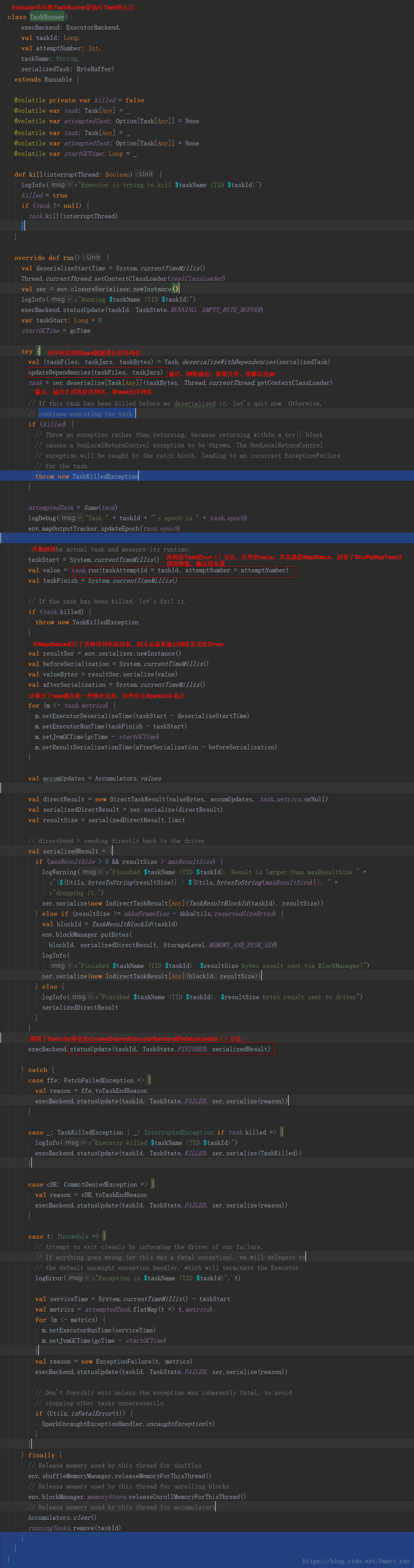
进入updateDependencies()函数

进入Task类中的run()方法
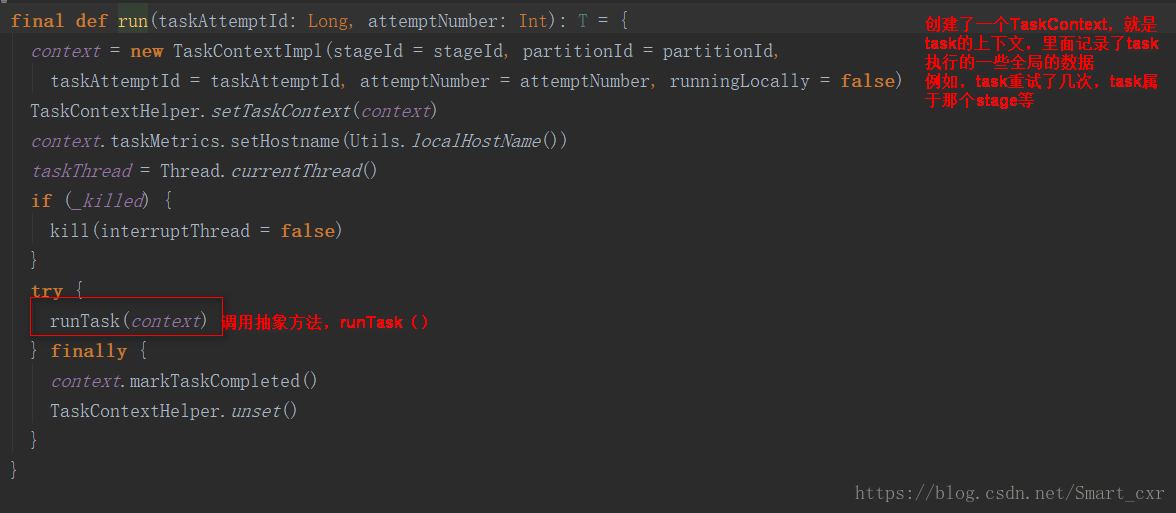
在上面的Task的run方法中,调用了抽象方法,runTask(),那就意味着关键的操作都要依赖于子类的实现,Task的子类ShuffleMapTask,ResultTask,要运行它们的runTask,才能执行我们自定义的算子和逻辑
接下来是先进入ShuffleMapTask类进行分析
