本章来简单介绍下 Hadoop MapReduce 中的 Combiner。Combiner 是为了聚合数据而出现的,那为什么要聚合数据呢?因为我们知道 Shuffle 过程是消耗网络IO 和 磁盘IO 比较大的操作,如果我们能减少 Shuffle 过程的数据量,那就可以提升整个 MR 作业的性能。我在《大数据技术 - MapReduce的Shuffle及调优》 一文中写到 Shuffle 中会有两次调用 Combiner 的过程,有兴趣的朋友可以再翻回去看看。接下来我们还是以 WordCount 为例,简单介绍下 Combiner 的作用以及何时可以设置 Combiner。
Combiner 的作用
假设有 2 个输入文件,每个文件只有一行数据,因此 map 阶段启动的 map 任务数为 2,reduce 任务的数量使用默认值 1 即可。文件内容如下:
#第一个文件内容
hello hello
#第二个文件的内容
world world
本例子仍然使用《大数据技术 - 通俗理解MapReduce之WordCount》中的代码。该 MR 作业数据传输过程如下:
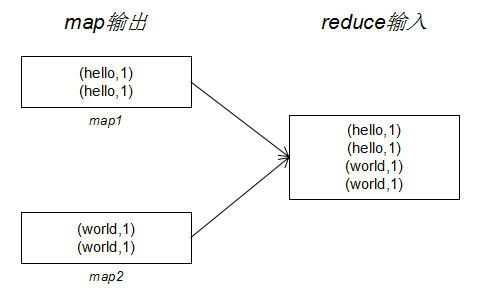
由上图可以发现,每个 map 任务的输出都有重复的 key。假设每个任务输出记录是几百万甚至几千万,重复的 key 会更多。这时如果我们要减少 Shuffle 过程传输的数据量,我们要怎么办呢?由于我们这个作业是个计数的任务,因此容易想到的方法是在 map 端输出的时候对相同的 key 先做一遍计数,这样做一来可以减少数据量,二来不影响 reduce 端的统计结果。在 Hadoop 中如果要实现上述过程需要在 job 中指定 Combiner,代码如下:
job.setMapperClass(WordCountMapper.class); //设置 map 任务的类 job.setCombinerClass(WordCountReducer.class); // 设置 Combiner job.setReducerClass(WordCountReducer.class); // 设置 reduce 任务的类
我们可以看到设置 Combiner 的 class 与 Reducer 相同,因此我们说 Combiner 不会改变 reduce 的输出结果。引入 Combiner 后,我们的 MR 作业数据传输过程如下:
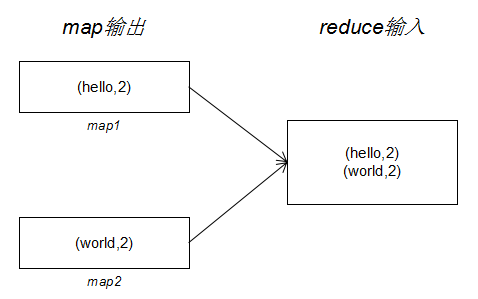
设置 Combiner 后,Shuffle 过程传输的数据量明显减少。这里就是我们在写 Shuffle 那篇文章中所说的,map 任务输出到本地磁盘时会先判断有没有设置 Combiner ,如果有会调用 Combiner 做聚合以减少写入磁盘的数据量,从而减少网络 IO。Shuffle 还有一个过程会调用 Combiner 但在上图没有体现。那就是在 reduce 复制阶段需要溢写文件的时候,因为 reduce 接收来自不同的 map 输出的数据,这时候会出现 key 相同的记录,对相同 key 进行聚合同样可以减少输出到磁盘的数据量,同时也可以减少 reduce 函数对内存的占用。
为什么要用 Combiner
读到这里我们已经清楚了 Combiner 的作用。可能有些读者会说,我在 map 函数中把相同的 key 聚合起来不一样能达到 map 输出的聚合效果吗, 同样也能减少 Shuffle 过程的网络 IO。但这种做法并不可取,原因有三:
- 这种做法 map 函数和 reduce 函数业务逻辑出现重合
- 如果 reduce 函数要做一些其他的处理逻辑,比如对输入的 key 小写转大,那么 map 函数中也要进行同样的处理
- 经过上面的介绍我们知道调用 Combiner 不止在 map 输出时会发生,reduce 复制阶段时也会发生,如果将聚合操作写在 map 函数里,reduce 复制阶段将无法聚合
但是引入 Combiner 就不会出现上述问题,这里我们总结一下为什么要引入 Combiner:
- 减少本地磁盘 IO
- 减少 reduce 端复制数据的网络 IO
- 将上述优化与业务逻辑剥离,使得作业调优与业务逻辑之间的耦合度降低
因此,个人认为 Combiner 的设计是比较优秀的。我们学习新东西的时候就是需要不断的思考为什么要这样设计,这样设计的优缺点以及不这样设计的优缺点,这样我们成长的会快。

什么时候用 Combiner
到目前为止我们已经知道 Combiner 的优势非常明显,但是不是所有的作业都可以设置 Combiner 呢?答案是否定的。对于我们的 WordCount 这个例子来说,因为是求和操作,因此在任何阶段进行求和不会影响最终的结果。但是有些作业是不行的,比如求平均值。如果在 map 输出时或者 reduce 复制阶段对一部分 key 先求了平均值,那是无法保证最终 reduce 函数输出的平均值是正确的。因此对于求最值、求和之类的统计我们可以设置 Combiner。
除了直接用 Reducer 设置 Combiner 外,我们也可以自定义 Combiner ,跟写 Reducer 一样,需要继承 Reducer<K1, V1, K2, V2>,实现 reduce 方法。只要保证最终不影响 reduce 输出结果即可。
总结
总结一下这篇文章,在优化 MR 作业的 Shuffle 时可以考虑引入 Combiner 来减少网络 IO 和磁盘 IO。但一般针对特定的统计任务才可以引入 Combiner ,如求最值、求和。同时,我们也深入分析引入 Combiner 在设计上的优势,既可以灵活应用在各个阶段进行聚合,又可以将调优与业务逻辑解耦。