今天想跟大伙儿聊聊分布式组件。说到组件,老王当年就觉得是高大上的玩意儿。一听说谁谁谁在哪个公司,写某某组件,仰慕之情犹如滔滔江水延绵不绝~后来自己也写了一些所谓的组件以后,觉得这个并没有什么神秘的。所谓组件,老王是这么理解的:为了一个整体的环境能够完整的工作,而提供的一些功能相对独立、目标明确、有可能通用性强一些的函数、类、库、模块、系统或者服务等等。比如,你写一个打印的函数,提供给文字编辑的软件使用,你的函数就可以叫做打印组件;也可以提供一个打印服务给文字处理系统,你的服务也可以叫做打印组件。这是老王的一个理解,不一定全面。
那具体到互联网分布式体系中,有一些组件是比较通用的,可能会对我们的架构设计起到关键作用的。老王今天把他们提出来,专门聊聊。好吧,开始正题~
命名服务(Naming Service):
在上一篇,我们讲分布式架构的时候(如果没看过上一篇的盆友,请关注老王的微信:simplemain进行查阅),多次提到他。那他到底是什么玩意儿呢?大家都知道DNS吧(就是你ping www.baidu.com的时候,把域名变成ip的那玩意儿),命名服务的作用类似,就是把我们内部系统的名字变成ip的服务。那为什么要有他呢?并且他的作用还那么重要?嫑急,慢慢往下看~
第一个阶段:
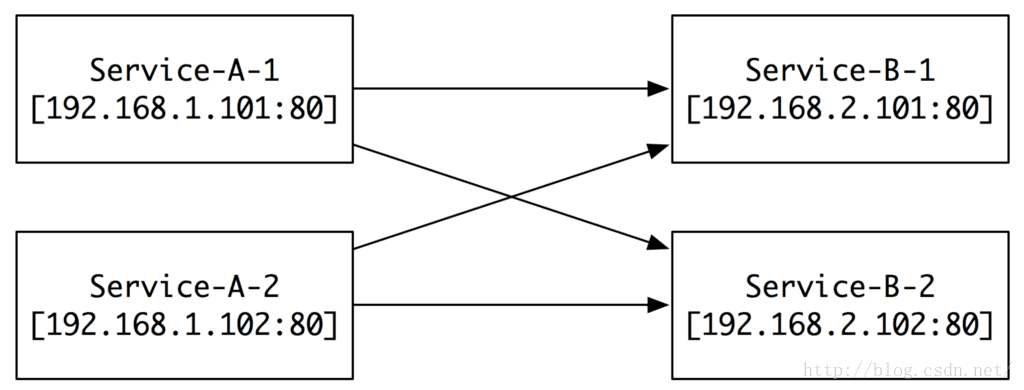
当我们服务还不多,机器也不多的时候,我们有两个服务,分别叫Service-A(以下简称A)和Service-B(以下简称B),他们各自有两台服务器,对应不同的ip和端口。当A要调用B的时候,最简单的方法就是在A的每一个机器上,填写好B的所有机器的IP和Port,对吧。这看起来多么的完美。
可是,当我们规模扩大的时候,问题就来了。
第二个阶段:
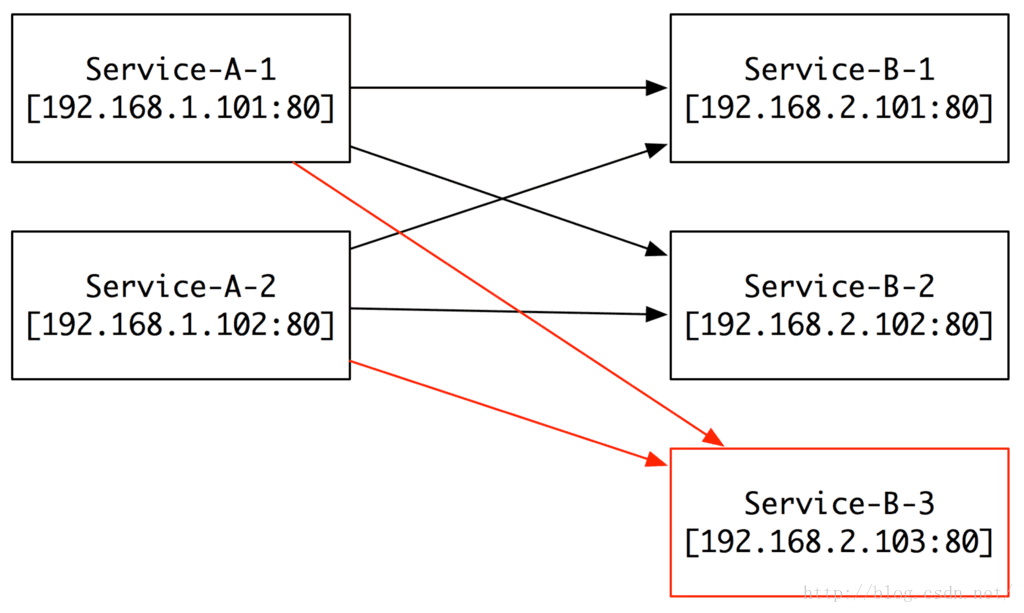
当我规模扩大或者服务压力增大的时候,我们就需要加机器,比如现在我们加了一台B的3号服务器,那我们需要怎么做呢?先搭建B的3号服务器,然后把A的所有机器配置B的部分增加一台3号服务器的IP和Port。看起来似乎也不是什么问题,对吧?
