首先,从官网下载spark-1.6.0源码,使用intellij IDEA将源码import导入,选择使用maven构建项目,我选用的开发工具包是jdk1.7.0_03和scala-sdk-2.10.4,然后等待IDEA自动下载并解析相关依赖。然后编译任意Example,我选择的是JavaWordCount文件,此时程序会报如下错误:
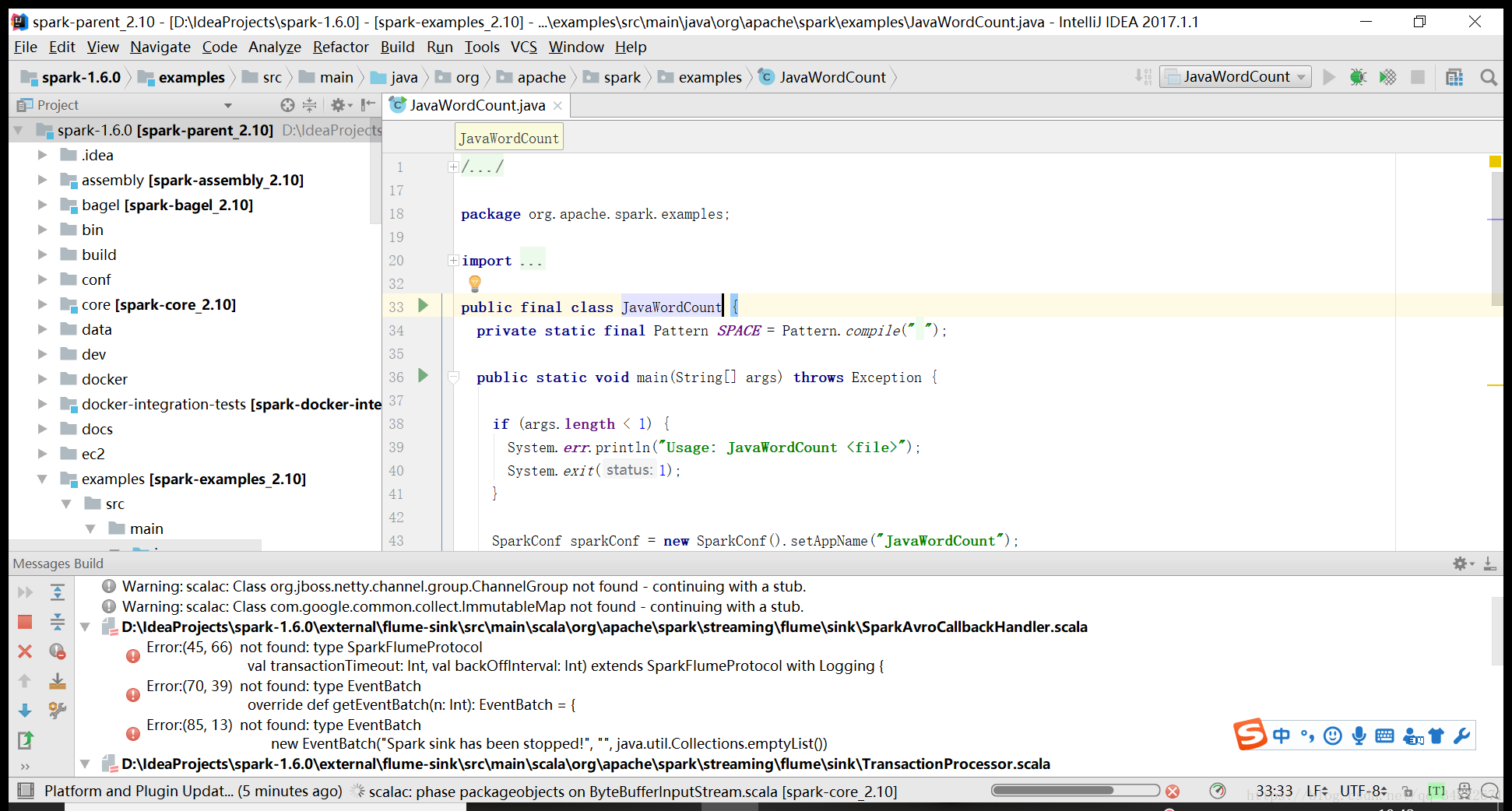
进入File->Project Structure->Libraries,单击加号选择From Maven添加spark-streaming-flume-sink_2.10最新的包到对应模块即spark-streaming-flume-sink_2.10中。
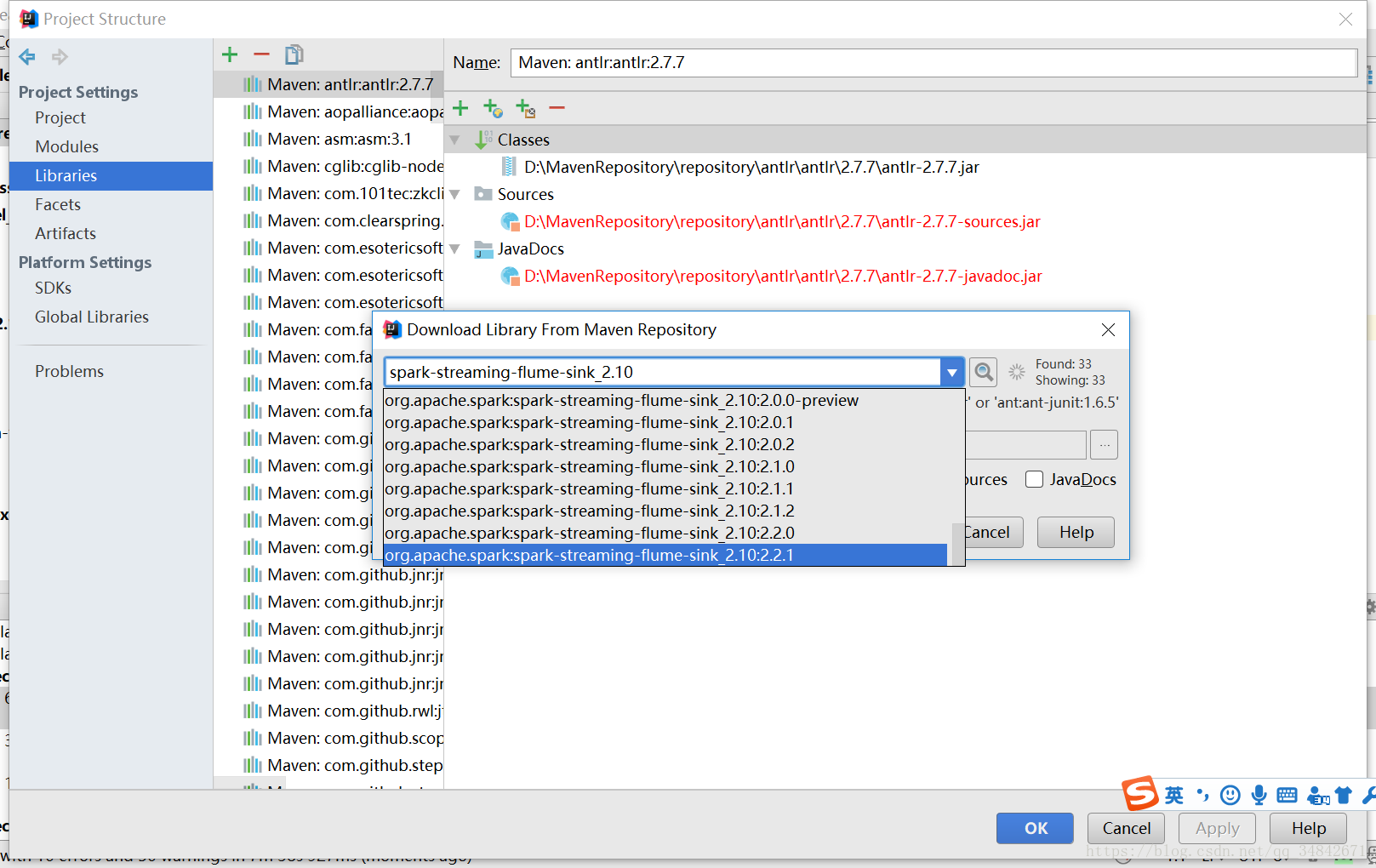
同理添加spark-streaming-flume_2.10最新的包到对应模块,再次编译,会出现如下错误:
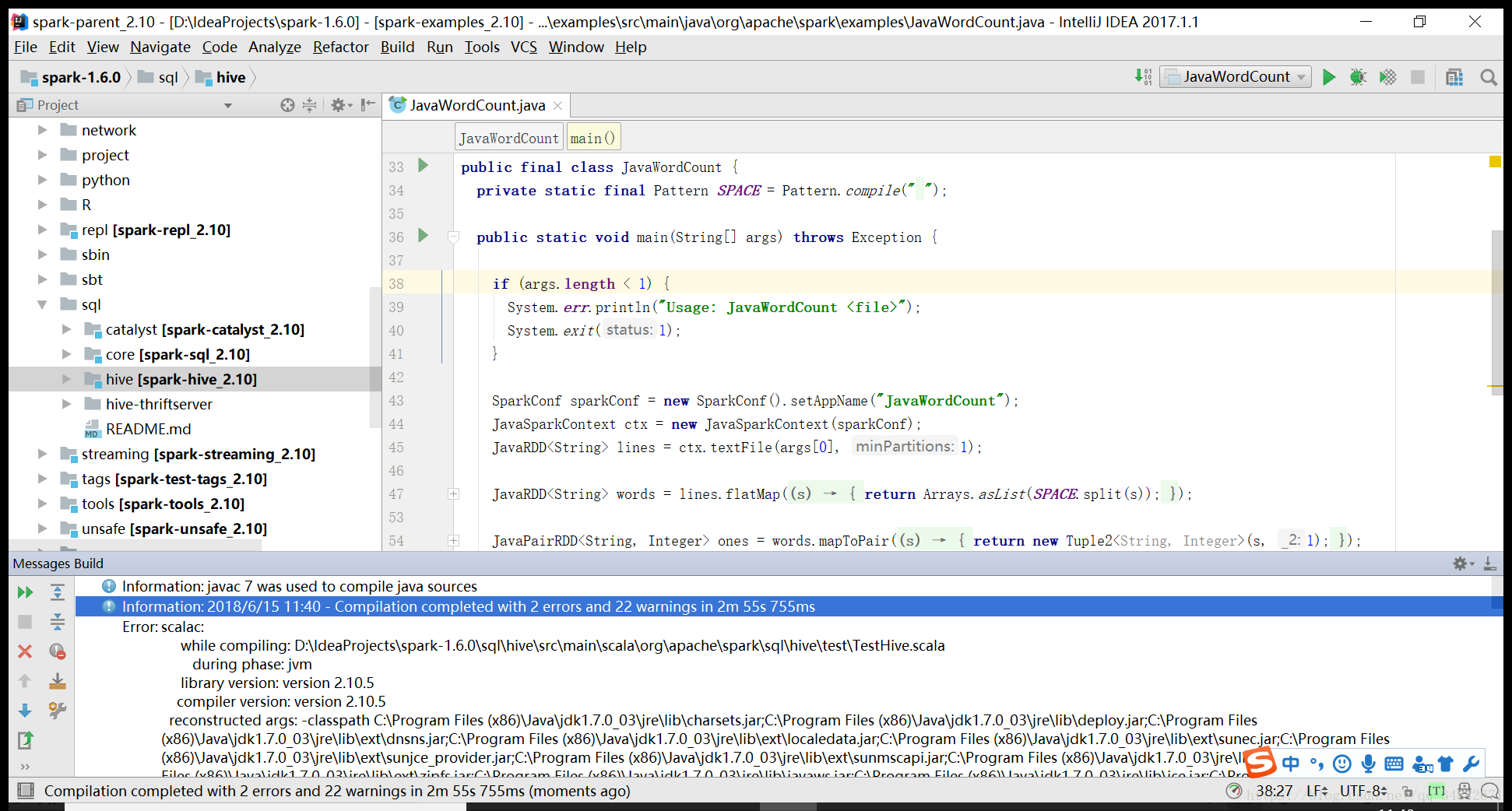
