word count demo
引入jar
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
</dependency>
wc代码
package com.tiffany;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* https://blog.csdn.net/dream_an/article/details/54915894
* User: jasperxgwang
* Date: 2018-10-10 11:24
*/
public class SparkWordCount {
public static void main(String[] args) {
if (args.length < 1) {
System.err.println("Usage: JavaWordCount <file>");
System.exit(1);
}
// 第一步:创建SparkConf对象,设置相关配置信息
SparkConf conf = new SparkConf();
conf.setAppName("JavaWordCount");
// 第二步:创建JavaSparkContext对象,SparkContext是Spark的所有功能的入口
JavaSparkContext sc = new JavaSparkContext(conf);
// 第三步:创建一个初始的RDD
// SparkContext中,用于根据文件类型的输入源创建RDD的方法,叫做textFile()方法
JavaRDD<String> lines = sc.textFile(args[0], 1);
// 第四步:对初始的RDD进行transformation操作,也就是一些计算操作
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairRDD<String, Integer> wordCounts = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordCounts.foreach(new VoidFunction<Tuple2<String, Integer>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1 + "------" + wordCount._2 + "times.");
}
});
sc.close();
}
}
maven打包
打包好后上传jar包到服务器
clean package -Dmaven.test.skip=true
执行
创建测试目录
[hadoop@hadoop1 test]$ hdfs dfs -mkdir /input
[hadoop@hadoop1 test]$ hdfs dfs -ls /
drwxr-xr-x - hadoop supergroup 0 2018-08-13 11:13 /hbase
drwxr-xr-x - hadoop supergroup 0 2018-10-10 16:42 /input
drwxr-xr-x - hadoop supergroup 0 2018-04-08 10:40 /out
-rw-r--r-- 3 hadoop supergroup 2309 2017-08-06 19:21 /profile
drwx-wx-wx - hadoop supergroup 0 2018-04-08 10:39 /tmp
drwxr-xr-x - hadoop supergroup 0 2017-09-03 19:18 /user
上传测试文件
[hadoop@hadoop1 data]$ hdfs dfs -put test.txt /input
查看测试文件
[hadoop@hadoop1 data]$ hdfs dfs -cat /input/test.txt
hello world
hello spark
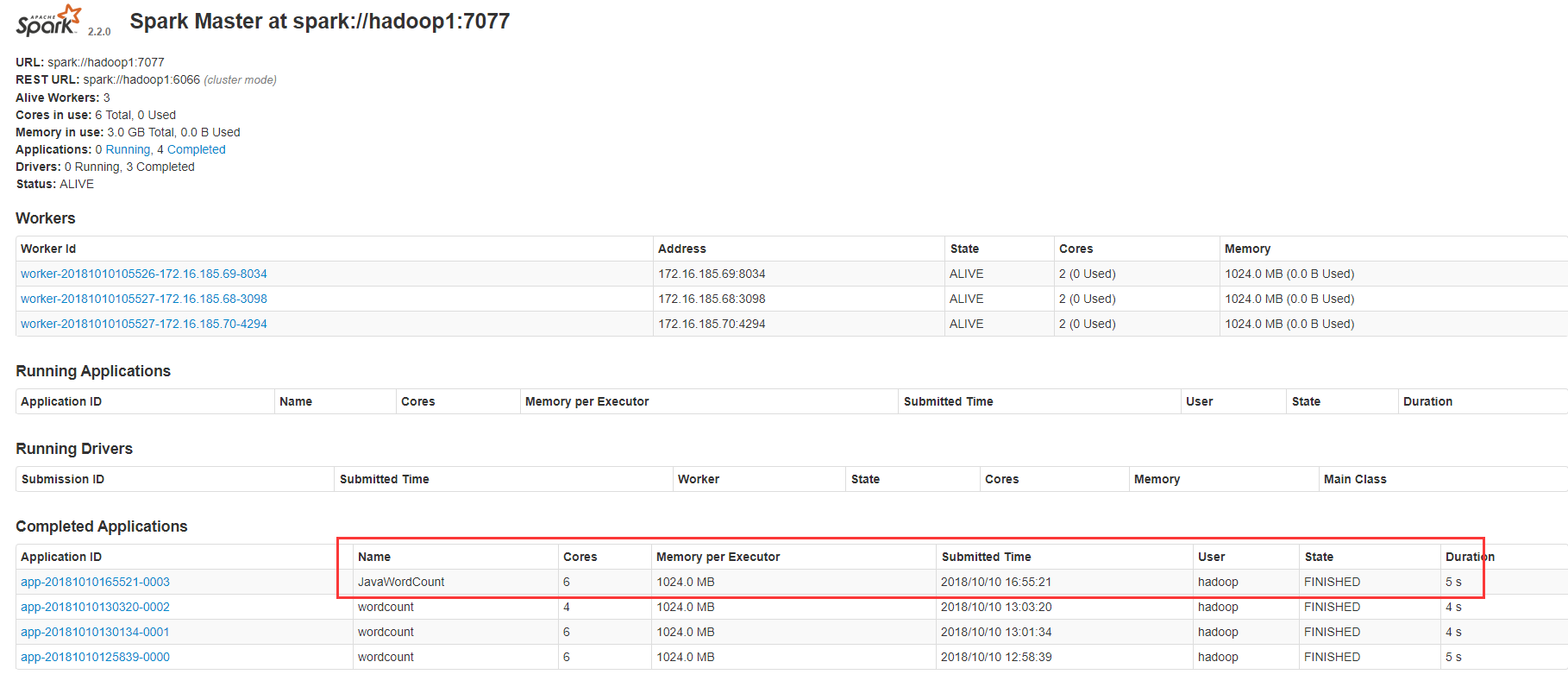
standalone集群模式-client模式
[hadoop@hadoop1 jars]$ /data/spark-2.2.0-bin-hadoop2.6/bin/spark-submit --class com.tiffany.SparkWordCount --master spark://hadoop1:7077 /data/spark-2.2.0-bin-hadoop2.6/examples/jars/Spark-1.0-SNAPSHOT.jar hdfs://hadoop1:9000/input/test.txt
