时间一周周的真是过的好快,又到老王扯技术淡的时间了,快回来听老王扯淡吧~ 当年老王刚刚走出学校踏进社会的时候,一个百度的老同事(人称瀚哥,虽然不是我的直接导师,也可以算半个了,后来对我帮助挺大的~)就问我,觉得在学校的时间过的快嘛?我说快啊,你看这本科+研究生七年,一晃眼就过了。他说,你来工作了就会发现,工作以后,时间更快。现在回想一下,我工作都8年了,当年进公司的那一刻还历历在目……
不知道为啥,突然就写出了上面这些文字,可能是人老了都爱回忆往事吧。好了,不扯闲淡了,开始我们的技术话题吧~
老规矩,我们还是把蓝图摆出来,看看我们今天聊啥:

不错,我们今天聊点有意思的东东,跟现在移动互联网息息相关,并且平时都能用得上的一些东东——分布式体系、组件和一些常见的逻辑系统的设计(是不是听起来觉得很高大上啊。老王第一次听“分布式”三个字,就觉得牛逼,后来去百度就是为了学这个技术)。不过大家不用被这几个字吓住了,其实没什么可怕的,无非就是多了些模式或者思想,最根本的还是计算机的那些基础知识,比如:网络、操作系统、算法等等。所以,想要了解究竟的话,跟老王一起来吧~
铺垫:what & why
这里还是先抛问题:什么是分布式?为什么要用分布式?
百科上对于这个问题的解释其中一段是这样描述的:分布式处理则是将不同地点的,或具有不同功能的,或拥有不同数据的多台计算机通过通信网络连接起来,在控制系统的统一管理控制下,协调地完成大规模信息处理任务的计算机系统。在知乎上也有很多这方面的讨论。
老王没有专门去总结这几个字组成的词的定义,因为这个范围实在太广,可说的东西太多。老王是个务实的人,想问题也不是那么高端,所以自己对分布式的理解是:把任务的计算、数据的存储等操作放到不同的地方去处理,当产生结果或者需要使用时,又从多个地方将计算结果、数据汇聚起来的这样的一个体系。打个比方说,我现在要计算1*2*3*……*10的值,怎么办呢?我们有很多种办法,比如:
1、循环:for (int i = 1, s = 1; i <= 10; i++) {s *=i;};
2、递归:int s(int k) {return k <= 1 ? 1 : k * s(k - 1);};
以上这些都是我们传统的计算方式,他们都是将程序运行在一台机器上来得到计算结果。而我们也可以采用另外一种方式,比如,我们现在有2台机器,那我就可以让每一台机器计算一部分结果,最后再把他们合并起来计算一次。具体的,我们让机器m1计算s1=1*2*3*4*5,让机器m2计算s2=6*7*8*9*10,最后再随便挑一台,将他们的结果合并相乘s=s1*s2。这是不是也是一种思路呢?
那为什么需要分布式呢?老王个人觉得,用分布式的理由是资源不够用。这里的资源,包括计算用的cpu资源,也包括内存资源,或者是文件存储资源,也可以是各种外设资源等等。比如,我们要计算(1*2*3*……*1000000000000) %1000000000001的结果,在不推算任何公式的情况下,用循环或者递归在短时间内比较难算出结果,就可以用更多的计算机去算,然后将结果组合起来;又比如,我们要存储1P的数据(1P = 2^10T = 2^20G = 2^30M = 2^40K = 2^50B),可能一块硬盘存不下,我们就可以分到多个机器去存储,要的时候,再找不同的机器去取。所以,如果资源足够的情况下,我们直接单台机器就可以解决问题;如果资源不够的情况下,我们就需要用到分布式。不知道老王说清楚没有?
