1.JDK1.7
先看几个基础属性定义
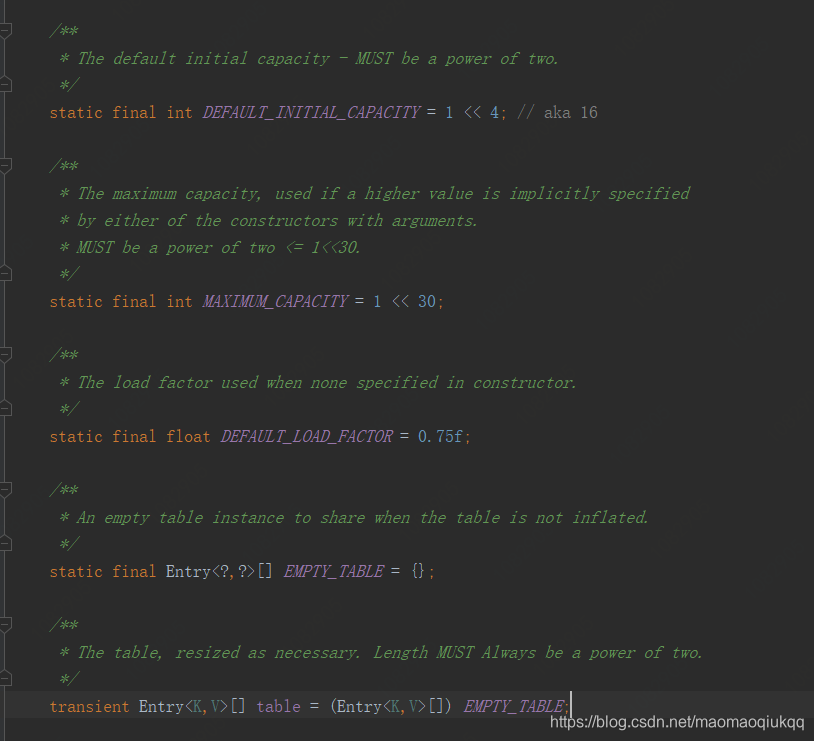
DEFAULT_INITIAL_CAPACITY:默认的初始化容量16,2的4次方
MAXIMUM_CAPACITY:最大容量:2的30次方约10亿多点
DEFAULT_LOAD_FACTOR:默认负载因子,当容量达到总容量的75%时会自动扩容,每次扩容容量变为原来的2倍,所以如果在总数据量可控的情况下,初始化HashMap是应指定容量大小。
table:Entry数组,用来存放实际的key可value
先来看一下put数据方法
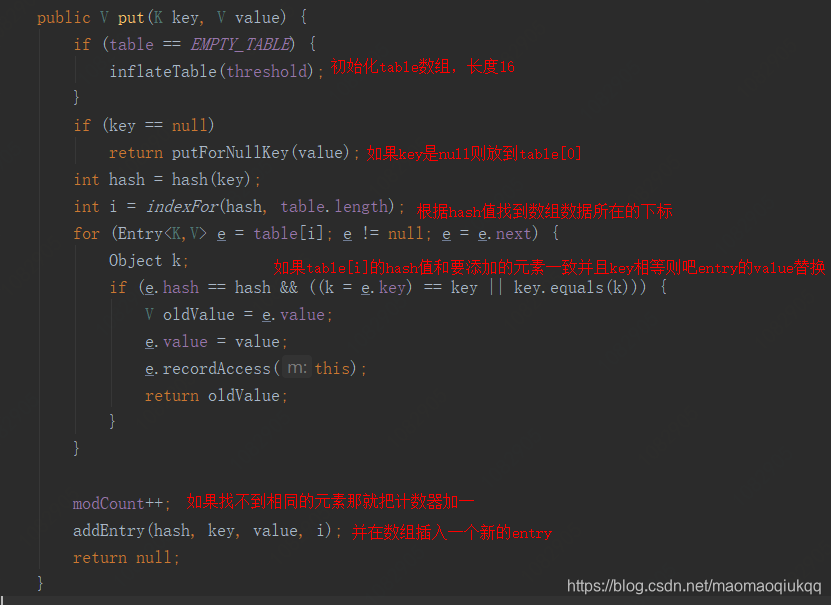
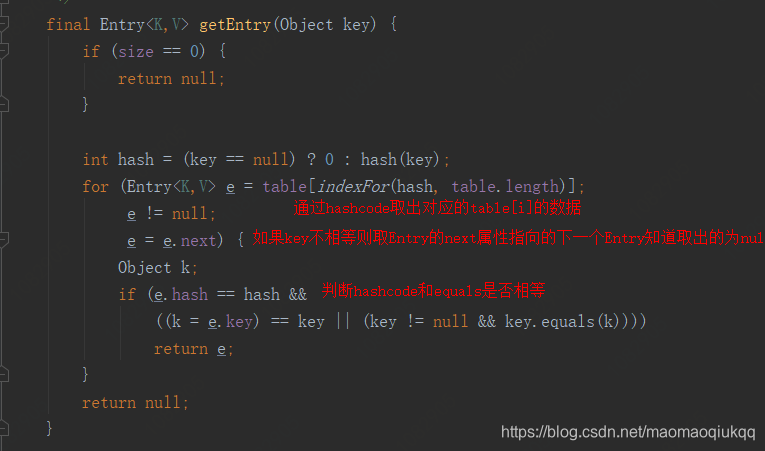
可以看到这里先判断hashCode是不是相等,然后判断equals,所以现在我们知道为什么HashMap的key为自定义对象时除了要重写hashCode还要重写equals方法了吧。
如果要put的对象已经存在,则替换原来的值并返回被替换的值;接下来是最下面的addEntry方法
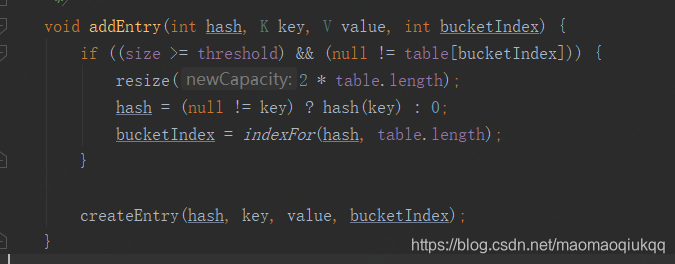
