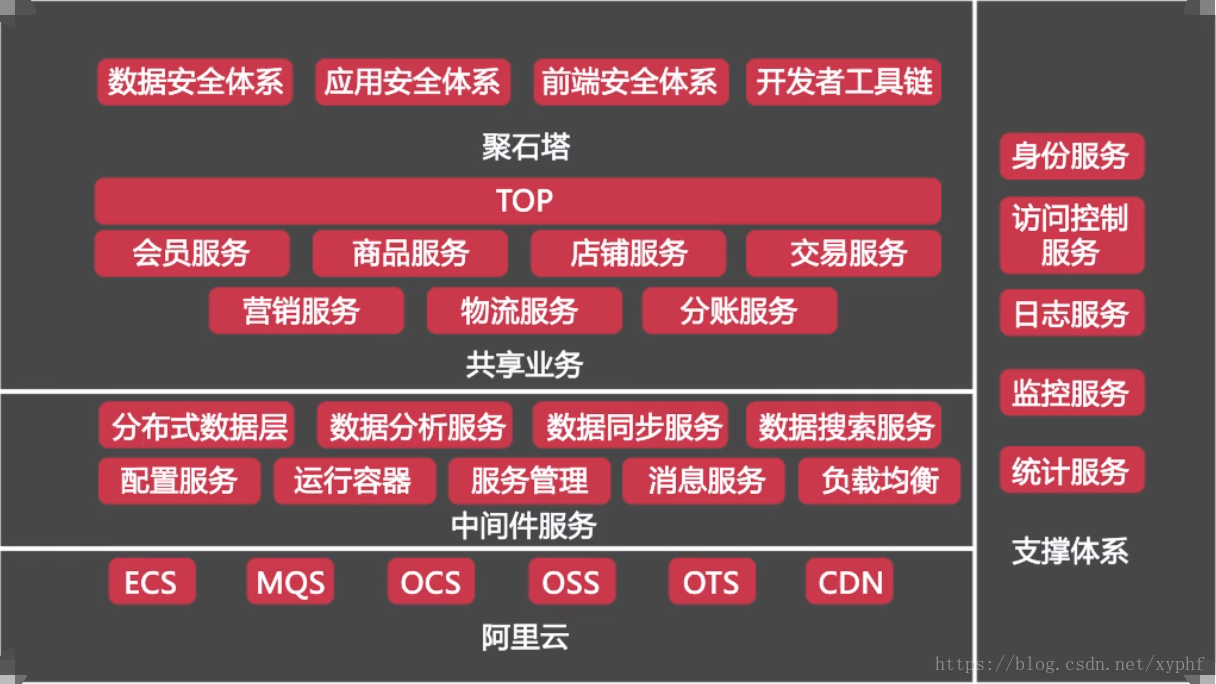
从一个小网站说起,一台服务器也就够了,
文件服务器和数据库都部署在一台机器上,所成All in one
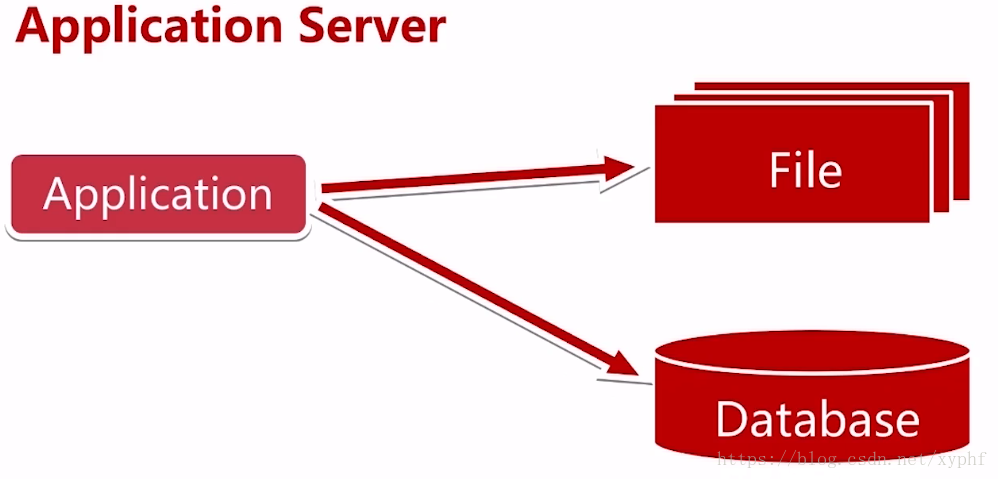
随着用户越来越多,访问量越来越大,硬盘、CPU、内存等开始吃紧,一台服务器已经满足不了了
这时我们讲数据服务和应用服务进行一个分离,给应用服务器配置更好的CPU,内存等等,而给数据服务器配置更好、更快、更大的硬盘。
利润我们这张图利用了三台服务器,分离之后可以提高一定的性能和可用性,假如文件服务器挂了,我们还是可以操作应用和数据库的。
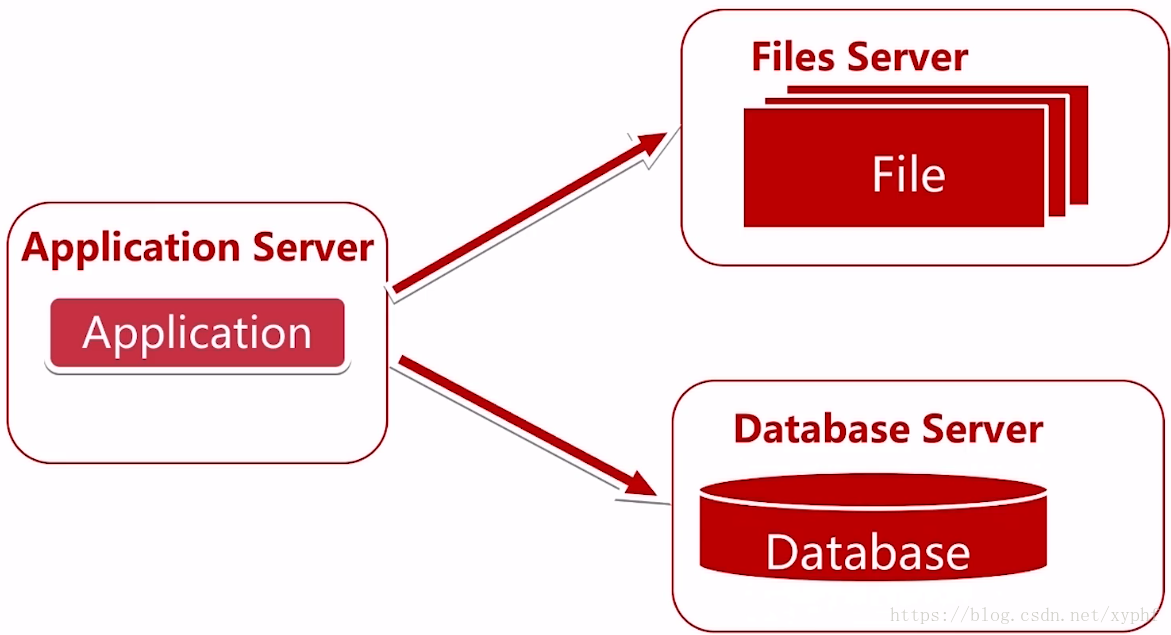
