版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wcy23580/article/details/82629938
0 Preface
相关参数说明
- Julia: 1.0
- OS: MacOS
训练测试数据百度云链接:点击下载 密码: u71o
文件说明:
- rf_julia_charReg
- resizeData.py #批量重设置图片尺寸
- test #测试图片文件
- testResized #resized 测试图片文件
- train #训练图片文件
- trainResized #resized 训练图片文件
- sampleTest.csv #测试数据csv文件
- trainLabels.csv #训练数据label csv文件
1 加载数据
安装需要使用到的包:
using Images
using DataFrames
using Statistics #use mean(), sum()... function
using DataFrames
using CSV
注:如果没有安装包,使用以下脚本安装
import Pkg
Pkg.add([PKG NAME]) #例如:Pkg.add("Images")
读取图片文件数据,并返回矩阵
function read_data(type_data, labelsInfo, imageSize, path)
x = zeros(size(labelsInfo, 1), imageSize)
for (index, idImage) in enumerate(labelsInfo.ID)
nameFile = "$(path)/$(type_data)Resized/$(idImage).Bmp"
img = load(nameFile)
temp = float32(img)
temp = Gray.(temp)
x[index, :] = reshape(temp, 1, imageSize)
end
return x
end
解释:
float32(): 将其中的值转化为浮点数
Gray.(): 将RGB图像转化为灰度图像
reshape(): 在这里做的是平铺工作
设置图像大小以及项目路径:
imageSize = 400
path = "..."
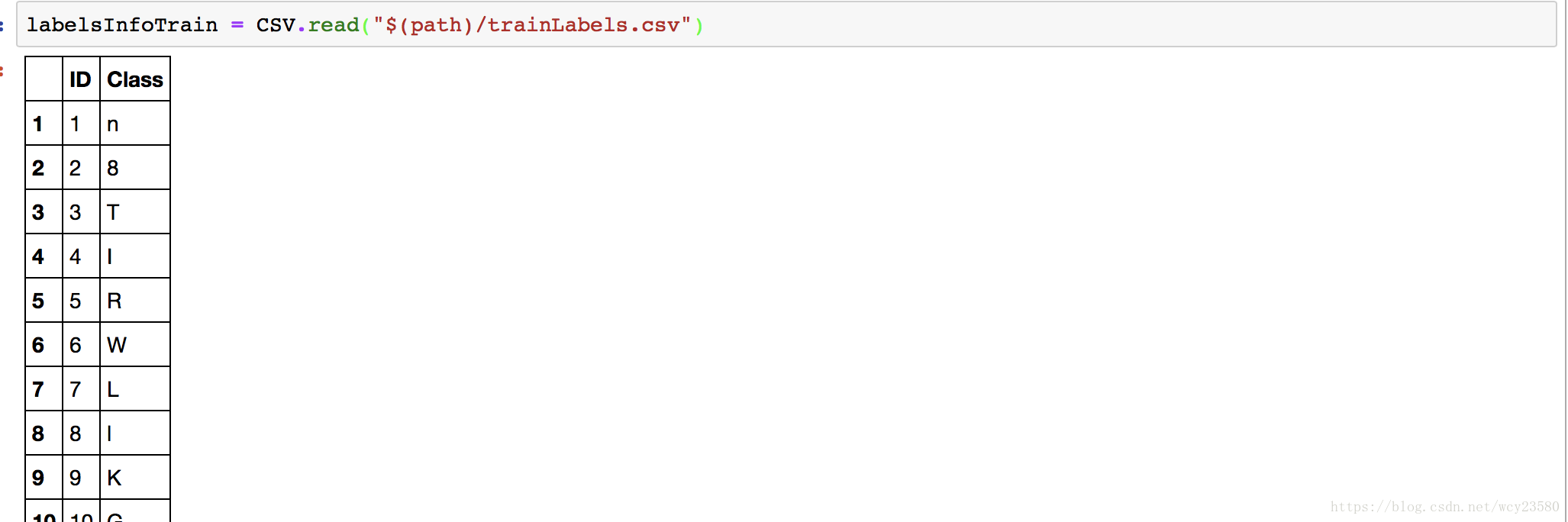
读取训练数据Label
labelsInfoTrain = CSV.read("$(path)/trainLabels.csv")
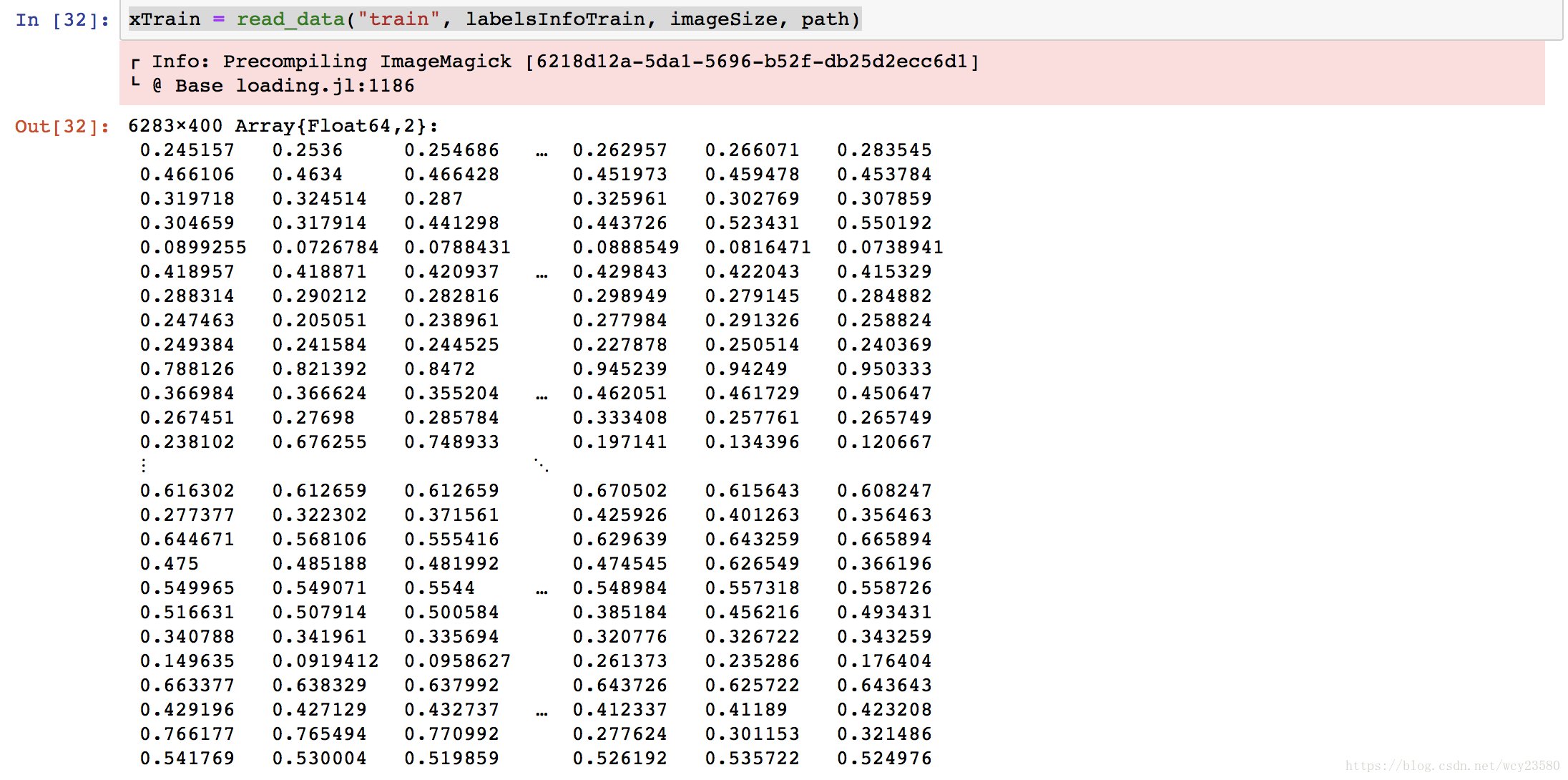
读取训练图像数据:
xTrain = read_data("train", labelsInfoTrain, imageSize, path)
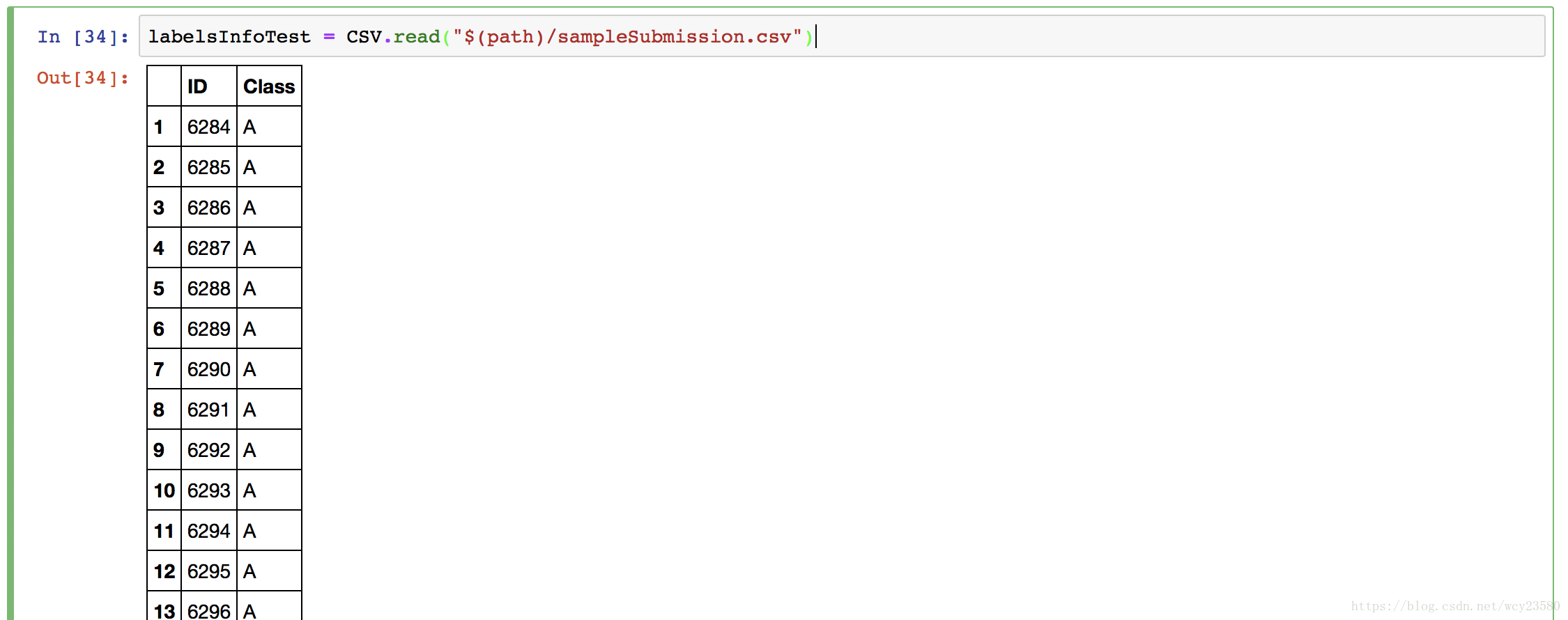
读取测试数据Label:
labelsInfoTest = CSV.read("$(path)/sampleSubmission.csv")
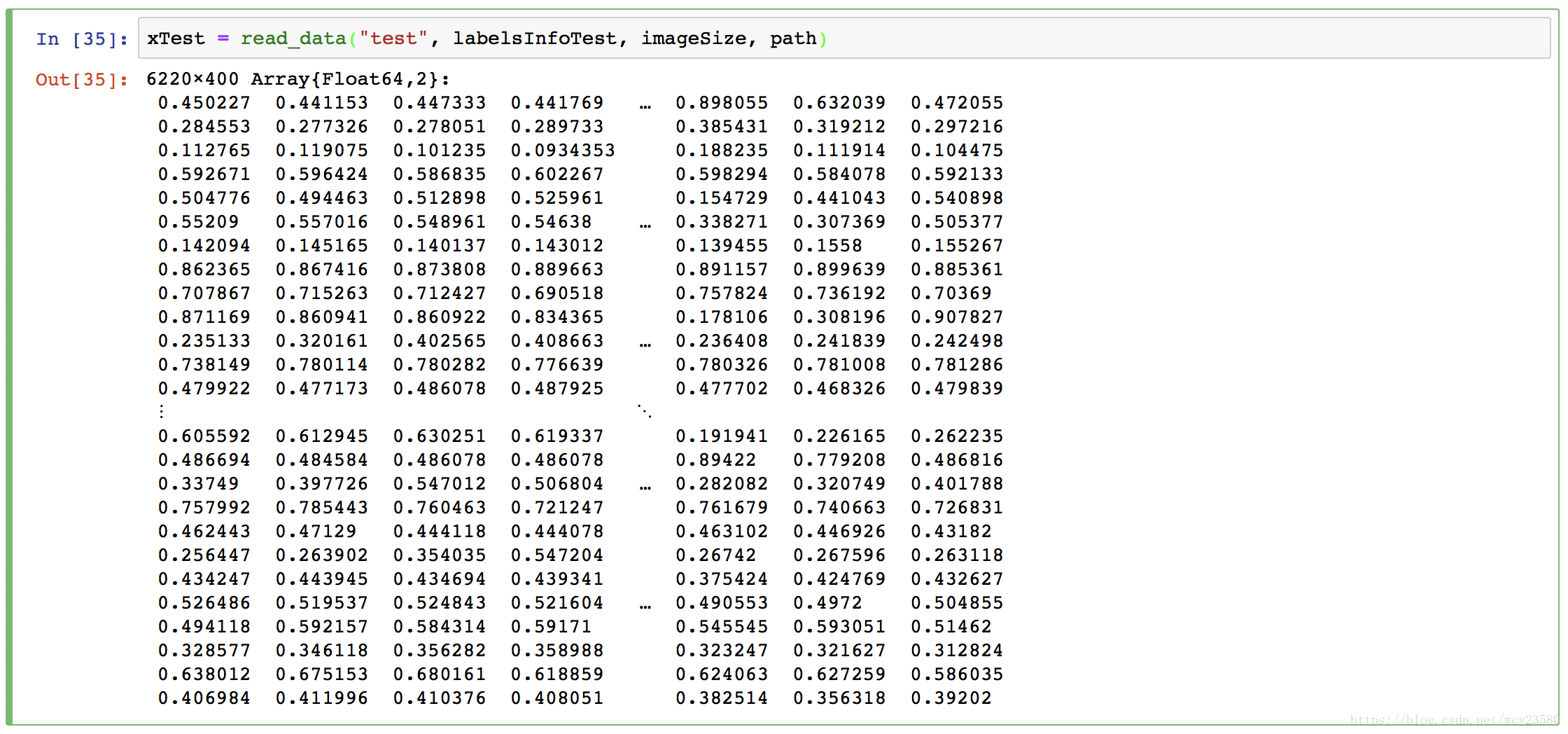
读取测试图像数据:
xTest = read_data("test", labelsInfoTest, imageSize, path)
2 训练随机森林(train RF)
训练:
model = build_forest(yTrain, xTrain, 20, 50, 1.0)
