一、Mapreduce
Mapreduce主要应用于日志分析、海量数据的排序、索引计算等应用场景,它是一种分布式计算模型,主要用于解决离线海量数据的计算问题。
核心思想是:“分而治之,迭代汇总”
Mapreduce主要由两个阶段:
map阶段:任务分解
1.读取HDFS中的文件,把输入文件按照一定的标准分片,每个输入片的大小是固定的,(默认情况下,输入片的大小与数据块的大小相同,数据块大小默认为64M(一般为64M或128M)),假设输入文件若为72M,那么该文件进行读取时,会分成64M和8M两个输入分片
2.解析成键值对,默认规则按行解析,“键”是每行起始位置(单位是字节),“值”是本行的文本内容
3.按照键进行分区,比如键表示省份,按照不同省份进行分区,需要注意的是,分区的数量就是reducer阶段任务执行的数量
4.对每个分区键值对进行排序,排序规则:首先按照键进行排序,对于键相同的,按照值排序
(对于键相同的键值对可以通过手动添加reduce方法,使数据量减少)
reduce阶段:结果汇总
1.复制多个mapper阶段任务的输出,合并成一个大数据,并对数据进行整体排序
2.对于键相等的键值对调用一次reduce方法,最后把这些键值对写入到HDFS中
其中排序、合并、分区等操作都由属于shuffle过程,mapper与reduce端是通过http协议进行数据传输。
二、Yarn
mapreduce经过一系列的优化,升级称为MR2,Yarn
它主要舍弃了MR1的Jobtrack,tasktrack,减少了Jobtrack的消耗
MR2将Jobtrack分为两部分,即资源管理和工作任务,即全局的ResourceManager(RM)和每个应用都有的NodeManager(NM),形成主从关系的计算框架。MRAppMaster负责任务的完成。
角色关系:
Client=需求
RM =甲方经理层(公司领导)
NM =乙方经理层(公司领导)
MRAppMaster =项目经理
Task = 项目组员工
容器 = 核心信息 (这块可能理解不对)
工作原理
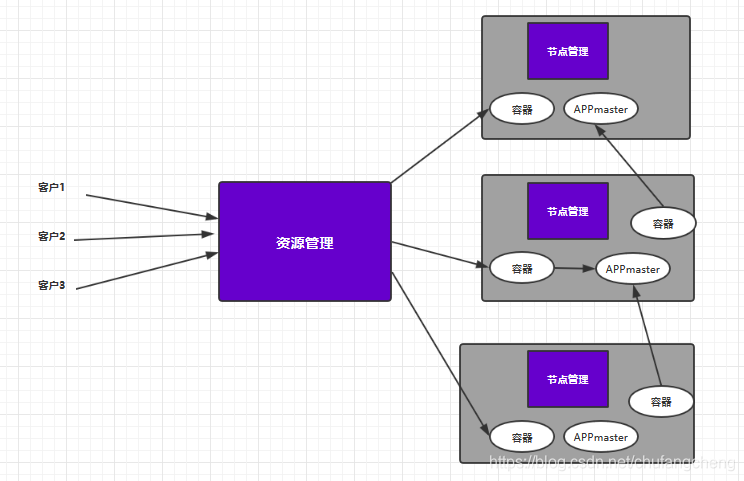
1.客户向RM发起请求 (甲方来了一个需求)
2.RM分配创建容器,通知NM启动MRAPPMaster (甲方经理层将核心信息通知乙方经理层,让乙方配备项目经理)
3.NM接受指定任务,并开辟空间启动MRAPPMaster (乙方经理层接收项目,成立项目组并配备资源与项目经理)
4.MRAPPMaster获取资源后,与NM通信,启动MapTask和reduceTask进程 (项目经理获取资源后,给项目成员分配任务)
5.任务执行,并定时向MRAPPMaster汇报任务执行情况 (项目成员执行任务,并定期给项目经理作汇报)
以上个人总结,如有不对的地方请大家指点,谢谢。