如果,我们要增加10台、100台B呢?
另外,如果我们新增加了服务C、D、E……,然后每个平均有10台、100台服务器,那我们是不是就要疯了!
同理,如果我们的服务器出现问题,要替换、要下线,是不是又要全部去配置一遍?
当年我在百度的时候,公司模块之间的关系图就是这样的。要增加或者修改一个模块,与之相关联的模块全部都需要修改。有时候为了上一个小小的功能,需要惊动N个系统。着实让人崩溃~后来,回百词斩以后,算是做的第一件系统性的工作,就是开发上线Naming Service。现在回头来看,这个决策真是太正确不过了。
那他是怎么工作的呢?
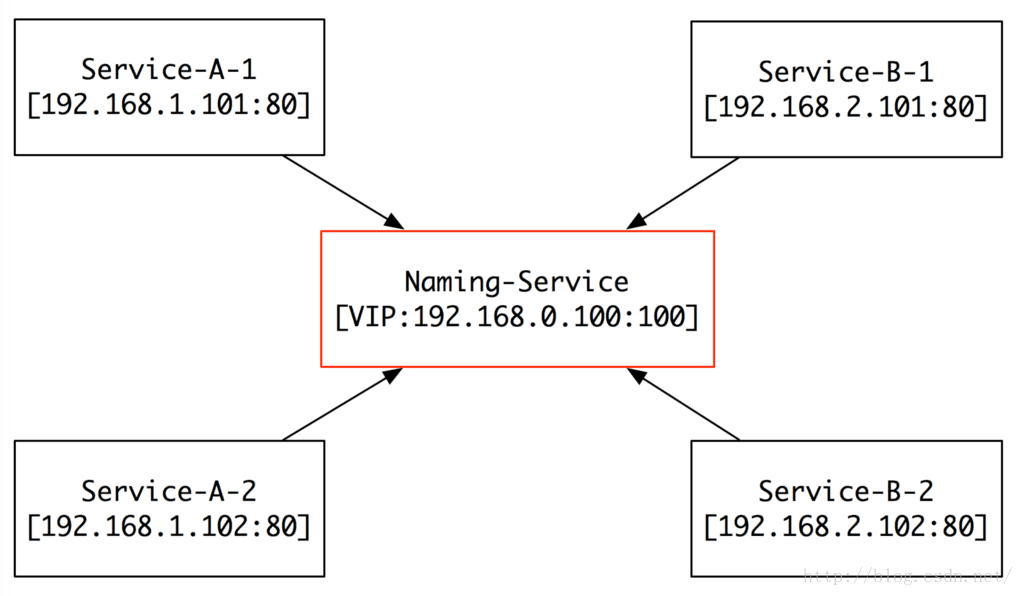
注册(Register):
所有的服务,都将自己的名字、IP、Port注册到Naming-Service(以下简称NS),然后NS就维护N个队列:
队列1:Queue A:
(192.168.1.101:80) -> (192.168.1.102:80)
队列2:Queue B:
(192.168.2.101:80) -> (192.168.2.102:80)
当有新的机器加入的时候,他们自己将自己注册到NS,完全不用别人去关心。
查询(Query):
当A需要请求B的时候,就去问NS:“哥们儿,我想请求B的服务,给我一个他的IP和Port吧”。然后NS就根据负载均衡策略(比如:随机、一致哈希等),返回一个可用的IP和Port给A。即使B有新机器加入,A也不用关心,因为有NS这个保姆在。
健康检查(Healthy Check):
如果有机器坏掉,或者服务crash了,NS会在很短的时间内通过心跳包检测到服务出现问题了。这时,NS就会把出问题的IP和Port从可用队列中把他们摘除,以保证队列中给出去的都是可靠稳定的服务。
好了,有了上面三个功能,命名服务就基本能提供服务了。但是有一个问题,我们的其他服务怎么找到命名服务呢?我们一般将命名服务放在一个虚拟服务器(比如LVS)后面,对外提供一个虚拟IP。这样,各个服务器只需要配置一个固定IP就可以知道了。如果想稳妥一些,可以配置这样的一组(比如3个)IP,这样就可以做到IP的热备。