随着访问的并发越来越高,为了降低接口访问时间提高服务性能,
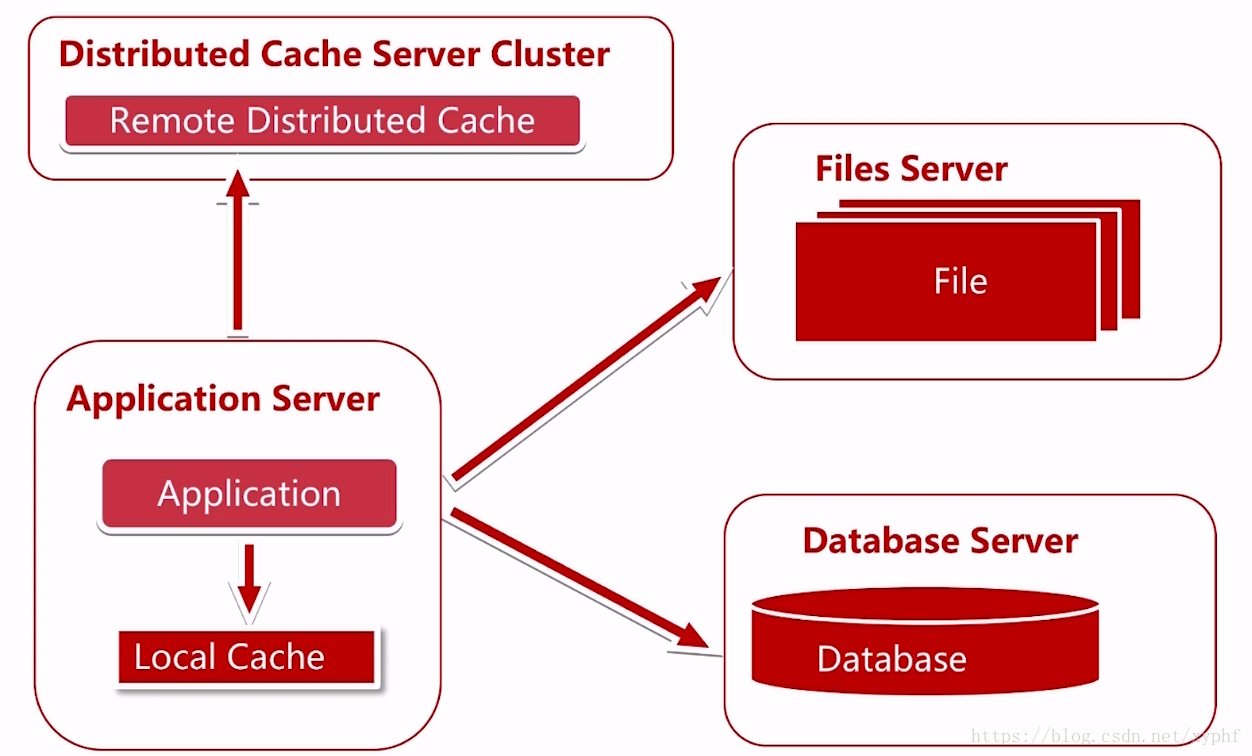
我们发现有些业务数据不需要每次都从数据库中获取,于是我们使用了缓存,因为80%的业务访问都集中在20%的业务数据上,也就是俗称的二八原则。如果我们能将这部分数据缓存起来,性能一下子就上来了。
而缓存又分为本地缓存和远程缓存两种,远程缓存又分为远程的单机缓存和远程的分布式缓存;
例如我们途中画的就是一个分布式缓存的集群;
这时我们要思考一下,具有哪种业务特点的数据要用缓存?
具有哪种业务特点的数据使用本地缓存?
具有哪种业务特点的数据使用远程缓存?
分布式缓存在扩容时会碰到什么问题?如何解决?
分布式缓存的算法都有哪几种?各有什么优缺点?