解释:
$3(20):number of features chosen at each random split
$4(50): number of trees
$5(1.0): ratio of subsampling
获得测试结果:
predTest = apply_forest(model, xTest)
转化预测结果:
labelsInfoTest.Class = Char.(predTest)
写入文件:
CSV.write("$(path)/predTest.csv", labelsInfoTest, header=true)
四折交叉验证:
accuracy = nfoldCV_forest(yTrain, xTrain, 20, 50, 4, 1.0);
println("4 fold accuracy: $(mean(accuracy))")
3 完整代码
using Images
using DataFrames
using Statistics
using DataFrames
using CSV
using DecisionTree
function read_data(type_data, labelsInfo, imageSize, path)
x = zeros(size(labelsInfo, 1), imageSize)
for (index, idImage) in enumerate(labelsInfo.ID)
nameFile = "$(path)/$(type_data)Resized/$(idImage).Bmp"
img = load(nameFile)
temp = float32(img)
temp = Gray.(temp)
x[index, :] = reshape(temp, 1, imageSize)
end
return x
end
imageSize = 400
path = "/Users/congying/cyWang/projects/julia/kaggleFirstStepsWithJulia/all"
labelsInfoTrain = CSV.read("$(path)/trainLabels.csv")
xTrain = read_data("train", labelsInfoTrain, imageSize, path)
labelsInfoTest = CSV.read("$(path)/sampleSubmission.csv")
xTest = read_data("test", labelsInfoTest, imageSize, path)
yTrain = map(x -> x[1], labelsInfoTrain.Class)
yTrain = Int.(yTrain)
model = build_forest(yTrain, xTrain, 20, 50, 1.0)
predTest = apply_forest(model, xTest)
labelsInfoTest.Class = Char.(predTest)
CSV.write("$(path)/juliaSubmission.csv", labelsInfoTest, header=true)
accuracy = nfoldCV_forest(yTrain, xTrain, 20, 50, 4, 1.0);
println("4 fold accuracy: $(mean(accuracy))")