1 - MNIST数字识别问题
前面介绍了这样用TensorFlow训练一个神经网络模型和主要考虑的问题及解决这些问题的常用方法。下面我们用一个实际的问题来验证之前的解决方法。
我们使用的是MNIST手写数字识别数据集。在很多深度学习教程中,这个数据集都会被当做一个案例。
1.1 - MNIST数据处理
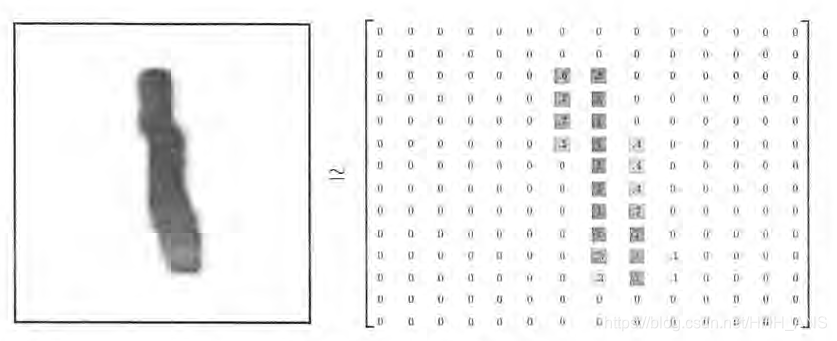
MNIST是一个非常有名的手写体数字识别数据集,在很多资料中,这个数据集都会被用作深度学习的入门样例。TensorFlow的封装让使用MNIST数据集变得更加方便。MNIST数据集是NIST数据集的一个子集,它包含了60000张图片作为训练数据,10000张图片作为测试数据。在MNIST数据集中的每一张图片都代表了0~9中的一个数字。图片的大小都为28X28,且数字都会出现在图片的正中间。下图展示了一张数字图片及和它对应的像素矩阵。
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
- Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
- Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
- Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
- Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
虽然这个数据集只提供了训练和测试数据,但是为了验证模型训练的效果,一般会从训练数据中划分出一部分数据作为验证数据。为了方便使用,TensorFlow提供了一个类来处理MNIST数据。这个类会自动下载并转化MNIST数据的格式,将数据从原始的数据包中解析成训练和测试神经网络时使用的格式。下面给出了使用这个函数的样例程序。
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
from tensorflow.examples.tutorials.mnist import input_data
#载入MNIST数据集,如果指定地址/path/to/MNIST_data下没有已经下载好的数据,
#那么TensorFlow会自动从上述网址中下载数据
mnist = input_data.read_data_sets("/path/to/MNIST_data", one_hot=True)
#打印Training data size:55000
print("Traning data size:",mnist.train.num_examples)
#打印Validating data size :5000
print("Validating data size:",mnist.validation.num_examples)
#打印Testing data size: 10000
print("Testing data size:",mnist.test.num_examples)
从上面的代码可以看出,通过input_data.read_data_sets函数生成的类会自动将MNIST数据集划分成为train、validation和test三个数据集。处理后的每一张图片是一个长度为784的一维数组,这个数组中的元素对应了图片像素矩阵中的每一个数字(28X28=784)。因为神经网络的输入是一个特征向量,所以在此把一张二维图像的像素矩阵放到一个一维数组中,可以方便TensorFlow将图片的像素矩阵提供给神经网络的输入层。像素矩阵中元素的取值范围为【0,1】,它代表了颜色的深浅。
为了方便使用随机梯度下降,它可以从所有的训练数据中读取一小部分作为一个训练的batch,以下代码显示了如何使用这个功能。
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
from tensorflow.examples.tutorials.mnist import input_data
#载入MNIST数据集,如果指定地址/path/to/MNIST_data下没有已经下载好的数据,
#那么TensorFlow会自动从上述网址中下载数据
mnist = input_data.read_data_sets("/path/to/MNIST_data", one_hot=True)