一个ShuffleMapTask会将一个RDD的元素,切分为多个bucket,基于一个在ShuffleDependency中指定的partitioner,默认就是HashPartitioner
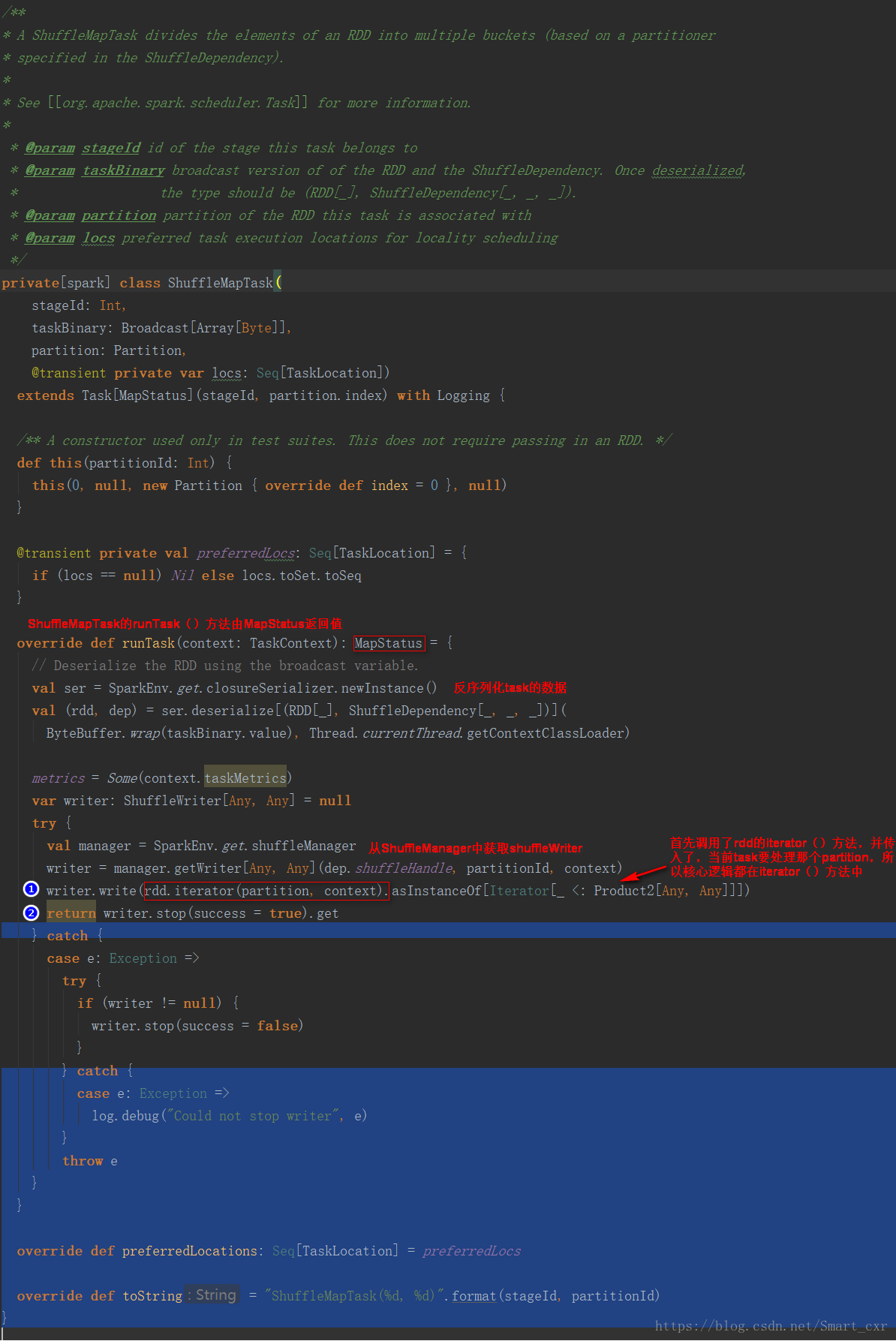
①首先调用了rdd的iterator()方法,并且传入了,当前task要处理哪个partition,所以核心的逻辑就在rdd的iterator()方法中,在这里,就实现了针对rdd的某个partition,执行我们自己定义的算子或者函数,执行结束返回的数据都是通过ShuffleWriter,经过HashPartitioner进行分区之后,写入自己对应的分区bucket