这些问题都是我们在利用这个架构时需要思考和解决的问题。
这个时候随着访问的QPS不断提高,服务器的处理能力,
假设我们使用的Application Server是tomcat,那么tomcat就会成为一个瓶颈,虽然我们可以通过购买更强大的硬件,但是总会有上线,并且这个成本到后期是一个指数级的增长。
这个时候我们就需要做一个服务器的集群,我们要加一个新东西,【负载均衡调度服务器】
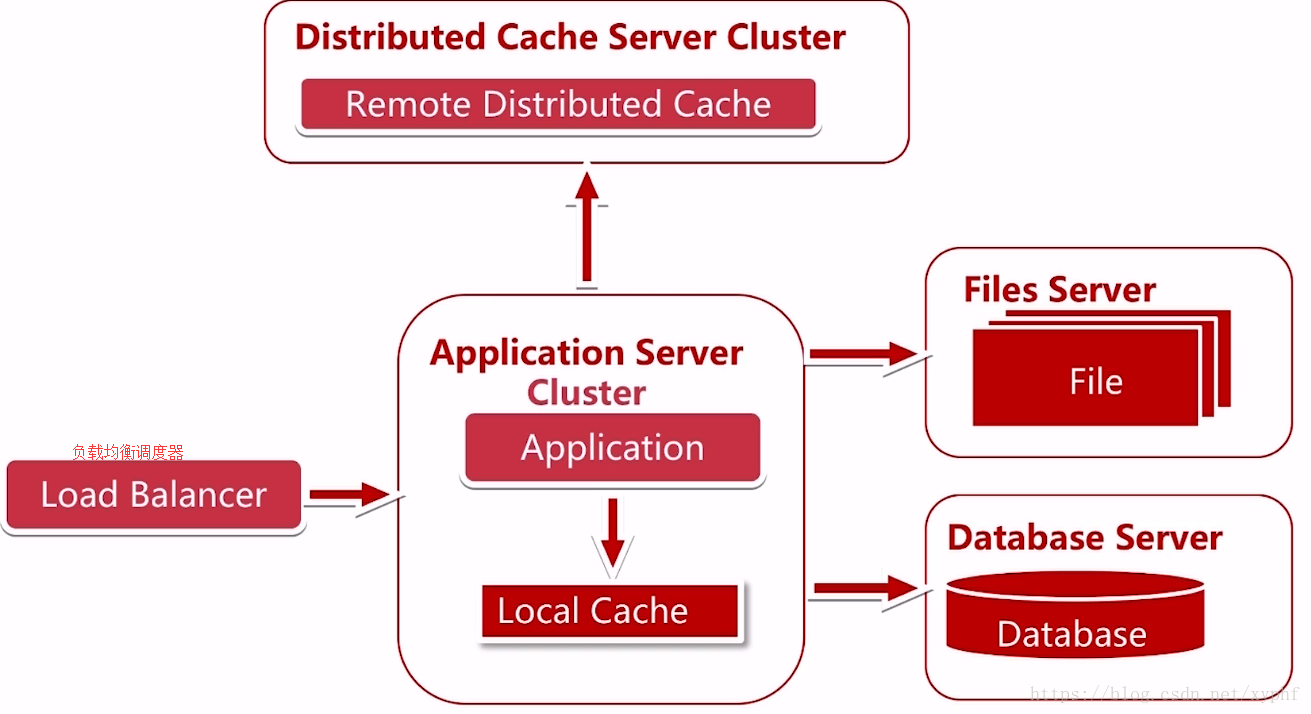
服务器集群之后,我们可以横向扩展我们的服务器了;
解决了服务器处理能力的一个瓶颈;
这个时候我们要要思考几个问题
负载均衡的调度策略都有哪些?各有什么优缺点?各适合什么场景?
打个比方,我们有轮询、权重、地址散列
地址散列又分为源ip地址散列和目标ip地址散列,最少连接和加权最少连接,还有根据这些策略升级而来的很多策略。
例如轮询优点就是实现简单,缺点就是不考虑每台服务器处理能力;
权重我们考虑了服务器处理能力的问题;
地址散列可以使用同一个用户访问同一个服务器;
最少连接可以使集群中各个服务器负载更加均匀;
加权最少连接就是指在最少连接的基础上,为每台服务器加上权值;算法就是(活动连接数*256+非活动连接数)/权重;计算出来的值小的服务器优先被选择;
这里我们如图所示增加了一个负载均衡调度器,应用呢增加了一个Cluster;也就是说一个集群;
在使用了这种架构之后呢,我们有这么一个场景,我们登录的时候,登录了A服务器;Session信息存储到A服务器上;假设我们使用的负载均衡策略是根据ip进行一个哈希散列,那么登录信息还可以从A服务器上访问到;但是IP哈希不够分散也不够均匀;
这就有可能造成某些服务器压力过大,某些服务器又没有什么压力;
这个时候我们机器网卡的带宽就有肯能成为一个瓶颈;
这个时候我们使用轮询或者最少连接的负载均衡则略,
这就导致了我们地址访问A服务器,把Session信息存储到A服务器上,第二次是有可能访问到B服务器,这个时候存储在A服务器上的Session信息在B服务器上是读取不到的。那么我们就要解决session管理的问题?