调用的是createEntry(hash, key, value, bucketIndex);
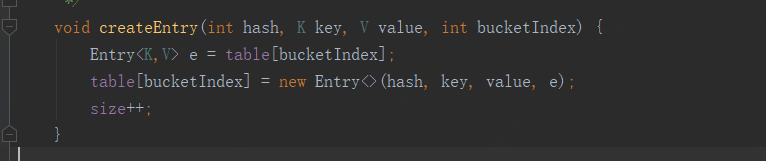
可以看到这里先获取了一下要插入的地方的entry对象e,然后重新给数组的该元素赋值,并把Entry对象的next指向之前的e;
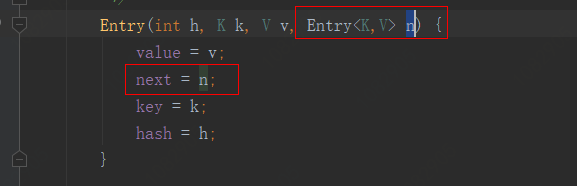
也就是说如果hash算法冲突的话,新的值会覆盖掉数组原来的值,但是会用一个指针指向原来的值,也就是一种单向链表数据结构。所以如果hash算法冲突度很高的话hashMap所有元素都保存在有限的几个数组项中,并且每个数组项是一个单向链表,此时查询性能非常糟糕。
然后我们看一下get方法

getEntry方法
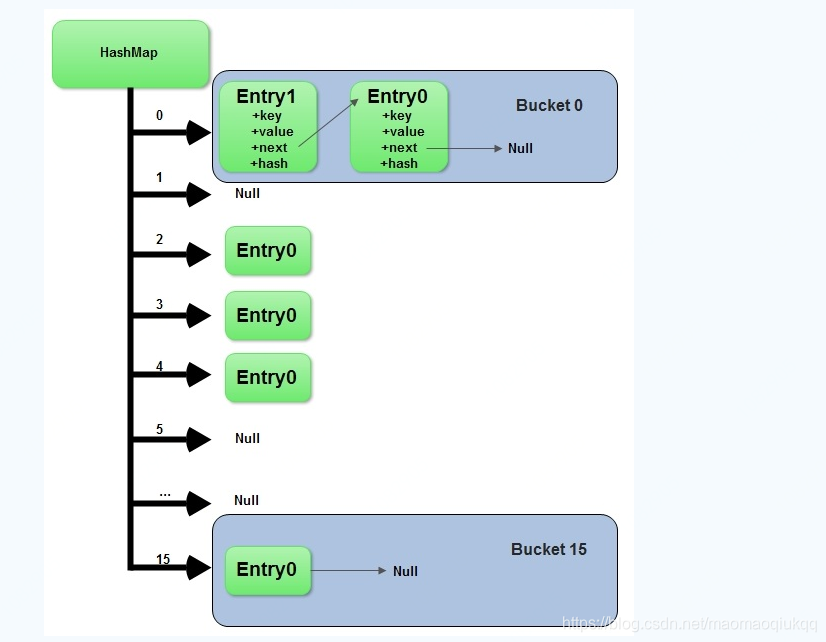
最后上原理图一目了然
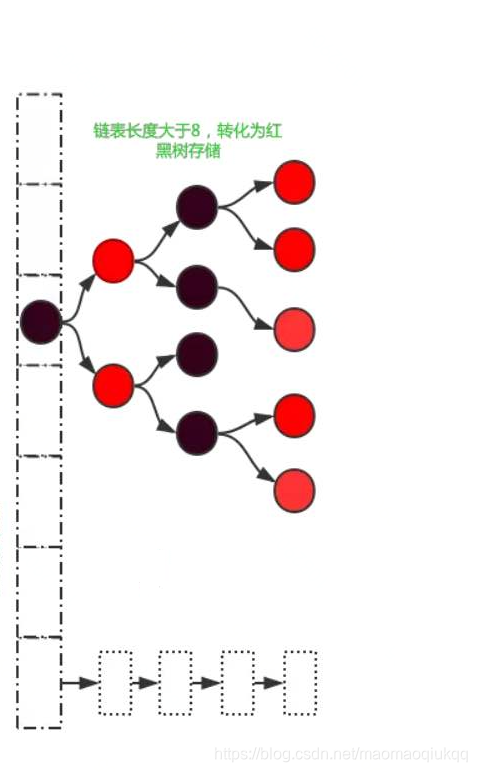
2. JDK 1.8实现
先上原理图
发现了一篇hashmap1.8讲的非常详细的文章,大家可以看一下Java集合:HashMap详解(JDK 1.8)