standalone集群模式-cluster模式
[hadoop@hadoop1 jars]$ /data/spark-2.2.0-bin-hadoop2.6/bin/spark-submit --class com.tiffany.SparkWordCount --master spark://hadoop1:7077 --deploy-mode cluster /data/spark-2.2.0-bin-hadoop2.6/examples/jars/Spark-1.0-SNAPSHOT.jar hdfs://hadoop1:9000/input/test.txt
Running Spark using the REST application submission protocol.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
18/10/10 17:01:47 INFO RestSubmissionClient: Submitting a request to launch an application in spark://hadoop1:7077.
18/10/10 17:01:58 WARN RestSubmissionClient: Unable to connect to server spark://hadoop1:7077.
18/10/10 17:01:58 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
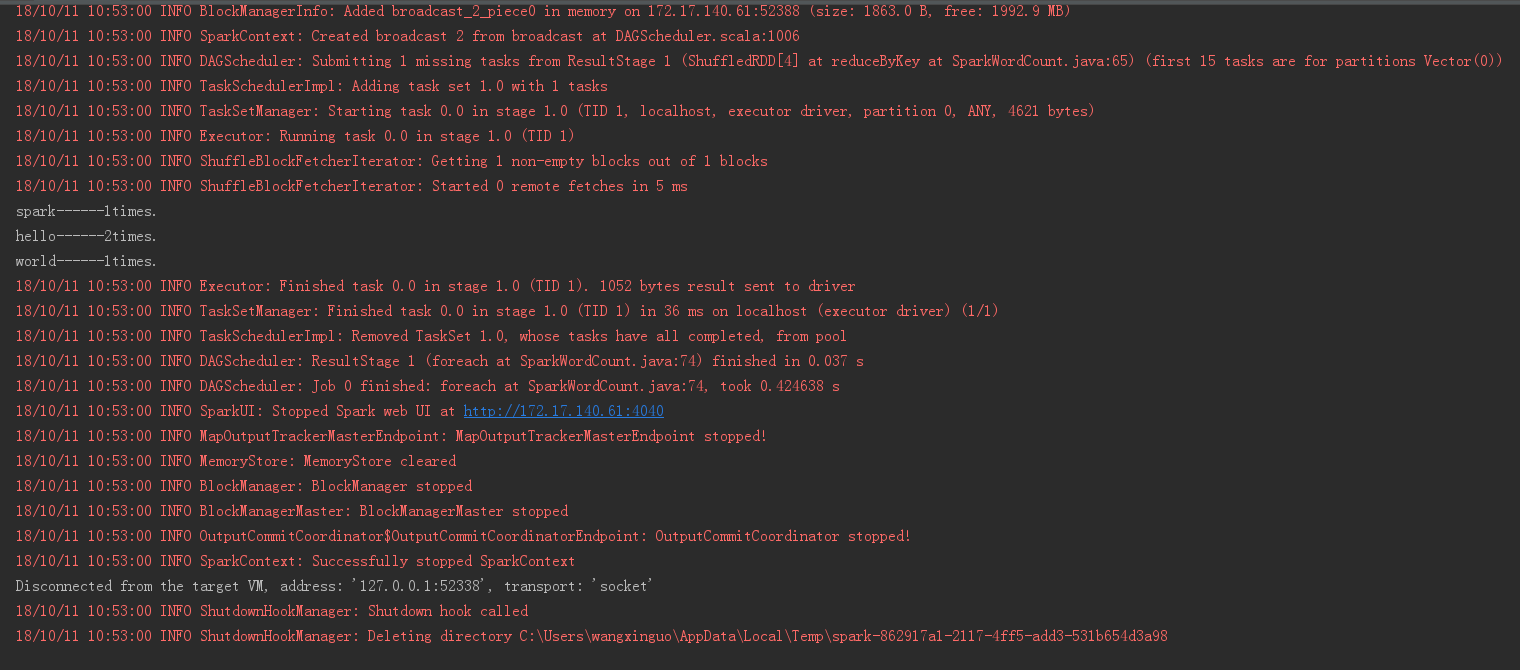
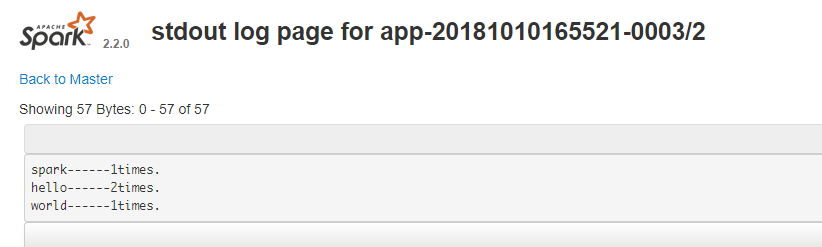
运行结果
运行结果
IDEA local
设置IDEA运行项的Configuration中的VM opthion 增加-Dspark.master=local
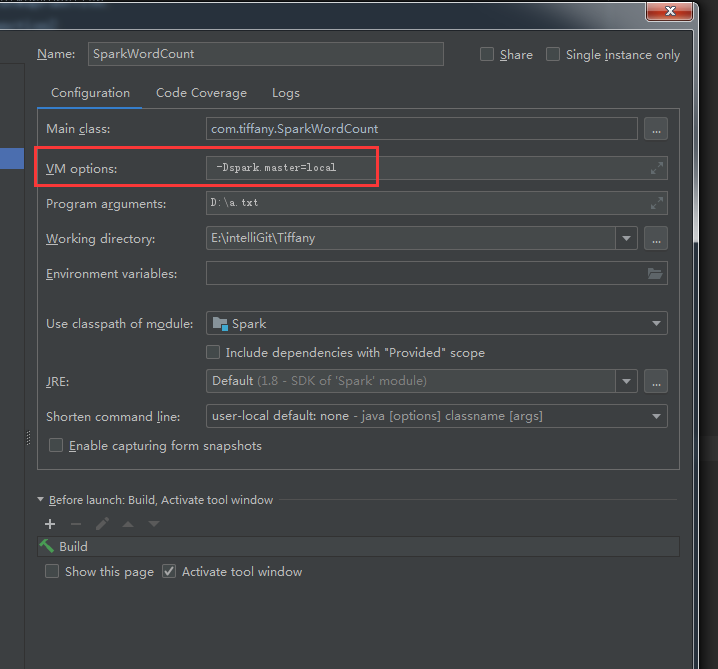
运行结果