我们使用session sticky粘滞会话这种方式来解决这个问题;
打个比方如果我们每次吃饭都有使用自己的碗筷,而只要在一家饭店里存着我们的碗筷,我们每次去这家饭店吃饭就好了,因为那里存着我们的碗筷;
它的处理规则是对于同一连接中的数据包负载均衡会将其进行一个NAT转化后转发至后端固定的服务器进行处理,也就是如图所示

例如我们图中所示的Browser1走到负载均衡服务器然后走1的路径到底Application当中;也就是说我们的Browser1每次都会访问到1的Application。这种方案解决了Session共享的问题。但是它也有一些缺点,第一个缺点,1这个服务器重启了上面的Session将全部消失,第二个缺点就是我们的负载均衡服务器成了一个有状态的机器,要实现容灾会有麻烦。
我们接着看第二个解决方案,Session复制

也就是说Browser1通过负载均衡服务器访问到1这个Application当中的时候,会把这个用户的Session复制到第二个用户的服务器上;也就是说这两个服务器都保留着Browser1的Session信息;
打个比方就好比所在的饭店里都存着自己的碗筷,我们去哪个饭店都OK,都有自己的碗筷;
我们又解决了Session共享的问题;但是它也有缺点,应用服务器带宽之间的问题;Application1和Aplication2之间要不断的同步Session信息;另外一个就是当我们大量用户在线的时候,我们这个服务器占用的内存会过多,不适合做大规模集群,适合做机器不多的情况;
我们在看第三种解决方案

这种就是基于Cookie,打个比方类似我们去吃饭,每次都把自己的碗筷带上,这样去哪家饭店都OK,都可以吃饭;
我们带着Session信息的Cookie去访问我们的应用服务器;这种方式也解决了我们Session共享的问题;
但是它也是有缺点的,首先我们Cookie的长度是有限制的;其次Cookie保存在浏览器上安全性也是一个问题;
那么我们再看第四种解决方案,我们把Session做成一个Session服务器
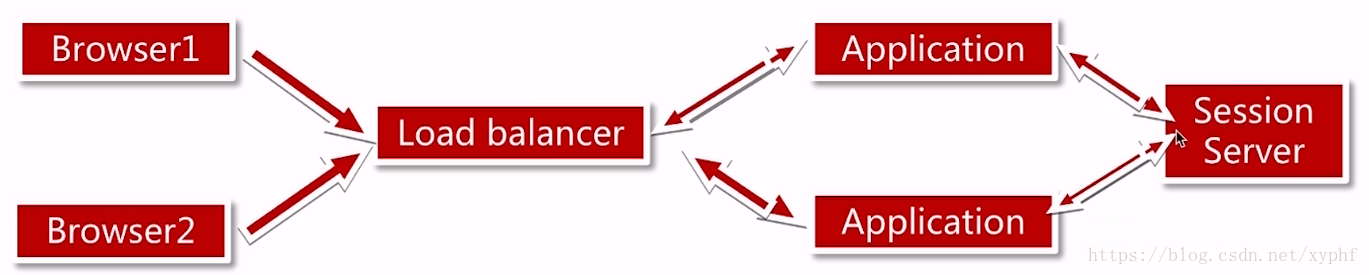