那具体到互联网这个环境上来讲,对于每一个稍微大型一点的网站或者是app的服务器端,每秒钟都会有数以万计的用户来请求数据。如果是单一的一台服务器,可能很难扛住这样的请求压力(如果只请求很简单的不变的资源,比如一个小图标,则还是有可能的),就需要把用户的请求分散到多个不同的服务器去处理,这样,我们就能承载更多的用户的请求,对吧。
好了,前面的铺垫做好了,接下来就一起来聊聊我们怎么做。
next: how
这个话题就更开放了,每个公司、每个大型的网站都有自己的做法,有可能方式都还不太一样,所以老王准备讲讲自己接触到的一些做法,希望能对大家有所帮助。如果说的不对的地方,还请大家指正~
按照老王画的蓝图,大体上想分成四个方面来介绍:分布式架构、分布式组件、通用逻辑系统和专有逻辑系统。分布式架构主要是解决如何把资源组合起来进行计算、存储等;而其中要组合起来用到的部件,就是我们的组件;有一些分布式的系统是现在互联网上比较通用的,比如消息推送、内容聚合等;而有一些则是跟各个公司或者网站业务紧密结合的,比如:抢火车票(大家是否都经历过啊)。接下来我们就相对详细讲讲这几个东东。
分布式架构
老王刚刚去百度搜了一下“分布式架构”,他告诉老王大概有7,360,000这么多个网页,可见这是多么广的一个话题。四年前,老王写了一篇文章《蚂蚁变大象:浅谈常规网站是如何从小变大的》(刚刚我也去搜了一下这个文章,百度上有15,400多篇转载),这篇文章大约几万字,差不多比较详细讲述了老王一步步经历的网站从小变大的过程。有兴趣的同学可以去百度上搜来看看,或者等待老王把这篇文章优化以后,再在微信里分享给大家。
鉴于现在正在写的这篇文章是一个概览,所以老王先概要的讲讲自己理解的分布式架构(要看详细的,继续关注老王的微信:simplemain哦)。有些偷懒了,所以有一部分是借鉴我当年写的文章,哈哈哈~

我们一般把整体的架构分成三层,即:访问层、逻辑层和数据存储层。有点类似于我们常提到的MVC模式。