NS在我们分布式架构中占据中心位置,提供的是中心化服务。在一般的体系架构中工作的非常完美。不过对于有些非中心化要求的系统来说(比如:NS内部),这个就是不能接受的,那其实也是有方案的,比如我们会用到Gossip协议,帮我们去掉中心化的设计。在这里就暂时不详细讲解了,后面找时间专门来讲述~
消息队列(Message Queue):
当老王第一次接触消息队列的时候,第一反应是,这个是不是给手机推消息的一个系统?现在回想起来觉得好好笑。这个系统确实可以用来给手机推送消息,不过他有着更广泛的应用和意义。
当年在百度的时候,内部有一个系统叫CM-Transfer,就是用来给各个系统发送信息的,其实也就是一个消息队列。后来老王回了百词斩,做了另外一个正确的决定,就是写了一个消息队列(以下简称MQ),解决了很多大流量或者集中提交的问题,一直享他的福至今。那MQ究竟是一个什么玩意儿呢?解决什么样的问题呢?
第一阶段:
当我们服务还不大的时候,用户的提交可能很小,比如一分钟就发几个贴子,那我们直接就可以把数据insert into xxx,毫无压力。这时候,架构也很简单,就是逻辑层直接连接数据库。
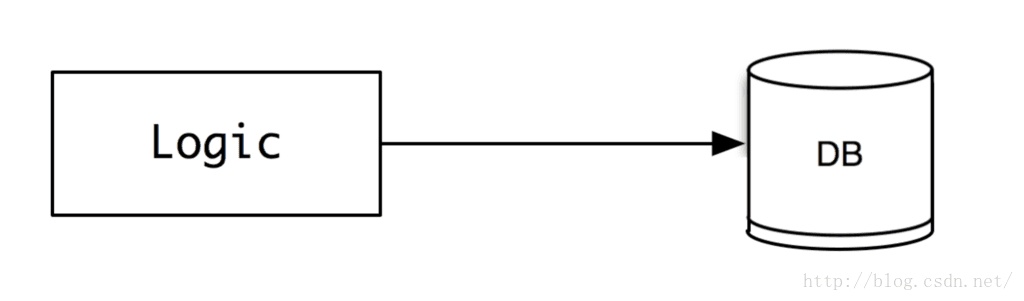
如果,这个时候流量突然增加(比如:我们用户暴增或者有一个秒杀的业务),怎么办?那方法有很多,大致如下:
1、做业务和数据切分:把业务切成正交的多个,或者是DB按垂直或者水平做切分;
2、逻辑层做数据缓存,定时合并和写回到数据库;
3、写自己专有的存储系统,替代数据库;
4、如果不是有强一致性要求,可以引入MQ,将同步提交变成异步提交。
前三种方式就暂时不在这里讨论了,我们重点看看第四种方式是如何来工作的。
第二阶段:
如果写过c语言的同学都知道,fwrite函数是一个带缓冲的写函数,你调用他把数据写进磁盘文件,这个函数并没有真正将数据写入磁盘,他建立了一个buffer,先把数据写在内存,到一定的时候,再写进磁盘。
(话外音:你以为他给你写了磁盘,其实没有,他 -- 欺!骗!了!你!)