这样的请求路径就是Browser1通过负载均衡服务器请求到Application1当中,然后它把Browser1的Session信息存到Session Server当中;当想获取Session的时候,应用就从Session服务器当中获取Session;我们所以用户的Session信息都统一保存到Session Server当中;
这个就好比我们去饭店,我们也不自己带着碗筷,饭店共有一个很大的橱柜,我们的碗筷都存在那里;我们去A饭店,A饭店就去橱柜里面去找你的碗筷,如果我们去B饭店,B饭店也会从橱柜中拿好你的碗筷;
这里我们要考虑以下几个缺点;
在目前这个架构中Session Server是一个单点的,我们要如何解决这个单点,保证它的可用性,我们可以把Session Server也做成一个集群;这种方式适用于Session数量及Web服务器数量大的情况;
同时我们改成这种架构之后,我们在写应用的时候也要调整Session存储的业务逻辑;
在招聘面试时经常会遇到类似的问题;
在解决了横向扩展应用服务器之后,
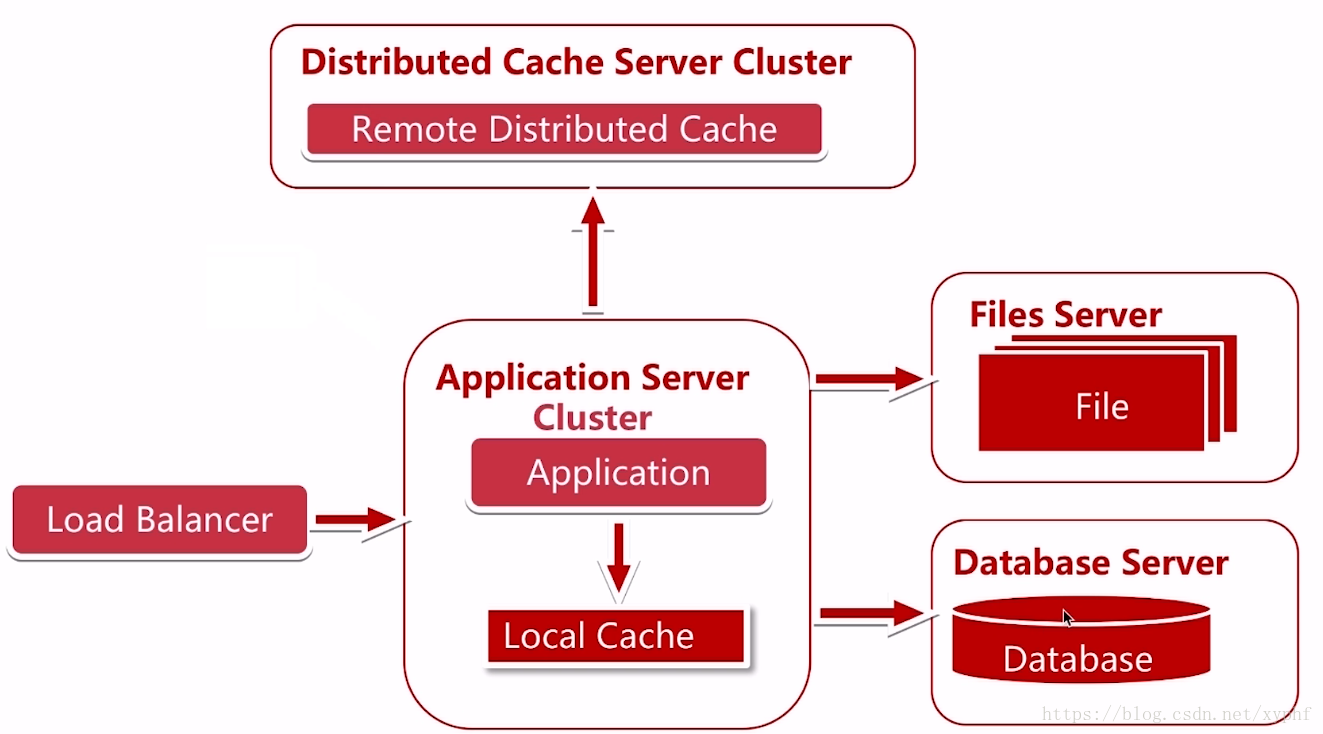
我们数据库的读与写操作都需要经过数据库,当用户量达到一定量时,数据库又成为了一个瓶颈;
那么如何解决呢?我们使用了数据库的读写分离;
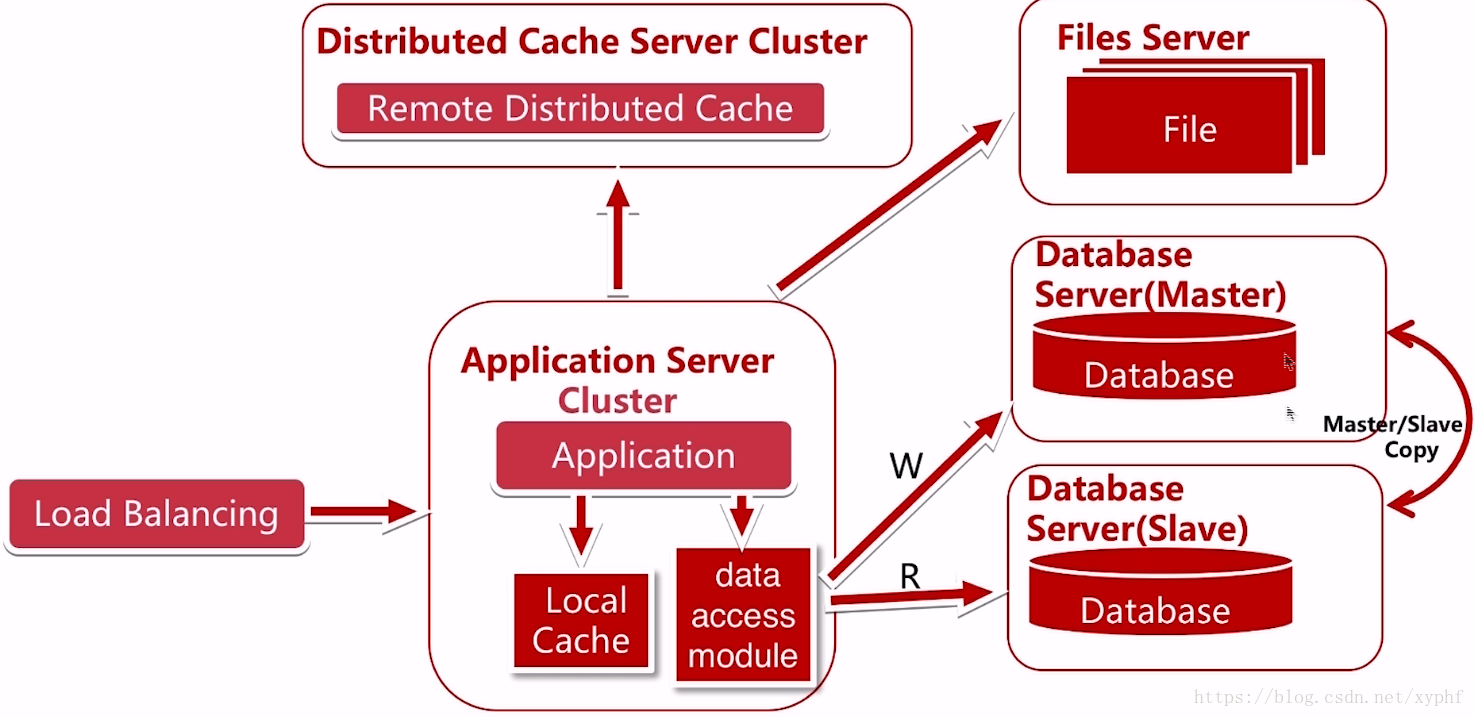
Msster是主库,Slave是从库;同时我们应用要接入多数据源,并且经过统一的数据访问模型data access module进行访问;
数据库读写分离将所有的读操作引入到Slave这个服务器,将所有的写操作全部引入Master服务器,引入到我们的主库当中;
因为我们数据库读写分离了,所以我们应用程序也要做出相应的变化;我们在Local Cache实现了一个数据访问模块,使上层写代码的人不知道读写分离的存在;这样我们读数据源的读写对业务代码就没有了侵入,这里就引入了代码层次的一个演变;
如何支持多数据源?
如何封装对业务没有侵入?
如何使用目前业务使用的ORM框架完成主从的读写分离?
是否需要更换ORM?又各有什么优缺点?如何取舍?
当我们的访问量过大的时候,也就是说数据库的IO非常大,我们数据库的读写分离又会遇到以下问题。
例如我们的主库和从库在复制的时候有没有延时?
如果我们将主库和从库在分机房部署的话,跨机房传输同步数据 ,这个更是一个问题;
另外一个问题是应用对应数据源的路由问题?