然后将spark-hive模块关闭(在Modules中将hive模块Excluded),把报错的地方删除,编译成功。运行JavaWordCount程序,会出现如下错误:
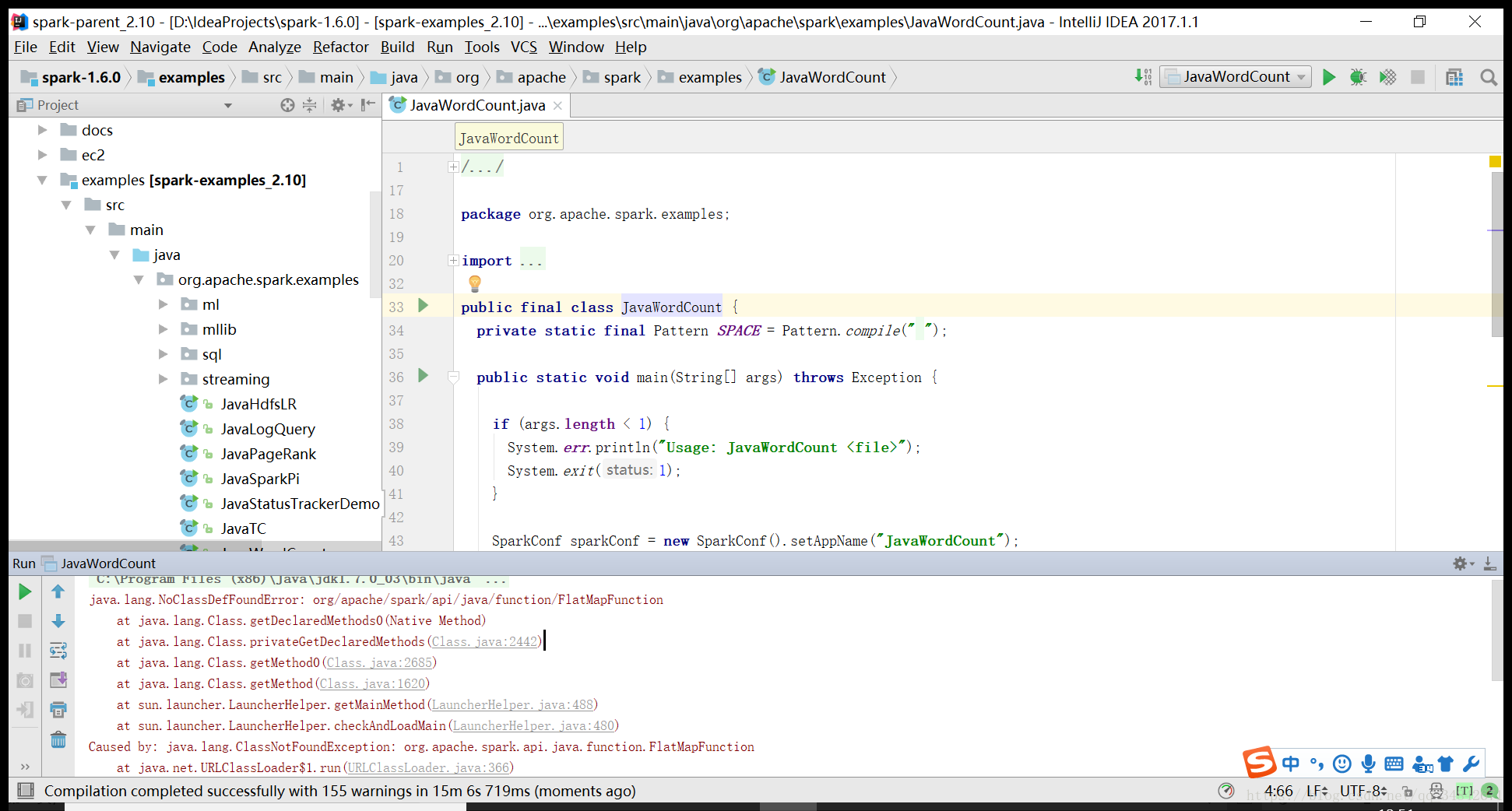
进入File->Project