他这样做有他的道理,就是如果你有频繁大量的写入操作,他会降低你写磁盘的频率,从而提升写操作的效率。但是也带来了问题,就是你的数据有可能会丢掉。
那在实际的互联网server开发工作中,我们其实可以借鉴这样的思想,当有大量写入操作的时候,我们就将数据写入到一个缓冲空间中,然后再由这个缓冲空间,将数据慢慢转发给真正的writer,让他来将数据写入到文件或者数据库中。这个缓冲空间就是我们的消息队列(MessageQueue)。要写的数据,可以看出一个个的消息,放入到这个队列中。
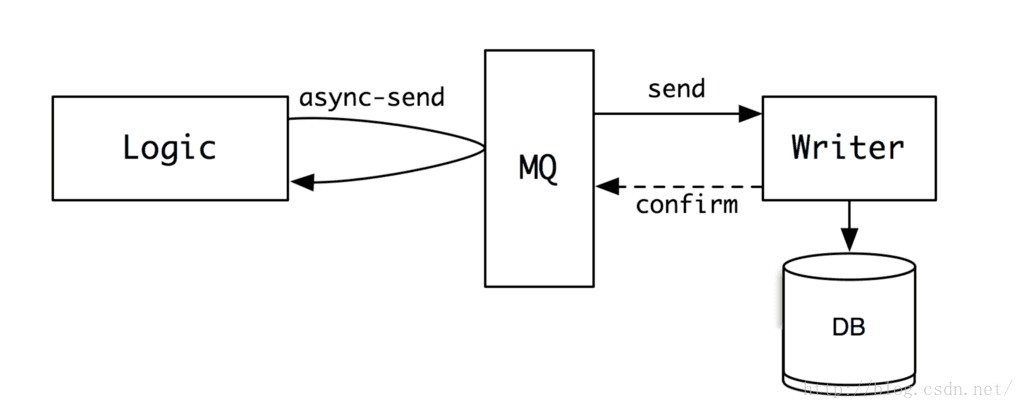
那刚刚说fwrite有一个问题,就是如果程序挂掉了,内存中的数据就丢失了。为了避免在MQ中出现类似的问题,MQ一般会做内容的序列化,将收到的消息,一条条连续的写入到磁盘,以保证数据的完整性。
那有同学就会问了,既然MQ也是要写磁盘,原来的存储也是写磁盘,那为什么MQ就能提升效率,解决高并发写的问题呢?这里原因大体有两点:
1、MQ是将消息顺序写入磁盘,而逻辑写入操作大部分是随机写入磁盘。而对于传统机械硬盘来讲,顺序写的效率远远高于随机写;即使是现在的ssd,随机写的性能也不如传统机械硬盘的顺序写性能;
2、MQ写入是完全无逻辑的,基本不消耗cpu和内存;而逻辑写入一般会含有逻辑,要做运算,所以不管是cpu、内存还是磁盘读写的消耗都是远大于MQ的顺序写入的。
MQ除了能用来平滑写高峰,还能做数据转发,同一份数据可以发送给多个接收者。
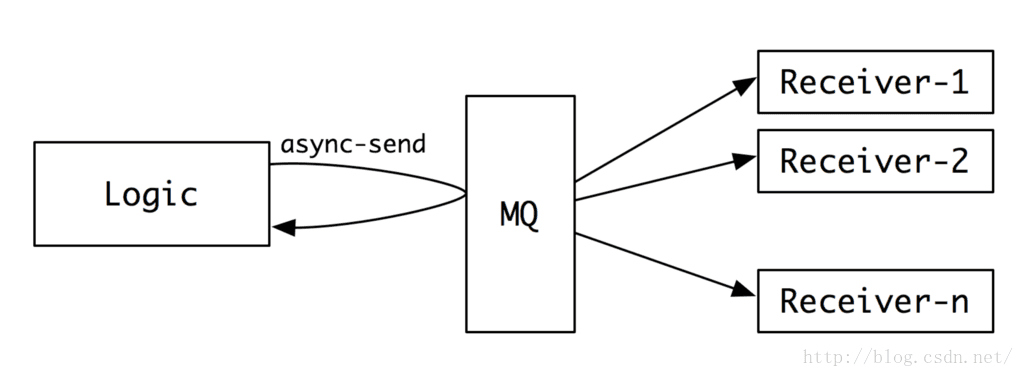
这个功能也可以被用作数据的备份、数据的回放等等。
现在比较流行的开源MQ有RabbitMQ、ActiveMQ、kafka等。这几个MQ老王当年大致调研过,后来出于多种原因(比如:需要集成thrift、naming service改动较多;需要支持多种模式的分发、回放等不太满足需求),最后老王花了两周写了一个Java版的MQ(以后有可能,准备拿出来开源),现在已经在线上稳定运行了快两年了,接收发送数据应该有数百亿了(用百词斩的盆友,你们背的单词数据就在里面哦~)。大体设计思想如下:

这里就不详细讲解了,如果大家有兴趣,以后有机会老王专门做一期MQ的分享。
刚刚老王在讲MQ的时候,不小心说到了一个东东:thrift。他就是Facebook做的一个RPC框架,用来解决分布式系统之间逻辑调用和数据交换的。那RPC具体是什么呢?
