前言
从决策树这三个字中我们既可以看出来它的主要用途帮助决策某一类问题,树是辅助我们来决策用的,如下图一个简单的判断不同阶段人年龄的图:
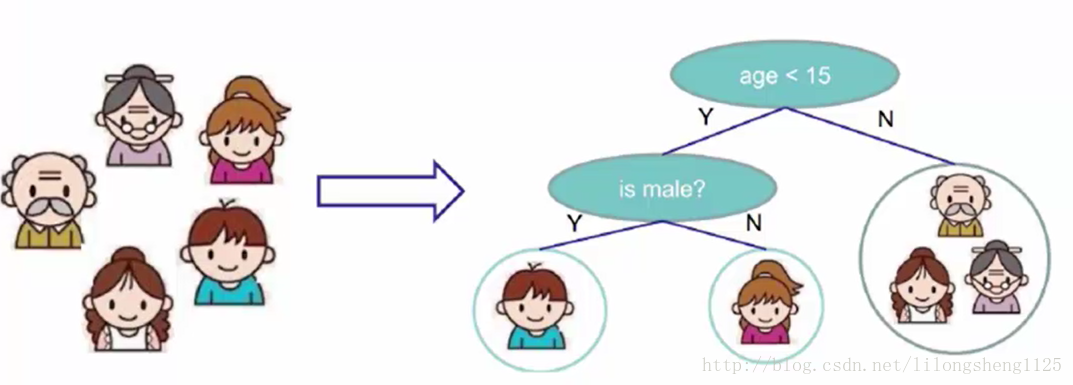
看到上图是有几个问题的,我们的目的是将左边人分类,首先根据什么属性分类最佳?如何量化角度来识别?从图中也可以看出来叶子结点不一定是单个数据元素,可能是一个集合也可能是一个元素,不过他们是属于同一个属性集合的,例如右边三个人都符合大于15这个特性,和前面介绍的算法类似,适用于分类和回归的一种算法,该算法通过该构建一个树结构来进行分类,决策树原理简单只通过简单的分支判断既可得到最终分类结果。
原理结构
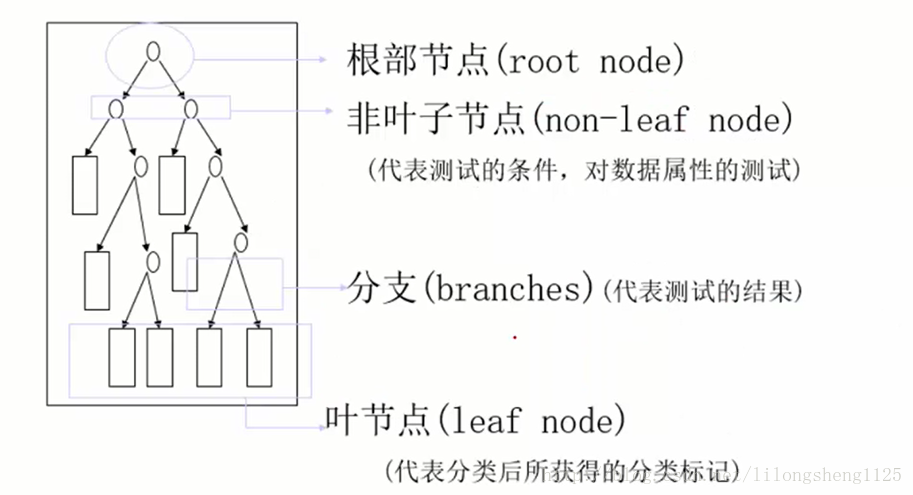
在上面的例子中,不同的节点代表不同的含义:

最上层表示根节点、最下层为叶子节点,叶子节点即结果数据点、中间一层为非叶子节点,各个分叉表示分支,各个节点代表的含义如下:
接下来我们就需要考虑如何构造决策树,只有构造出来树才能对数据分类,分为了两个阶段训练阶段和分类阶段:

让我们再来看一个例子,如下:
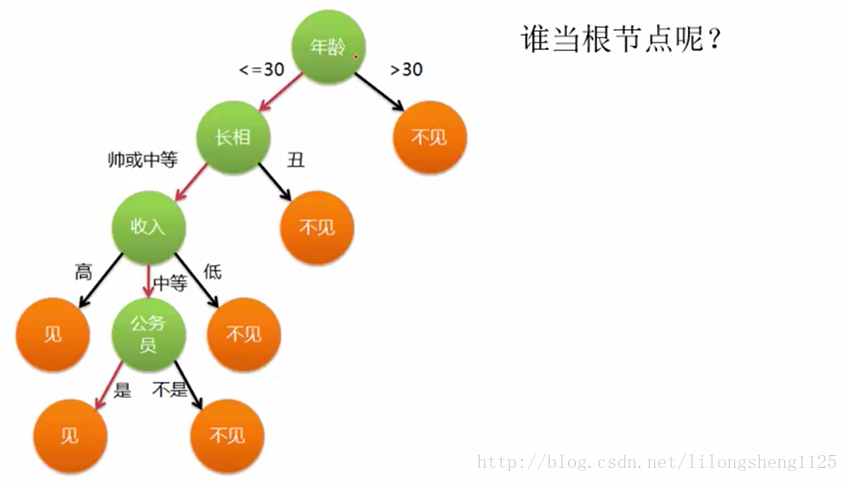
这是构造一个树第一个需要解决的问题,每次拆分子集时哪个属性和值来当条件,这里涉及到了量化指标熵,熵是信息论中的内容是熵农第一次提出表示信息的混乱程度,在化学中表示分子的运动混乱程度,公式如下:
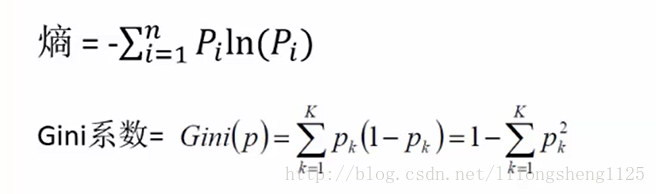
在公式中,i表示事件,注意不要和样本个数弄混,P表示一件事情发生的概念,-(概率*概率的对数值)累加和即熵值,先来看一下ln(x)函数,在x右半轴成单调递增,
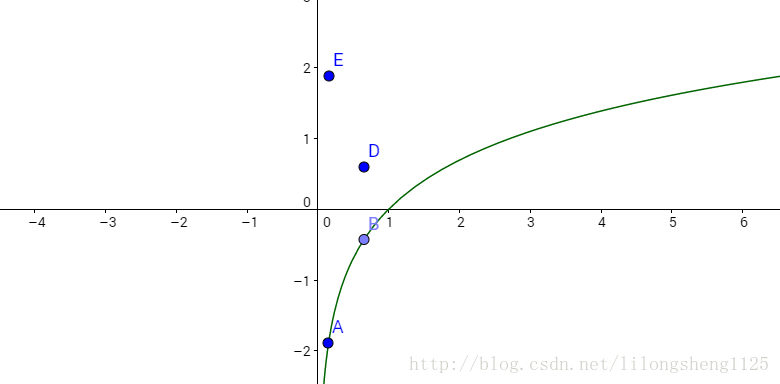
让我们通过数学上面空间来说明一下,假设有两个集合A和B各5个元素,A ={1,2,3,4,5} ,B={1,1,1,1,1} 各元素互相独立,A中每个元素发生概率为0.2 ,B中每个元素发生概率为1,计算各自的熵值:
熵A= -0.2*ln(0.2) + -0.2*ln(0.2) + -0.2*ln(0.2) + -0.2*ln(0.2) + -0.2*ln(0.2) 约等于 0.32 ,熵B= - 1*ln(1) *5 = 0 ,熵值越大表示混乱程度越大,从计划结果表明A集合的混乱程度比B大,除了通过熵值来华为还有一个属性是基尼不纯度,暂且不讨论。
有了熵值之后还不能确定让哪个属性来进行划分数据集合,我们的目标是最快的方式划分集合,因此就需要找到能使得熵值减少最快的属性来划分,引入了信息增益概念,信息增益就是熵值减少的多少,找到信息增益最大的也就是熵值减少最快的那一个属性即可。