②返回结果MapStatus,MapStatus里面封装了ShuffleMapTask计算后的数据,其实就是BlockManager相关信息,BlockManager,是spark底层的内存、数据、磁盘数据管理的组件
进入RDD类的iterator()方法
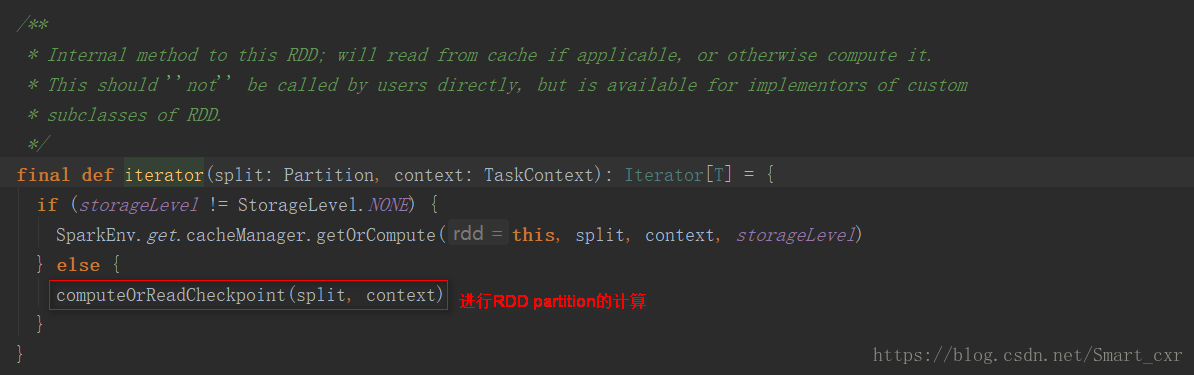
进入computeOrReadCheckpoint()方法

进入compute()方法
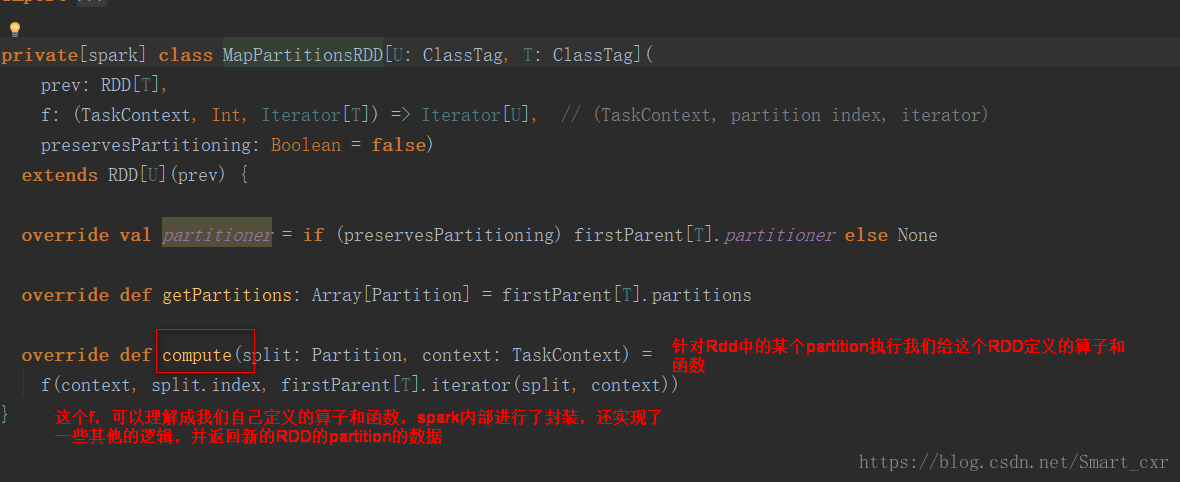