远程调用(RPC - RemoteProcedure Call):
刚刚老王在讲MQ的时候,不小心说到了一个东东:thrift。他就是Facebook做的一个RPC框架,用来解决分布式系统之间逻辑调用和数据交换的。那RPC具体是什么呢?

当两个系统(或者两个模块)要交换数据的时候,他们怎么弄呢?最简单的,System-1建立一个socket连接到System-2,然后通过send和recv函数,进行数据交换。
不过这样会有很多的问题:
1、代码写起来是不是很烦呢?
2、每一个send和recv是不是要讨论和规定数据格式呢?
3、如果socket建立失败了,怎么办呢?要不要重试呢?
4、连接和读取超时怎么样管理呢?
5、……
为了解决上述的问题,在做分布式系统时候,一般会做一套远程数据通讯协议,让数据交换就跟调用本地函数一样,而这个通讯协议底层帮你将网络连接、协议格式、读写管理等等都帮你做好了,你只要关心你的逻辑。这是不是极大的降低了开发的成本,并且提升了系统的稳定性呢?
现在常见的RPC工具有google的protobuf,facebook的thrift等。据了解现在鹅厂内部就是用的protobuf。
protobuf和thrift相比,两个都实现了跨平台数据协议转换,即将数据转换成二进制,再将二进制转换成不同语言的数据。不同的是,thrift自己带了client-server,可以直接基于这一套cs框架开发服务。而protobuf需要自己写cs框架(或者用第三方的框架)。另外,thrift支持的语言要比protobuf多。
经过长期慎重的比较,老王最后将thrift引入到我们的系统中。这么长时间已经运行的比较稳定。老王大概读了thrift的代码3遍,也改了其中一些东东以适应项目需要,以下是老王画的thrift的一个大体的架构图:
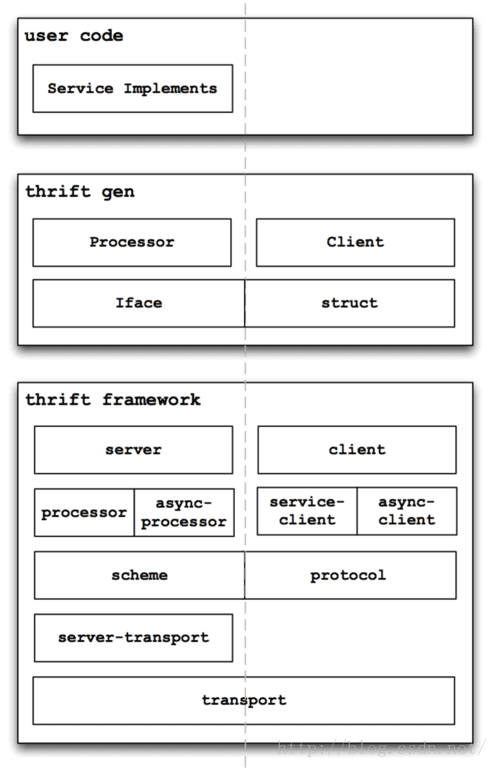
后面也准备专门做一期分享,介绍一下thrift(thrift的代码写的真是很不错,分层结构写的相当好,极力推荐阅读~)。
分布式Cache:
谈互联网,就一定要谈谈cache,因为没有这个玩意儿,我们好多服务器都是扛不住的。