1、访问层:他的作用是接受用户的连接请求,读取用户请求数据,并在组织好逻辑数据后往后转发。这一层的难点,主要是要接收大量用户的连接请求,而这些请求很大部分又是慢请求(相对于cpu运行速度而言),如果处理不好,就会造成大量的连接阻塞,从而使得用户看起来我们的服务连接不上。因此,这一层用到的最主要的知识,就是我们在中篇提到过的计算机网络&操作系统的知识。
我们来算一个帐哈,如果每秒要同时接收N个用户的请求,此时如果N比较小(比如:100),那么我们只需要一台稍微好一点的服务器(比如:8核8G内存),就可以应对。如果N比较大(比如:10000),那么一台机器就肯定不行,我们就需要多机来解决这个问题。打比方说,我们有K台服务器,每台服务器能承受最大R个请求,那么要满足每秒N个请求,就需要有 N <= R * K,对吧~
要做到这一点,要么提升R,要么提升K,要么同时提升R和K。如果要提升R,就需要去提升网络服务模型的处理能力;如果要提升K,我们需要要良好的体系架构支持,因为如果你的架构不够好,那么机器越多,你的管理难度越大(1台,10台,100台,1000台……服务器的管理难度是完全不一样的)。其中,提升R的这部分,我们在中篇已经有过粗略的介绍,这里就重点讲讲提升K的这一部分。
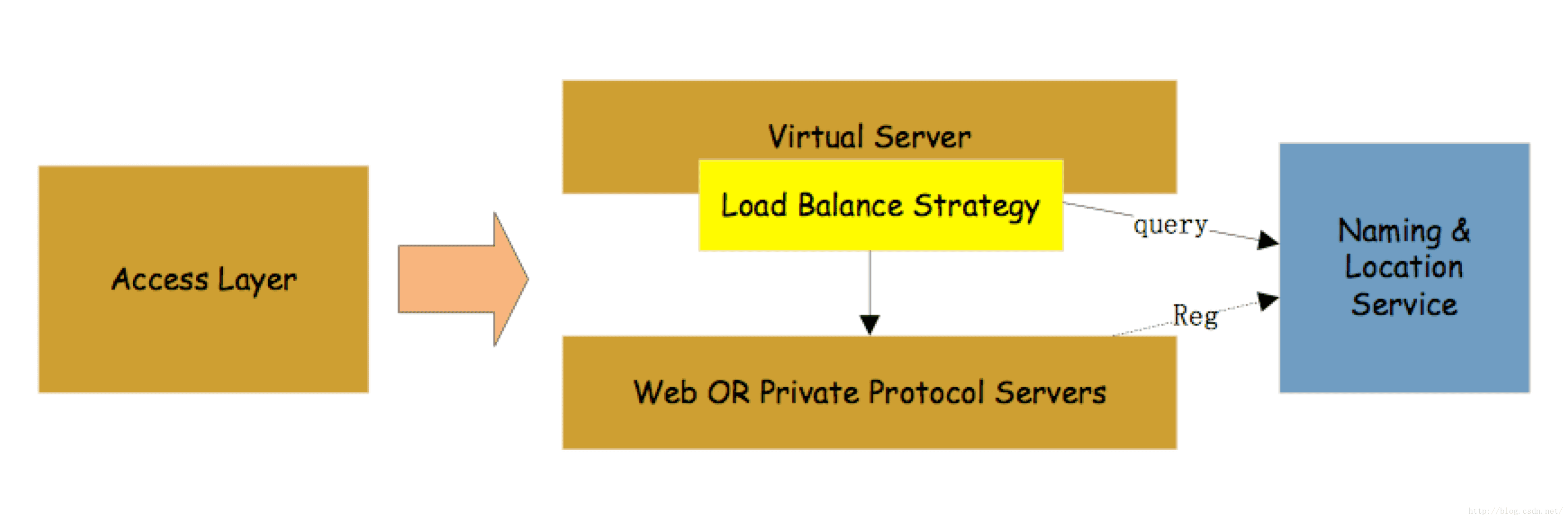
我们把接入层再拆分一下,可以用几个部分来表示:虚拟server、web服务或者私有协议server和命名/定位服务。
这里的虚拟server就像是虚拟的主机一样,每个虚拟server对外有一个IP,而在他的后面连接了大量的真实服务器。他用来对外屏蔽内部的实现细节,一般工作在网络层(IP协议所在那一层)和传输层(TCP协议那一层),他能接收大量的IP报文,然后根据一定的负载均衡策略,将这些请求报文转发给后端真正的web服务器或者是socket服务器。最常见的虚拟server就是LVS(Linux Virtual Server),当年在百度的时候,内部的软件四层设备用的就是基于他改造的,现在比较火的阿里云的SLB的四层转发也是用的这个。有了这个东东,我们就可以只暴露少量的IP给外界,而将大量的web服务器隐藏在系统内部。就像我们常用的代理服务器一样,你的连接他,他再连接后面真实的服务器。