这些都是我们要思考和解决的点?
我们接着演进,我为服务器添加CDN和反向代理服务器;
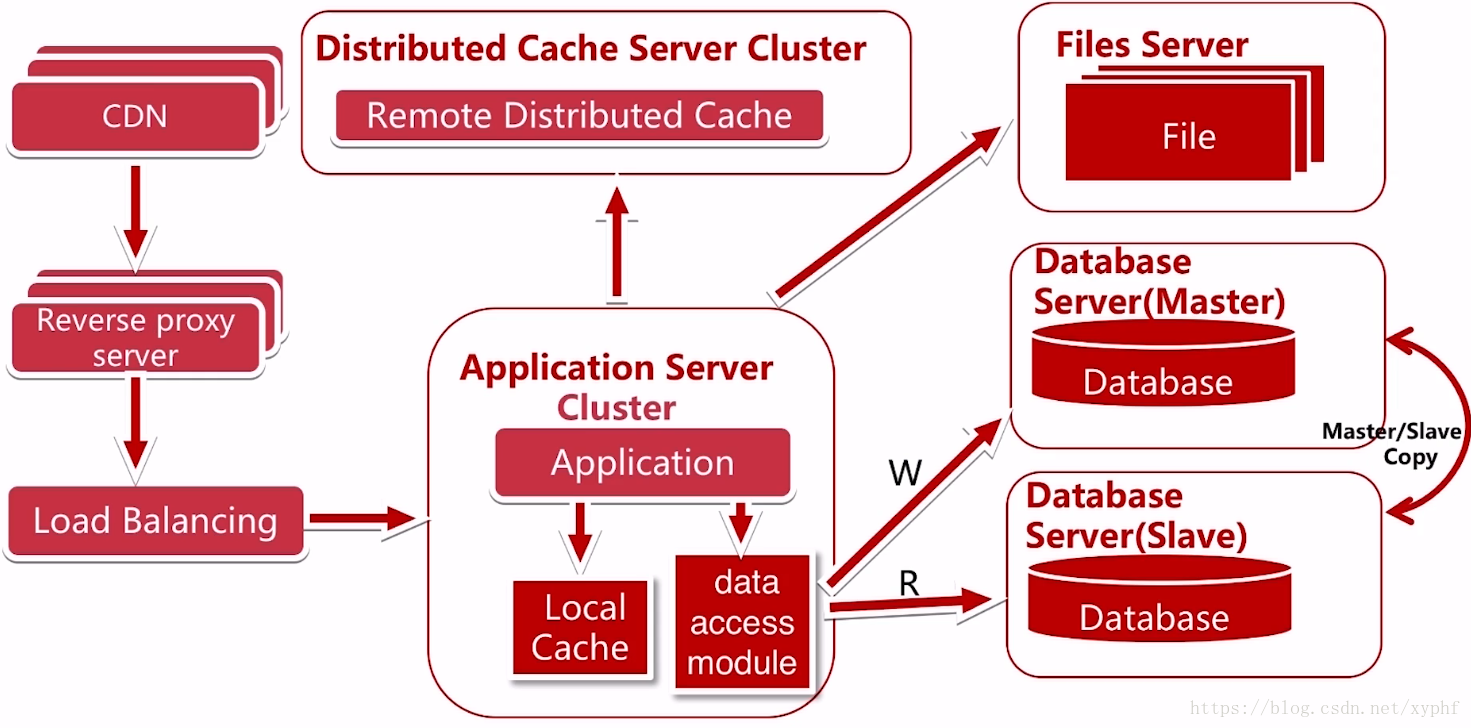
使用CDN可以很好的解决不同的地区访问速度问题;反向代理则可以在服务器机房当中缓存用户的资源;
这个时候我们的文件服务器又出现了一个瓶颈;这时我们把文件服务器改成了分布式文件服务器集群;
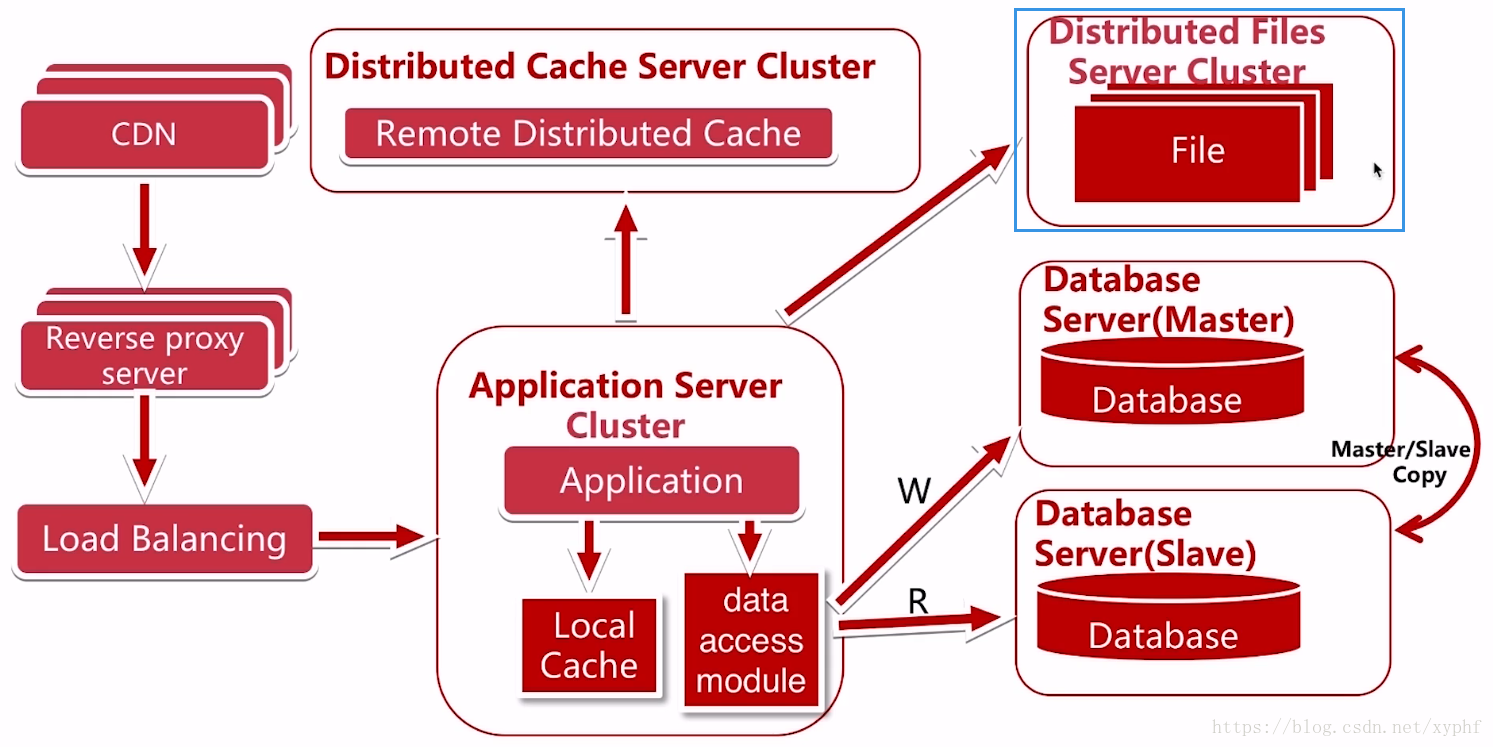