到这里对ShuffleMapTask类进行分析已经结束了
接下来是继续对第一张图中的statusUpdate()方法剖析,进入CorassGrianeExecuBackend的statusUpdate()方法
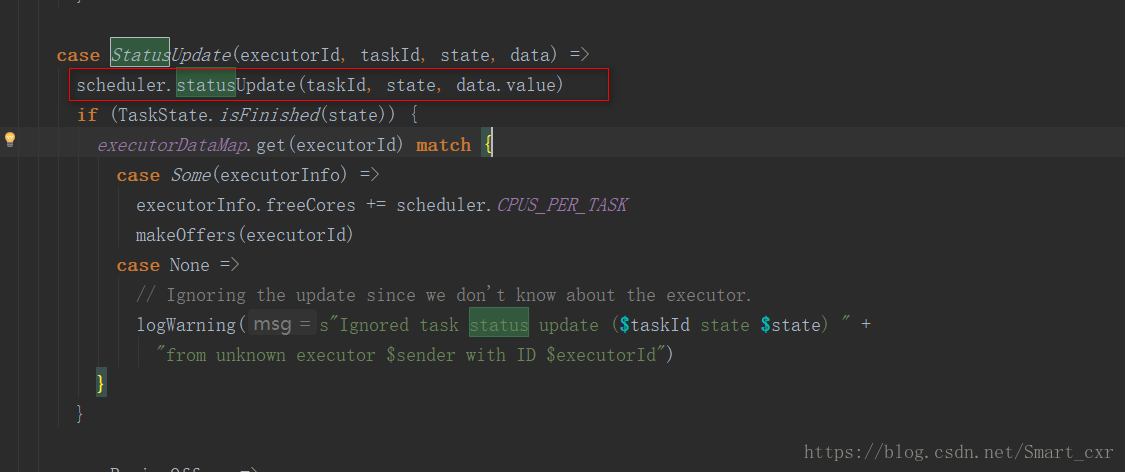
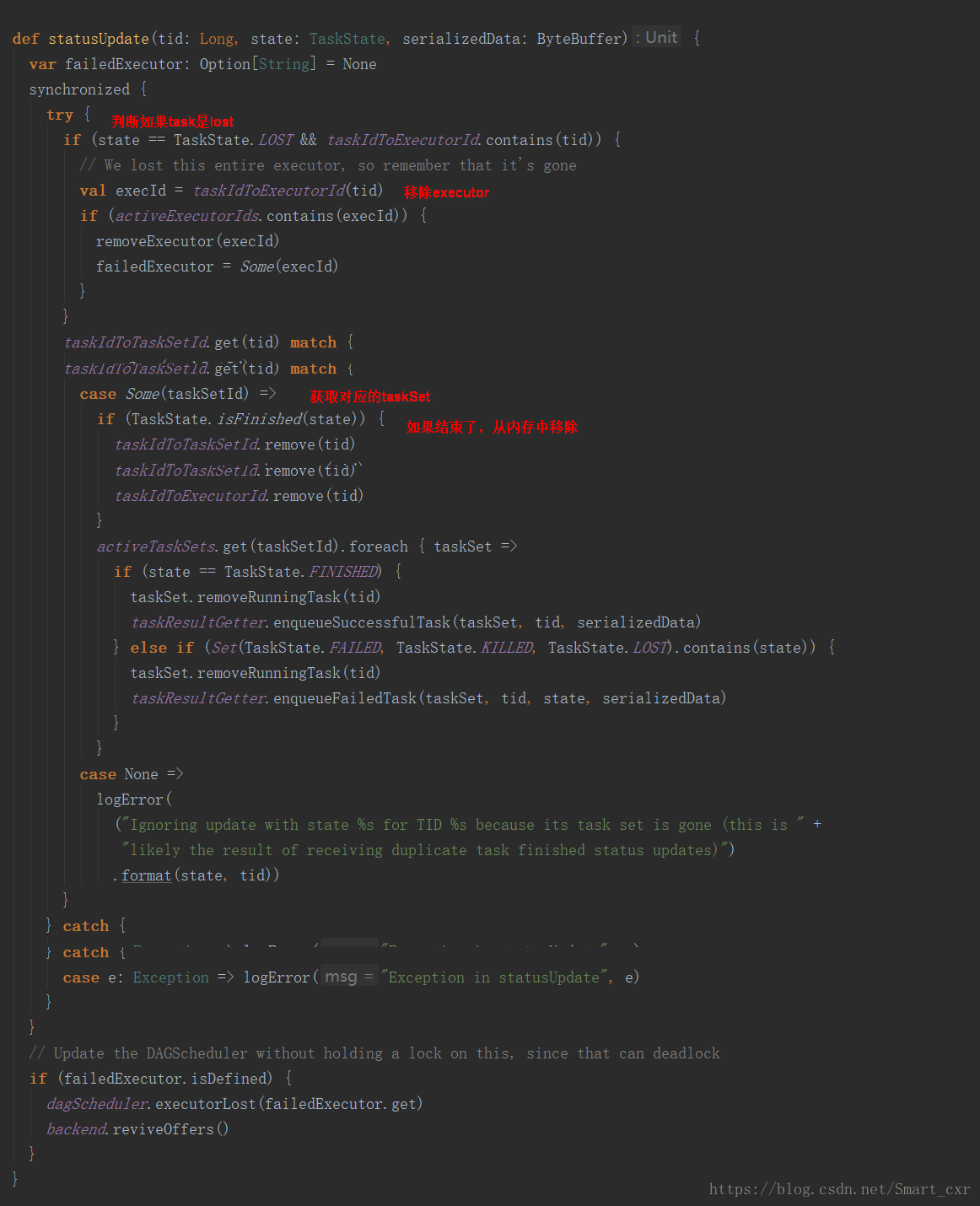
紧接着进入scheduler的statusUpdate()方法
最后对ResultTask的runTask进行剖析,因为ResultTask是最后一个Task因此它的方法内容比较简单