而web服务器我们现在常用的是nginx,他轻便、稳定、负载能力强,所以现在基本上是web服务器的不二人选。阿里基于nginx修改了一个Tengine的服务器,也是用到阿里云里面了。相比起来,原来的老大哥apache,现在就显得有些臃肿,并且负载能力要差不少。两者的差别主要在于服务模型不一样。
为了让大量的web服务器方便管理,我们一般需要有一个命名/位置服务,他的作用就是统一管理后面这些web服务器,当请求来了以后,告诉虚拟Server,后面有哪些web服务器。如果没有他,我们就需要一个个的服务器去配置,这是多么恐怖的噩梦。
将这三者组合起来,就可以构建比较强大的接入层。随着流量的增加,我们可以通过增加web服务器的数量来应对(一般virtual server只做转发,压力不会太大,瓶颈可能会发生在带宽上)。当接入层不再是我们瓶颈的时候,我们就将压力传递到了逻辑层。
2、逻辑层:当访问层将数据接下来以后,就会把完整的用户请求转发到逻辑层,用来做真正的逻辑处理。
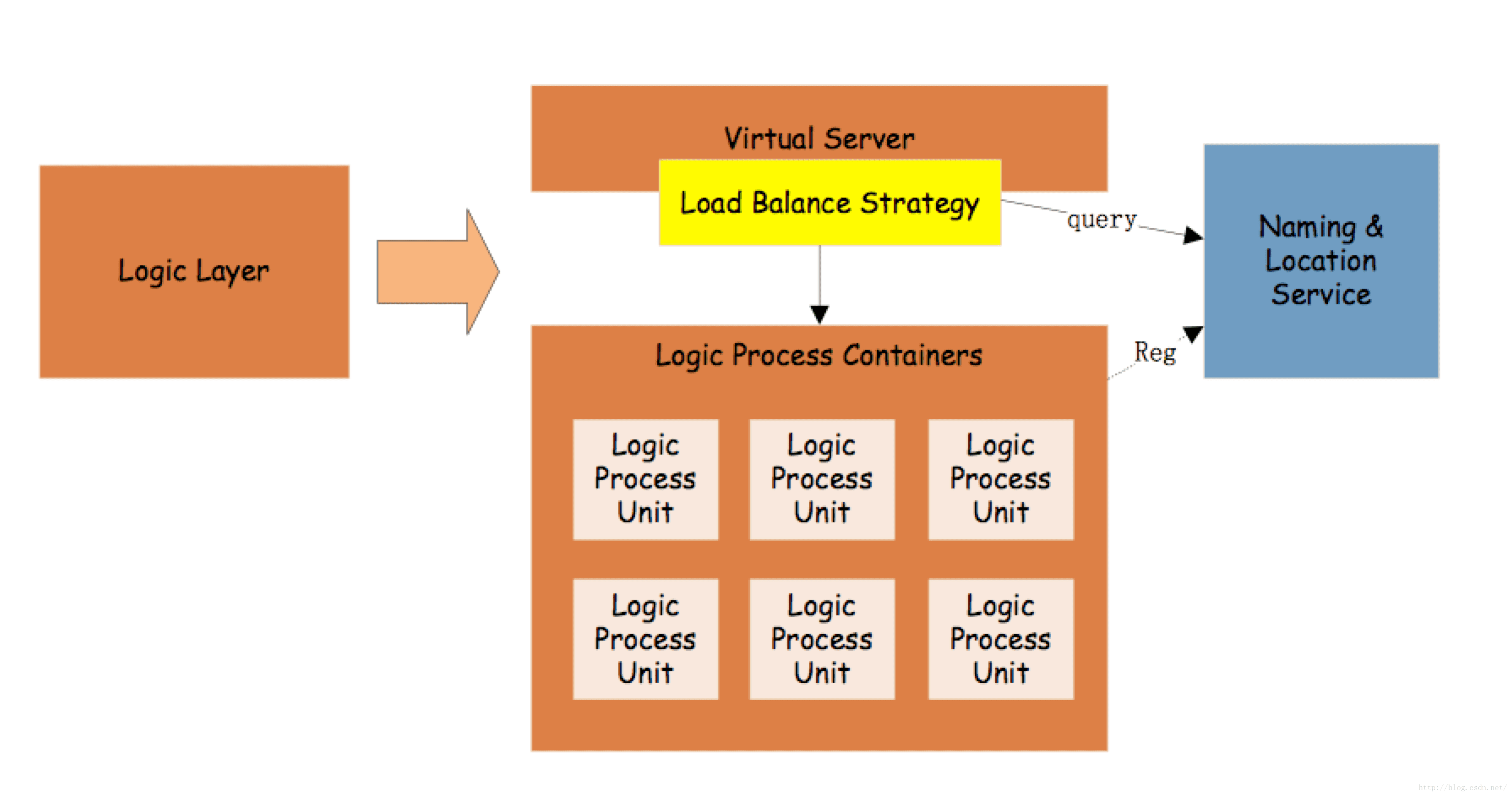
逻辑层的整个分布和接入层差不多,也大体分成3个部分:虚拟server、逻辑处理器和命名/位置服务。
虚拟server我们之前提过了,在这里是一个可选项,如果有他,则可以对外提供较少的服务IP;如果没有他也是可以的,只不过会暴露很多具体的真实server。
逻辑处理服务部分就是一个个的逻辑处理单元,他们按照逻辑功能来区分和聚合。同一个功能的服务器,注册为同一名字。前端服务就按名字来挑选不同的服务器。比如,有一个服务是用来获取用户基本信息的,我们就取名字叫:com.simplemain.user,然后有三台机器都部署了这个服务,分别是MA、MB和MC。当有一个逻辑要获取用户基本信息的时候,就会从命名/位置服务那里,通过"com.simplemain.user"这个名字,来找到对应的机器,并按照对应的负载均衡策略(比如:随机、一致hash、轮询等)来挑选一台机器返回给请求的服务(比如:MB)。因为web服务一般是无状态的,使得我们可以简化请求处理的复杂度,只需要每次请求的时候带上用户请求的参数,我们就能根据这些参数给出相应的返回。