cache的作用,就是用来缓存一些不变的数据,用内存的高速访问替代磁盘的低速读取,尽量用最快的速度,将信息返回给用户。具体工作图如下:
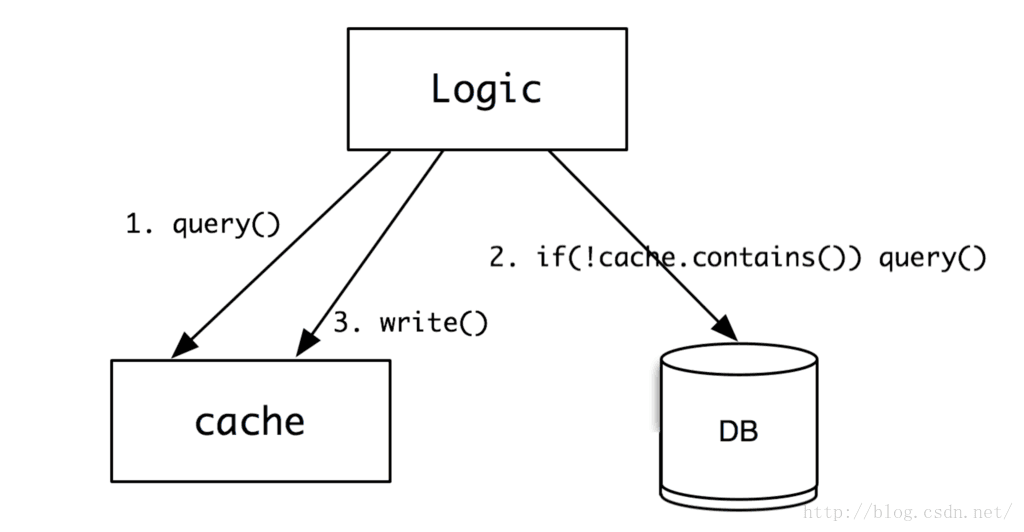
1、逻辑系统先查询cache是否有数据,如果有,就直接返回。如果没有,则进行第2步;
2、从数据库查询,如果没有,则直接返回空;否则,进行第3步;
3、将数据写入到cache中,这样下次再来查询的时候,就有数据了。
因为cache的数据一般是放在内存的,所以读写速度都比db高1-2个数量级,也就是10-100倍的速度于db。现在几乎大部分的网站都是有使用cache的,很难有网站直接用db扛住所有压力(如果压力不大的除外)。不过,使用cache也带来其他的问题,比如架构和代码逻辑变复杂、cache失效等的问题。不过总体来看,cache带来的好处远大于他的问题。
因为cache一般采用内存,所以单机的cache很容易收到内存大小的限制。我们一般会采用分布式cache集群,将缓存放到多个机器上。那就存在一个问题了,一个key的数据到底放在哪儿?后面要的时候怎么去取呢?
这里有两种方式:
1、集中管理:增加一个类似于Naming Service的服务,告诉调用者数据究竟在哪儿?
2、分散管理:调用者通过一定的算法(比如一致hash和Gossip),通过一定的计算,确定数据存放或者获取的位置。
我们常见的分布式cache有memcache、redis等。这些都是非常著名的NoSQL数据库,用作缓存非常适合。他们对数据的管理,一般是采用分散管理的模式。客户端通过一致Hash算法确定数据存放位置。大家有兴趣可以去读读源代码(老王没有读过,后面准备读读~)。
====又是分割线 ====
好啦,这次给大家分享了一些常用的分布式组件,这些组件可以让我们的架构具有非常大的弹性,提升我们系统的性能和容量。其他还有很多的组件,就不在这里一一介绍了。接下来,老王会慢慢给大家具体介绍每个组件的详细工作原理和设计开发中遇到的问题等。有兴趣的同学赶紧关注老王的微信吧:simplemain。
ps:下周会跟大家扯一些通用的互联网功能系统,比如:微博和微信朋友圈的内容聚合系统、内容检索系统等等。应该很有意思~
那今天就到这里啦~ 下周日老王继续在这里给大家扯技术的淡~