我们在使用分布式文件系统的时候,我们要考虑以下几个问题.
如何不影响已在线上的业务访问?
是否需要业务部门帮忙清洗数据?
是否需要备份服务器?
是否需要重新做域名解决等?
我们继续演进……
这个时候我们数据库又出现了一个瓶颈,我们选择专库专用的方式进行数据的一个垂直拆分,相关的业务都使用自己的库,我们解决了写数据并发量大的问题;
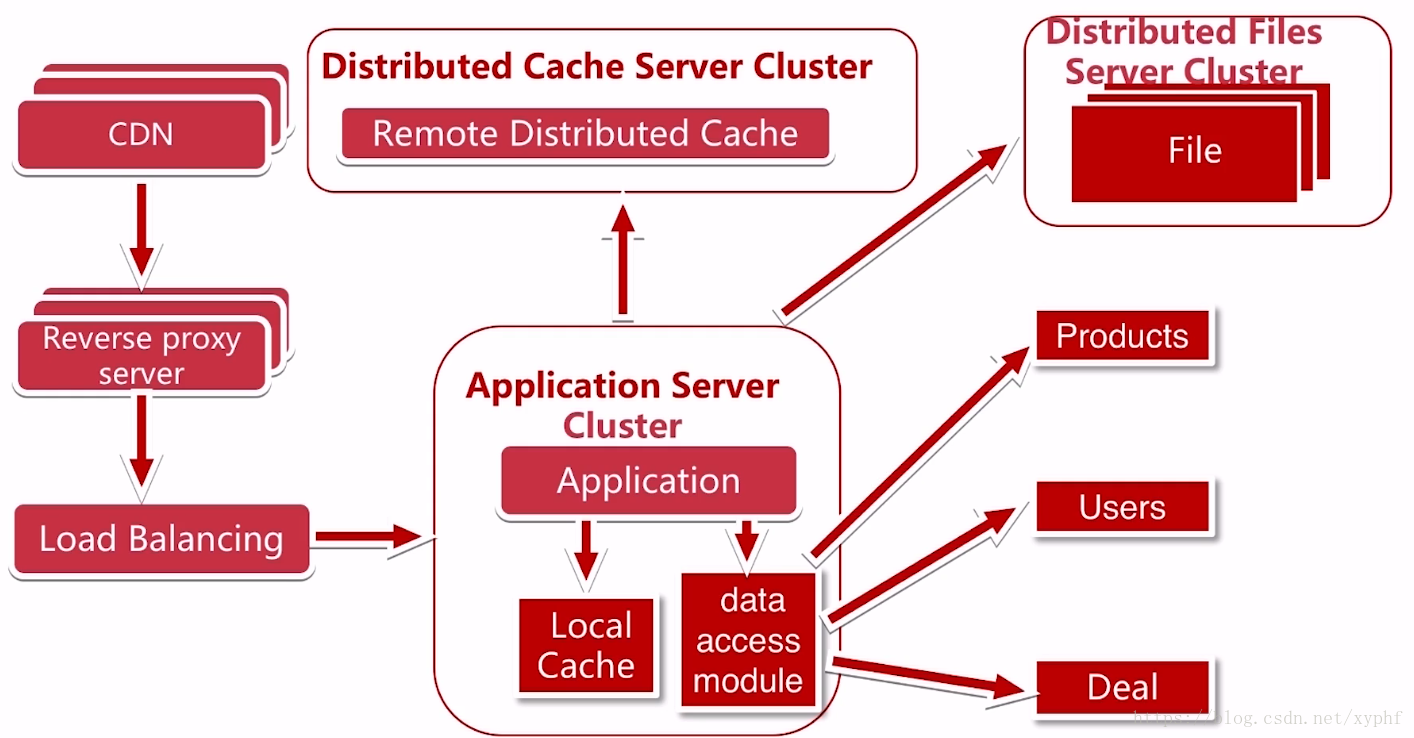
当我们把这些数据表分成不同的库,又会遇到哪些新问题呢?