下面有份数据表示天气的四个属性,标签为是否去打篮球,如下:
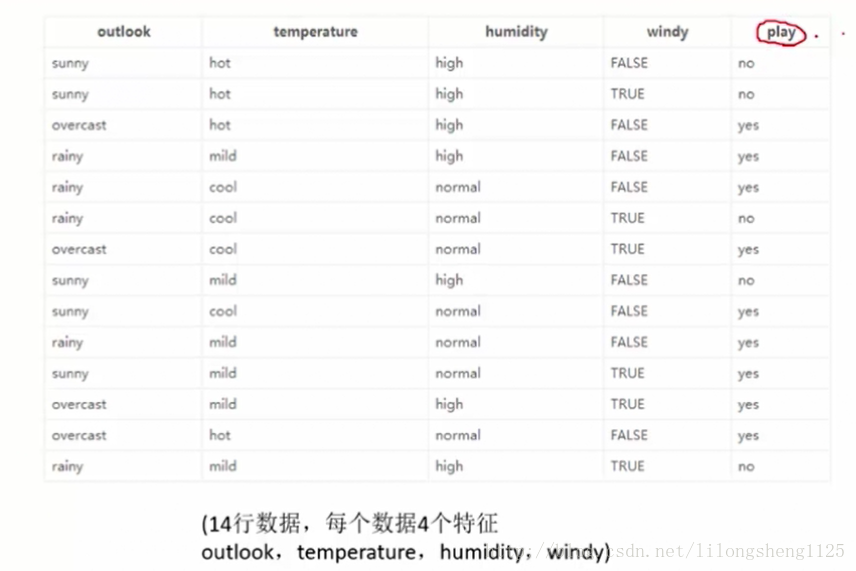
为了根据天气的四个属性决策是否去打篮球,此时就需要构建决策树,第一步计划初始标签的原始熵,四个属性划分后熵值分别是多少,如:
有了上面的样本后,先来计划原始的信息熵,即没有天气因素影响的情况下,标签的概率,样本共14个,yes打球事件9个样本,no不打球事件5个,则打球事件概率9/14,不打球事件概率5/14,由熵公式计划 :
原始熵=-9/14*ln(9/14)-5/14*ln(5/14) = 0.94
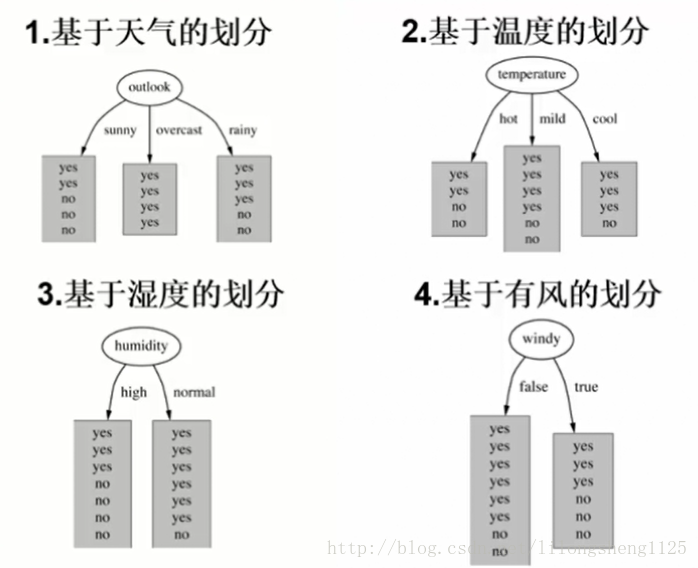
然后我们依次计算天气的各个属性作为根节点的信息熵,天气划分时如下:
outlook有三种情况 sunny、overcast、rainy ,这三种情况的概率分别为Poutlook(sunny)=5/14,Poutlook(overcast)=0,Poutlook(rainy)=5/14,他们的熵值为
outlook(sunny)=-2/5*ln(2/5)-3/5*ln(3/5)=0.971
outlook(overcast)=0
outlook(rainy)=-2/5*ln(2/5)-3/5*ln(3/5)=0.971
天气作为划分属性时熵值为=0.971*5/14+0+0.971*5/14=0.693
其它三种属性请自行计划,经比较选择天气第一个属性华为最佳,信息增益最大。
找到第一个根节点之后,还需要继续往下构建树,继续找第二个节点,递归往下构建,思路如下:
决策树分类算法的流程如下:
1.初始化根结点,此时所有的观测样本均属于根结点
2.根据下文中介绍的划分选择,选择当前最优的划分属性。根据属性取值的不同对观测样本进行分割
对分割后得到的节点重复使用步骤2,直到
分割得到的观测样本属于同一类或属性用完或者达到预先设定的条件,如树的深度。以叶子节点中大多数样本的类别作为该叶子节点的类别
上面提到的信息增益 也称为ID3算法(iterater Dichotomiser),该算法也有缺点,当属性值过多,每个属性值中划分出来的样本很少时会不起作用,如当有一列是id值时,id一般是自增主键,每个值对应一个样本,假如根据这一列来计算熵值会划分出来很多子集,每个子集只有一个样本,熵值都为0,由此引入了信息增益率 C4.5算法,可以避免这个问题,他们都是如何选择属性来划分数据集的方法。
代码
以下是实现时写的,如下:
def calcShannonEnt(dataSet):
'''
计算数据集的信息熵
:param dataSet:
:return:
'''
numEntries = len(dataSet)