Structure->Libraries,在Modules中的spark-example-2.10中把所有依赖的Scope是Provided和Runtime的全部改成Compiled,Scope是Text的不需要修改,如下:
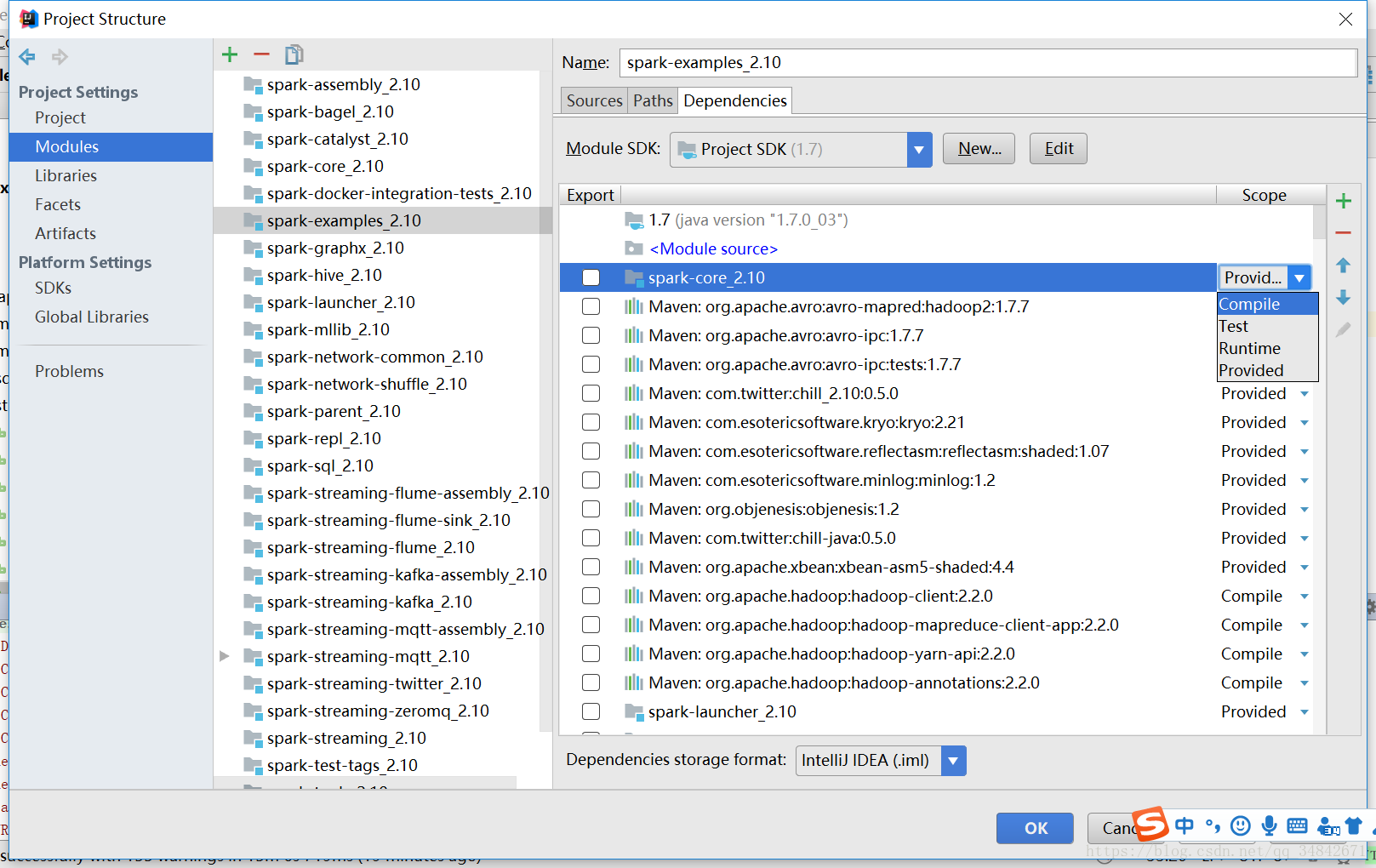
此时运行程序会出现如下错误:
