1. 引言
提升(Boosting)是一种机器学习技术,可以用于回归和分类问题,它每一步产生一个弱预测模型(如决策树),并加权累加到总模型中加权累加到总模型中;如果每一步的弱预测模型生成都是依据损失函数的梯度方向,则称之为梯度提升(Gradient Boosting)。
梯度提升算法首先给定一个目标损失函数,它的定义域是所有可行的弱函数集合(基函数);提升算法通过迭代的选择一个负梯度方向上的基函数来逐渐逼近局部最小值。这种在函数域的梯度提升观点对机器学习的很多领域都有深刻影响。
提升的理论意义:如果一个问题存在弱分类器,则可以通过提升的办法得到强分类器。
2. Boosting算法基本原理
- 给定输入向量 x 和输出变量 y 组成的若干训练样本(x1,y1)…(xn,yn),目标是找到近似函数F(X), 使得损失函数L (y, F(X))的损失值最小
- L(y, F(X))的典型定义为
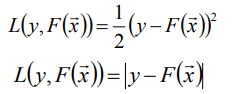
注:我们选择损失函数是和y的分布有关的,我们习惯选择第一个损失函数,这是我们是先验性认为y是服从正态分布的;当我们选择第二个损失函数我们是认为y服从拉布拉斯分布。 - 确定最优函数F*(X),即(能够使损失函数值最小化的函数):
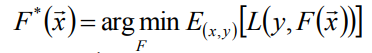
- 假定F(X)是一组基函数f(X)的加权和:
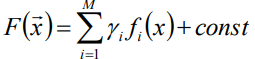
Boosting算法推导
目标:梯度提升方法寻找最优解,使得损失函数在训练集上的期望最小。
-
给定常函数F0(x):
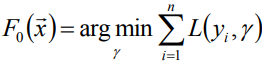
-
以贪心的思路扩展得到Fm(x):
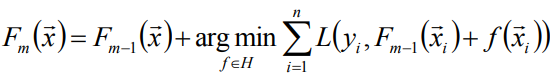
-
因为贪心法在每次选择最优基函数f时仍然困难,在这里使用梯度下降的方法近似计算。将样本带入到基函数f中得到f(x1),f(x2),f(x3)…f(xn),从而L退化为向量L(y1,f(x1)), L(y2, f(x2))…L(yn, f(xn)
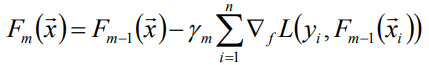
-
上式中的权值γ为梯度下降的步长,可使用线性搜索求最优步长:
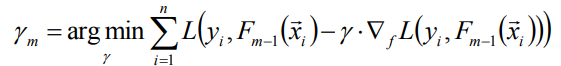
-
初始化给定模型为常数
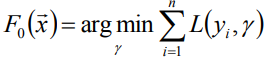
-
对于m=1到m
(1) 计算伪残差
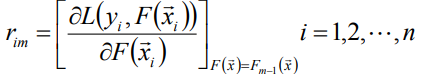
(2)使用数据计算拟合残差fm(x)
(3)计算步长γ:
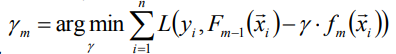
此时(3)已经转化为一维优化问题
(4)更新模型

3. GBDT( Gradient Boosting Decison Tree)
概要
- 梯度提升的典型基函数即决策树(特别是CART)
- GBDT的提升算法与上类似 f(x)即tm(x):
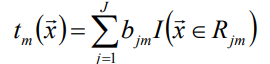
一个树最重要的就是叶子节点和他的权值,其中bjm的预测值(权值),I表示所属叶子节点。
算法和上述提升算法类似但更为优化;
参数设置和正则化
- 对训练集拟合过高会降低模型的泛化能力,需要使用正则化技术来降低过拟合。对于复杂模型增加惩罚项,如:模型复杂度正比于叶节点数目或者叶节点预测值的平方和等;决策树剪枝。
- 叶节点数目控制了输的层次,一般选择4<=j<=8
- 叶节点包含的最少样本数目。防止出现过小的叶节点,降低预测方差
- 梯度提升迭代次数M。增加M可降低训练集的损失值,担忧过拟合风险。
- 交叉验证
衰减因子,降采样
衰减Shrinkage:
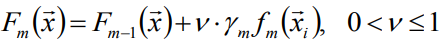
其中v称为学习率,v=1即为原始模型;推荐选择v<0.1的小学习率,单会造成迭代次数增多。
GBDT小结
- 损失函数是最小平方误差,绝对值误差等,侧围回归问题;而误差函数换成多类别Logistic似然函数,侧围分类问题。
- 对目标函数分解成若干基函数的加权和,是最常见的技术手段:神经网络,径向基函数,傅里叶/小波变换,SVM中都有它的影子。
4. XGBoost
XGBoost与GBDT
相比于GBDT总的来说XGBoost的功能更加强大,性能更加问题,适用范围更加广,但它们仍各有优缺点。
- 传统的GBDT是以CART作为基分类器,特指梯度提升决策树算法。而XGBoost还支持线性分类器(gblinear) 这个时候XGBoost相当于带L1和L2正则化项的logistic回归(分类问题)或者线性回归(回归问题)
- 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。
- xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
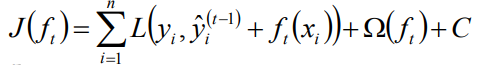
其中正则项控制着模型的复杂度,包括了叶子节点数目T和leaf score的L2的平方: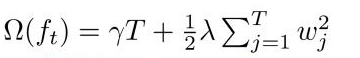
- xgboost中树节点分裂时所采用的公式:
Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(传统GBDT的实现也有学习速率) - 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
- 对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
- xgboost工具支持并行。注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。(特征粒度上的并行,block结构,预排序)
这篇博客对于XGBoost中目标函数的优化原理,计算方法没有详细说明,感兴趣的可以自行查阅资料。
5. LightGBM
lightGBM:基于决策树算法的分布式梯度提升框架。lightGBM与XGBoost的区别:
总的来说相较于XGBoost速度更快,内存消耗更低。
-
切分算法(切分点的选取)
占用的内存更低,只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。
降低了计算的代价:预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data#feature)优化到O(k#features)。(相当于LightGBM牺牲了一部分切分的精确性来提高切分的效率,实际应用中效果还不错)
空间消耗大,需要保存数据的特征值以及特征排序的结果(比如排序后的索引,为了后续快速计算分割点),需要消耗两倍于训练数据的内存
时间上也有较大开销,遍历每个分割点时都需要进行分裂增益的计算,消耗代价大 -
对cache优化不友好,在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
-
XGBoost使用的是pre-sorted算法(对所有特征都按照特征的数值进行预排序,基本思想是对所有特征都按照特征的数值进行预排序;然后在遍历分割点的时候用O(#data)的代价找到一个特征上的最好分割点最后,找到一个特征的分割点后,将数据分裂成左右子节点。优点是能够更精确的找到数据分隔点;但这种做法有以下缺点
LightGBM使用的是histogram算法,基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点;优点在于 -
决策树生长策略上:
XGBoost采用的是带深度限制的level-wise生长策略,Level-wise过一次数据可以能够同时分裂同一层的叶子,容易进行多线程优化,不容易过拟合;但不加区分的对待同一层的叶子,带来了很多没必要的开销(因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂)
LightGBM采用leaf-wise生长策略,每次从当前所有叶子中找到分裂增益最大(一般也是数据量最大)的一个叶子,然后分裂,如此循环;但会生长出比较深的决策树,产生过拟合(因此 LightGBM 在leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合)。 -
histogram 做差加速。一个容易观察到的现象:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。利用这个方法,LightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。
-
直接支持类别特征:LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1展开。并在决策树算法上增加了类别特征的决策规则。
-
分布式训练方法上(并行优化)
在特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信;
在数据并行中使用分散规约(Reduce scatter)把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。基于投票的数据并行(Parallel Voting)则进一步优化数据并行中的通信代价,使通信代价变成常数级别。
特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
小结:算法不分优劣,适合的就是最好的。