命名/位置服务,也是同样的作用,就是提供机器、服务的注册和查找,以及健康检查等功能。
通过以上的手段,我们的逻辑层也可以通过增加机器的方式,来应对流量的压力。所以,压力又往后传递到了数据存储层(是不是一切都看起来很美好呢?)。
3、数据存储层:用来做数据的存储和访问。这一层是最为复杂,设计模式也最多的一层。因为数据的存储,根据业务的不同,很难有一个统一的模型去处理。不过,大体上有这样的一个设计模式:
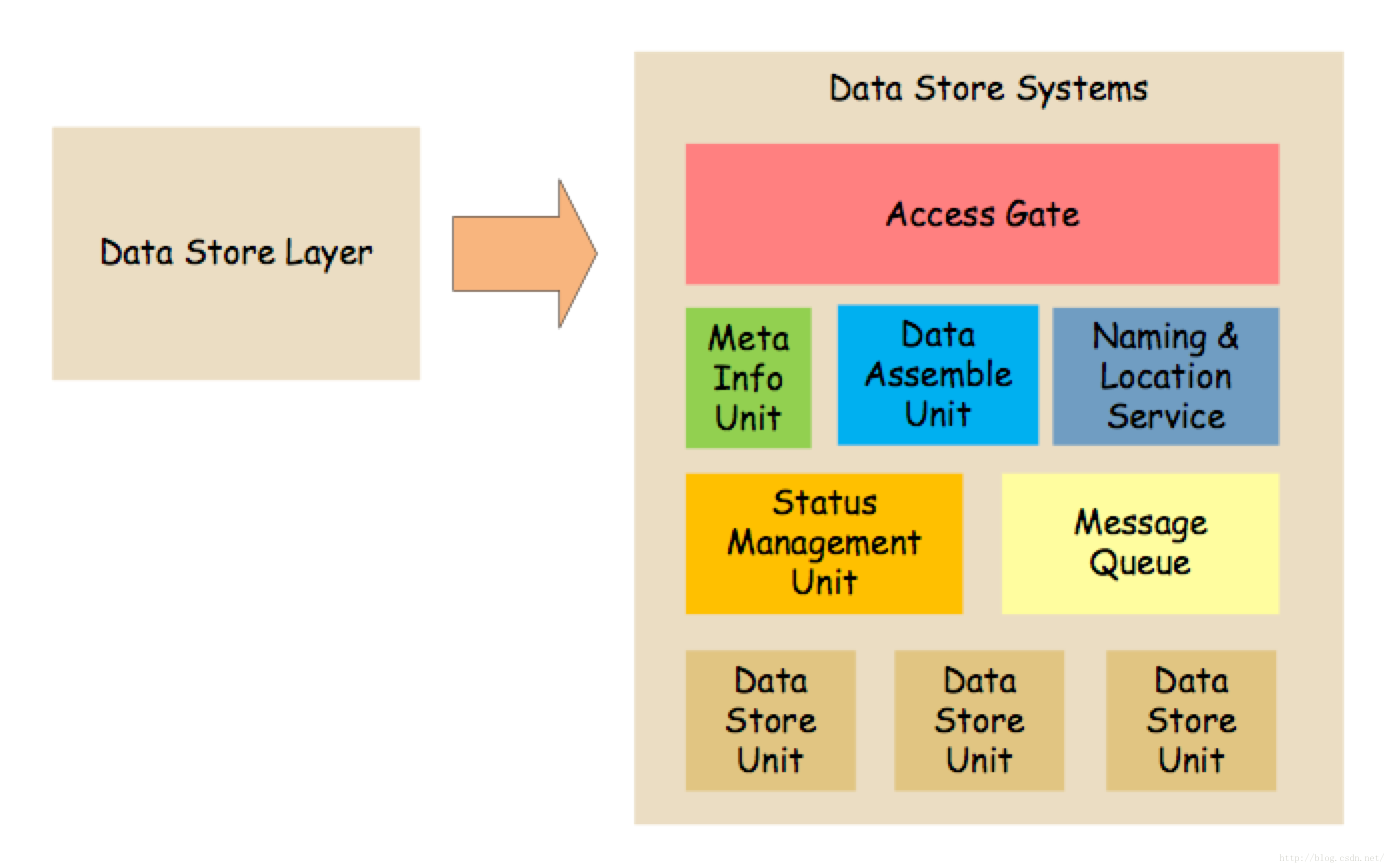
对外提供一个访问网关(Access Gate),用来屏蔽内部的细节(比如,我们常听说的mysql-proxy就是类似的作用)。内部系统就包含:
1、源信息单元(MetaInfo Unit),用来记录每个数据具体存储在哪里;
2、数据组装单元(DataAssemble Unit),用来将多个地方的数据组装返回;
3、命名/位置服务;
4、状态管理单元(StatusManagement Unit),用来管理数据单元的状态;
5、消息队列(MessageQueue),用来做数据转发,平滑大量数据提交带来的瞬时压力,以及修复数据等;
6、数据存储单元(DataStore Unit),就是存储具体数据的地方。
不是每个存储系统都需要这些东东,可以根据业务的需求选择性的使用。他们的作用,说白了,就是因为数据太多了,需要分散来存;因为存一份太不安全了,需要存储冗余的数据,来保证数据损坏以后可恢复。
打个比方,不知道大家是否用过mysql,这就是我们最常用的数据存储系统。当数据量和请求不大的时候,我们用一个mysql就可以存下所有的数据,应对所有的请求。但是,这里有三种情况可能发生:
1、请求量变大;
2、数据量超出磁盘大小;
3、数据需要做实时热备。
这三种情况发生了,怎么办?