例如我们跨业务的事务跨库的事务;我们可以解决分布式事务或者去掉事务或者不追求强事务;
随着我们的访问量过大、业务量过大、数据量过大,我们某个业务的数据库,它里面的数据量和更新量已经达到了单个数据库的一个瓶颈的了。
这个时候就需要数据库的水平拆分了
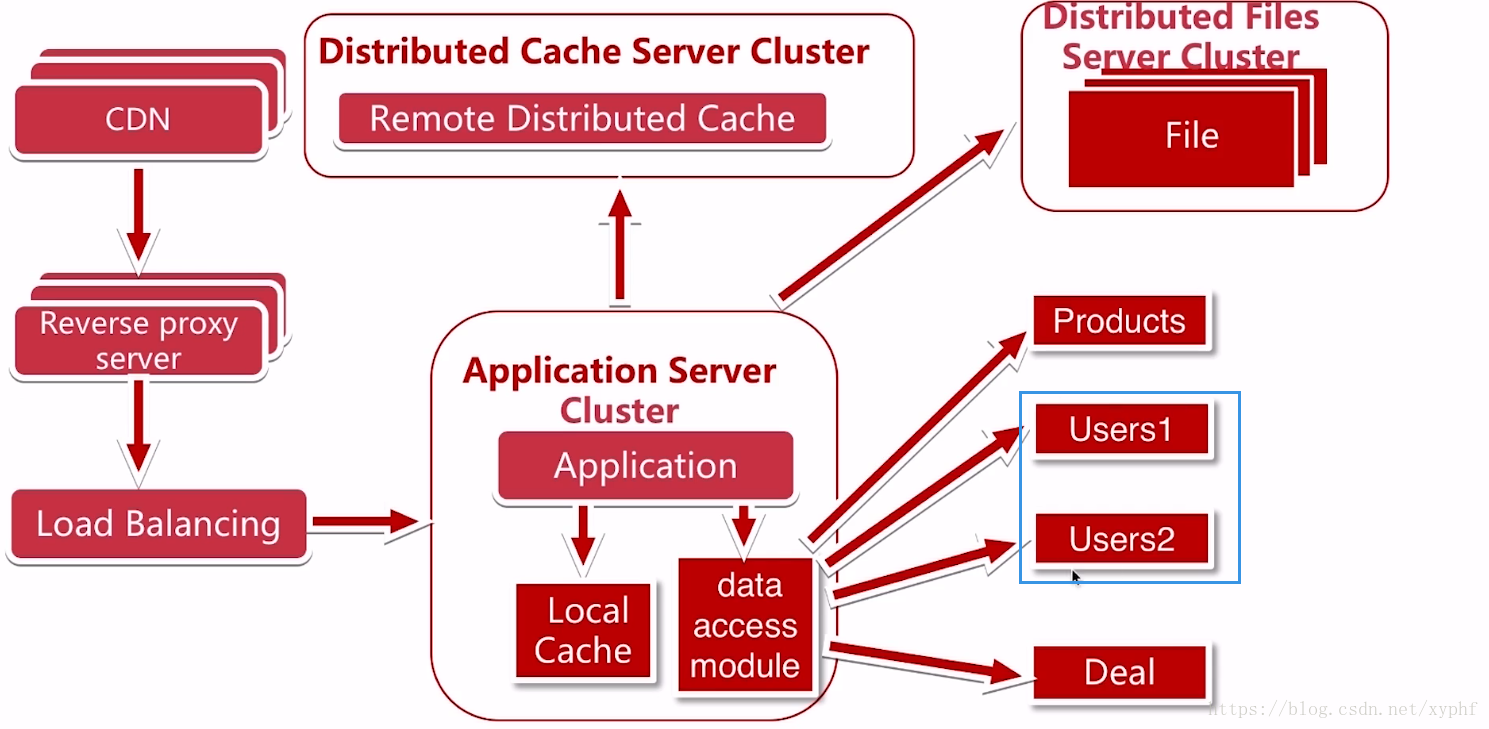
例如我们的User拆成Users1和Users2;所谓水平拆分就是将同一个表的数据水平拆分到两个表的数据库当中;这个时候我们解决了单数据库的瓶颈;
那么我们在水平拆分的时候要注意哪些点呢?
都有哪几种水平拆分的方式?
进行了水平拆分之后,我们又会遇到几个问题?
第一个就是SQL路由的问题?假如我们有一个用户,我们要知道他是在Users1这个库中还是Users2这个库中;
第二呢,因为已经分库了,我们主键的策略也会有所不同;同时也会面临一个分页的问题;
假设我们要查询2017年4月份已经下单过的用户的明细;而这些用户又分布在Users1和Users2当中;我们后台管理系统在对他进行展示的时候还要进行一个分页;这个都是我们在使用这个架构的时候需要解决的问题;
当我们完成这个架构之后,我们发现应用服务器的搜索量又在飙升?因为我们对外做了一些推广
这时候我们把应用服务器的搜索功能,单独抽取出来做了一个搜索引擎;同时我们部分场景可以利用NoSQL提搞性能;同时我们开发一个数据统一的访问模块。这个模块下面连着数据库、搜索引擎集群、NoSQL;解决上层应用开发的数据源问题;
当然了,这只是一个举例子,各个服务的技术架构是需要根据自己的业务特点进行优化和演进的,所以这个过程也不是完全相同的;
当然了这个架构也不是最终的形态,这个架构还是存着很多要提升的地方
例如我们的Load Balancing负载均衡服务器,这个负载均衡服务器目前是一个单点,如果这个负载均衡服务器访问不了,那么解决下来的包括服务器集群等也将都访问不了;所以我们的负载均衡服务器也可以把它提升成一个集群,然后做一些主从的双机热备自动切换的解决方案;