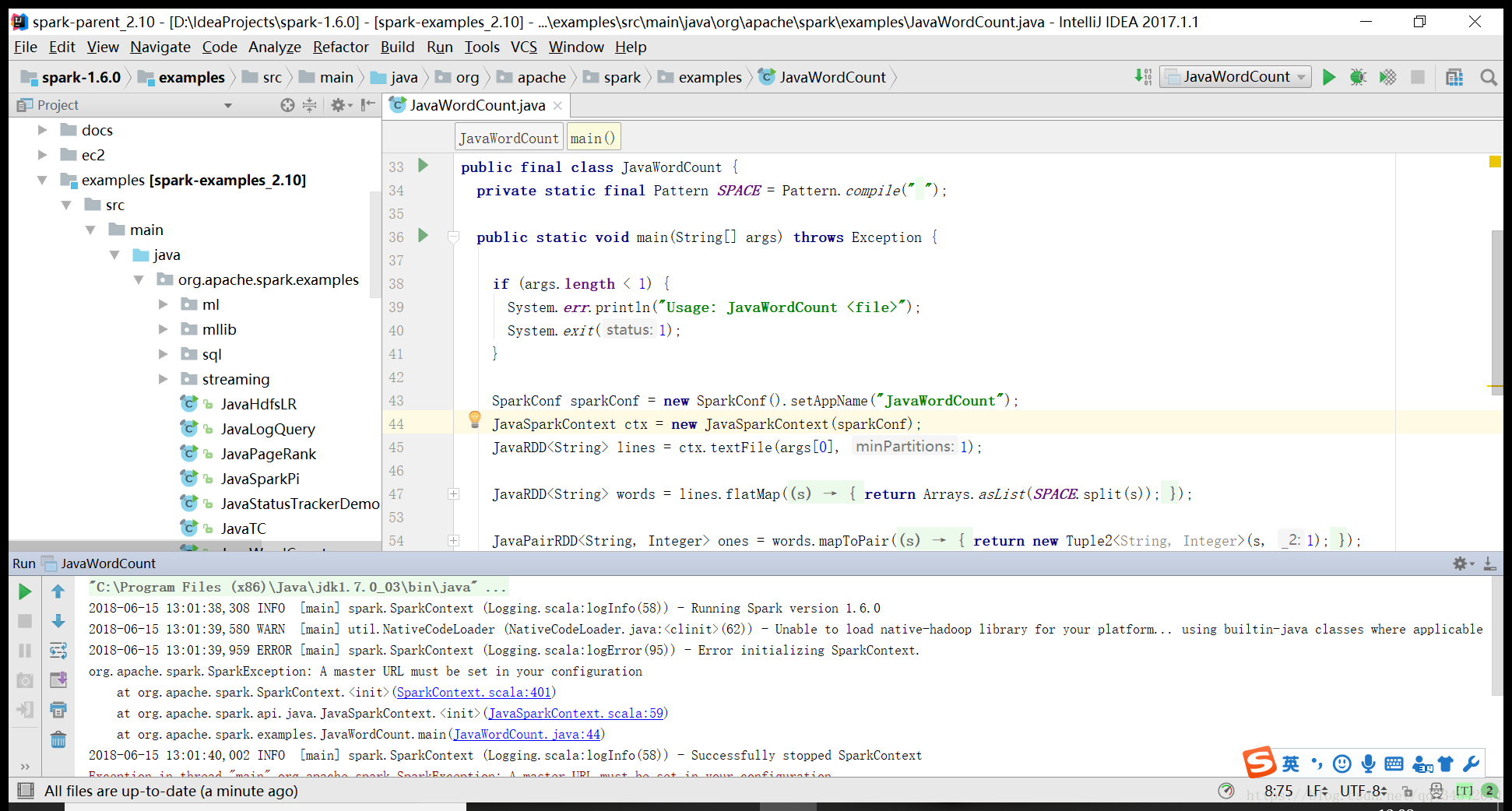
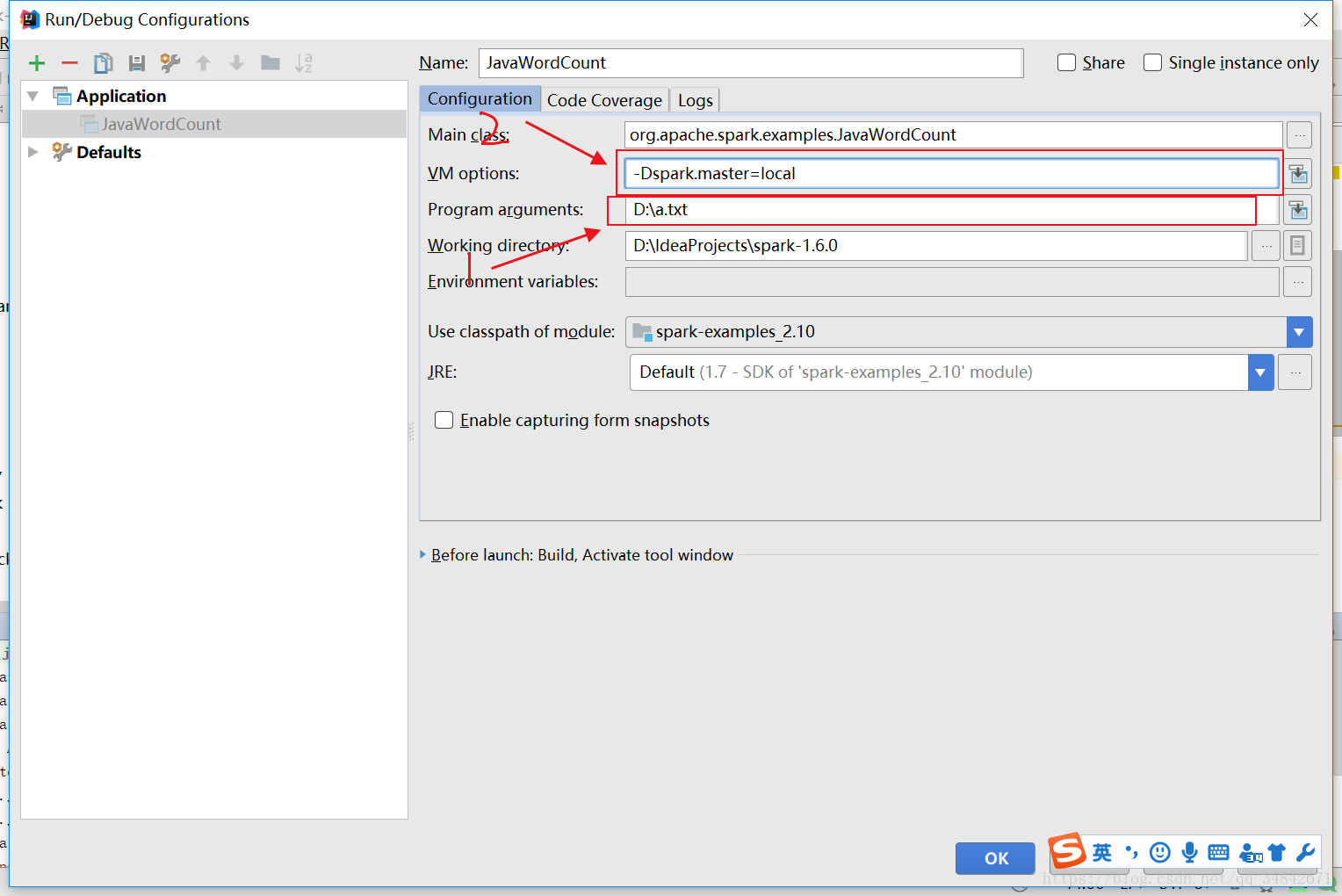
对程序运行进行配置,输入文本路径参数,VM options中输入“-Dspark.master=local”,如下图,指示本程序本地单线程运行,再次运行即可成功。
上述若干错误由于机器环境不同,错误不一定会全部复现,若没有出现某个错误则可以跳过该错误的解决方法,继续往下阅读。
使用 IntelliJ Idea搭建Spark源码阅读环境
猜你喜欢
转载自blog.csdn.net/qq_34842671/article/details/80696865
今日推荐
周排行