1、请求量变大了。
我们最好的想法,就是能够有多个mysql,每个mysql有同样的数据用来应对请求,对不对?那mysql提供了主-从同步的模式,有一个主的mysql,所有的写入操作都走他过,而他将数据写入后,通过binlog的方式,同步到其他非主的mysql(俗称从库)。这里面这种数据同步的方式,原理上来讲,就用到了消息队列(Message Queue)的思想和设计。
另外,有可能某些机器运转着运转着就坏掉了,怎么办呢?就需要有健康检查的机制,把坏掉的机器从我们这一组机器中摘除,保证整体服务的可用,这就是我们介绍的状态管理单元的作用。
2、数据量超出磁盘大小。
不管是单机模式,还是主从模式,每个机器都是存储的全量数据,当数据量太大的时候,每个机器都没办法放了,怎么办?只能把数据拆分,放到不同的数据库。如果我们把之前讲的每一个主从mysql看做一套,那我们就可以把数据拆解成N份:mysql-group-1、mysql-group-2……mysql-group-N,这样,我们就可以不受单个磁盘大小的限制了,对不对?
但是这样拆分带来了其他的问题,当请求来了以后,我应该去找哪个mysql组拿数据呢?如果数据是放到多个组的,那数据怎么合并呢?这就需要我们的源信息单元来对信息管理,告诉我们哪些数据再哪个单元里面。数据取出来以后,再有数据组装单元将数据组装合并后,返回给请求者。
3、数据需要做实时热备。
为了保证数据不丢失,我们就需要对数据保存多份。其实通过主从的方式,我们已经可以做到热备了。那我们一般要备份多少份呢,大家猜猜?
一般最少是3份,为什么呢?
我们先假设有N份数据,当我们的主从数据库提供服务的时候,比方说一台机器坏掉了,这个时候,线上就只有N-1份数据了。那我们为了保证数据的可持续使用,需要用新的机器替换掉将刚刚坏掉的机器,这个时候,就需要将已有的数据拷贝到新的机器上。拷贝一般有热拷贝(实时在线拷贝)和冷拷贝(摘除服务后离线拷贝,拷贝完成后,由Message Queue分发最近的缺失的那一部分即可)。那不管哪种拷贝,都需要有另外一台机器来提供数据源,为了保证线上服务的稳定,这个源数据机器最好不提供线上服务,所有,能提供线上服务的机器就只有N-2个了。由于要保证线上服务,所以N-2 >=1,则N >= 3。
好了,数据存储层做分布式的东东,大面儿上就是这样的。当然细节很多,说起来容易,做起来却不易(我们之前做贴吧存储系统的时候,就花了大半年的时间调研和开发,里面的水很深)。不过,现在很多通用数据库已经提供了很多集成方案来帮大家解决问题,这使得我们已经能很快速和方便的应对存储带来的问题。但是,在解决问题的时候,有这样的思想却是非常重要的。
====扯淡休息的分割线 ====
怎么样,是不是感觉顿时压力倍增呢?一下看到这样的一个结构,确实有点恼火。不要紧,先初步感受一下,老王会在后面的文章中,一步步带大家了解为什么要这么做,以及怎么走到这一步的。其实有了这样一个框架,大部分的系统,就基本都在这个框架下做的衍生,无非就是套不同的逻辑和数据。
好吧,老王本来指望这用上中下三篇文章来把这个蓝图讲个大概,结果写到下篇,发现居然三篇写不完了,没办法,只有临时把这个下篇又拆分,大家理解理解哈~
接下来的一篇,老王就想讲讲那些通用的分布式组件,比如:消息队列(Message Queue)、命名/位置服务(Naming Service)、远程调用组件(Remote Procedure Call)等,希望能够在一篇之内讲完,嘿嘿~
那今天就写到这里咯,有兴趣的盆友请继续关注老王的微信:simplemain今天就暂时不贴美图了哈(因为老王发现每篇文章一张美图可能不够用,就准备留着后面用)~