print "numEntries = %s" % numEntries
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
print "labelCounts = %s" % labelCounts
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt
def createDataSet():
dataSet = [[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no']]
labels = ['no surfacing','flippers']
return dataSet,labels
def splitDataSet(dataSet, axis, value):
# 创建新的list帝乡
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
# 抽取
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def appendExtendTest():
a = [1,2,3]
b = [4,5,6]
a.append(b)
print a
a.extend(b)
print a
def chooseBestFeatureToSplit(dataSet):
'''
选择最好的数据集划分方式
:param dataSet: 原始数据集
:return: 最优分类特征的索引
'''
numFeatures = len(dataSet[0]) - 1
print "numFeatures = %s" % numFeatures
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0;bestFeature = -1
for i in range(numFeatures):
# 创建唯一的分类标签列表
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
# 计算每种划分方式的信息熵
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
# 计算最好的信息增益
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
else:
classCount[vote] += 1
# 测试一下函数效果
sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
print "classList[0] = %s" % classList[0]
print "classList.count(classList[0]) = %s" % classList.count(classList[0])
# 如果类别完全相同则停止继续划分
if classList.count(classList[0]) == len(classList):
return classList[0]
# 遍历完所有特征时返回出现次数最多的类别
print "dataSet[0] = %s" % dataSet[0]
print "len(dataSet[0]) = %s" % len(dataSet[0])
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
# 得到列表包含的所有属性值
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
if __name__ == '__main__':
myDat,labels = createDataSet()
print "myDat = %s" % myDat
print "labels = %s" % labels
# shannonEnt = calcShannonEnt(myDat)
# print shannonEnt
# myDat[0][-1] = 'maybe'
# myDat[1][-1] = 'maybe'
# print myDat
# shannonEnt = calcShannonEnt(myDat)
# print shannonEnt
# appendExtendTest()
# print splitDataSet(myDat,0,1)
# print splitDataSet(myDat,0,0)
# print chooseBestFeatureToSplit(myDat)
myTree = createTree(myDat,labels)
print myTree总结
决策树是很多算法的基础,除此之外还有回归树、森林树等算法,后续会一一介绍,不同算法对应的是不同的数据实例,数据决定了算法的形态和好坏。
题外思考
学会一技之长的好处
有一技之长的人感觉生活比别人过的要好一些,也很可能在其他方面很快取的突破,它的意义不仅仅是为我们混口饭吃,通过掌握某一技能的过程增强了我们的学习能力,树立了以后做好其他事情的信心和勇气,以后在做其它事情也会有很多帮助,另外在学习一项新事物的时候假如花费20%的时间就容易掌握了80%的知识技能,那么很快很多人就会进来,失去优势,这种事物也是不值钱的,值不值钱要看稀缺性,越稀少的东西越贵,大家都知道沙漠里水可能比金子贵就是这个道理,在学习和研究领导这个道理同样适用。