batch_size = 100
xs,ys = mnist.train.next_batch(batch_size)
#从train的集合中选取batch_size个训练数据。
print("X shape:", xs.shape)
#输出X shape:(100,784)
print("Y shape:", ys.shape)
#输出Y shape:(100,100)
1.2 - MNIST数据可视化
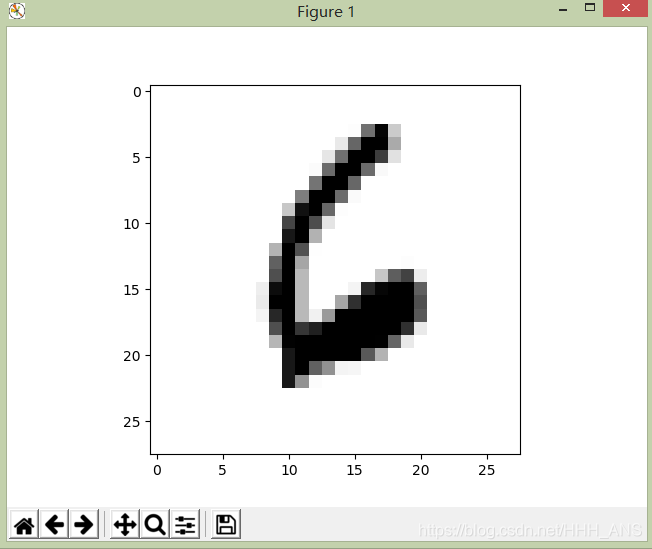
我们可以用以下代码将MNIST中的图片显示出来:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
from tensorflow.examples.tutorials.mnist import input_data
index=3
#载入MNIST数据集,如果指定地址/path/to/MNIST_data下没有已经下载好的数据,
#那么TensorFlow会自动从上述网址中下载数据
mnist = input_data.read_data_sets("/path/to/MNIST_data", one_hot=True)
image=np.reshape(mnist.train.images[index],[28,-1])
print(mnist.train.labels[index]) #显示label
plt.imshow(image, cmap=plt.get_cmap('gray_r')) #画图
plt.show()
输出:[0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
应该显示的是“6”这个数字的图片
2 - 神经网络模型训练及不同模型结果对比
下面我们要用不同的优化方法来观察神经网络模型在MNIST测试数据集上的表现,看看这些优化方法到底对神经网络分类的正确率有多少提升。(神经网络的各种优化方法在机器学习笔记(十)有详细介绍)
2.1 - TensorFlow训练神经网络
先在MNIST数据集上实现一个完整的TensorFlow程序:
# -*- coding: utf-8 -*-
# 由于书上使用的TensorFlow版本比较旧,所以有些代码有所改动,
# 本人使用的TensorFlow版本为1.2.0
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 定义MNIST数据集相关的常数
INPUT_NODE = 784 # 每一张图片都是28*28的
OUTPUT_NODE = 10 # 输出是一个10分类
LAYER1_NODE = 500 # 隐藏层节点数
BATCH_SIZE = 100 # 每个Batch的大小
LEARNING_RATE_BASE = 0.8 # 最开始的学习率
LEARNING_RATE_DECAY = 0.99 # 在指数衰减学习率的过程中用到
REGULARIZATION_RATE = 0.0001 # 描述模型复杂度的正则化项在损失函数中的系数
TRAINING_STEPS = 30000 # 训练轮数,注意,训练一个Batch就是一个step
MOVING_AVERAGE_DECAY = 0.99 # 滑动平均模型的衰减率,最后我会讲解滑动平均模型
# 一个辅助函数,给定神经网络的输入和所有参数,计算神经网络的前向传播结果。在这里
# 定义了一个使用ReLU激活函数的三层全连接神经网络。通过加入隐藏层实现了多层网络结构
# 通过ReLU激活函数实现了去线性化。在这个函数中也支持传入用于计算参数平均值的类,
# 这样方便在测试时使用滑动平均模型。
def inference(input_tensor, avg_class, weights1, biases1,
weights2, biases2):
# 当没有提供滑动平均类时,直接使用参数当前的取值
if avg_class == None:
# 计算隐藏层的前向传播结果,这里使用了ReLU激活函数。
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
# 计算输出层的前向传播结果。因为在计算损失函数时会一并计算softmax函数,
# 所以这里不需要加入激活函数。而且不加入softmax不会影响预测结果。因为预测时
# 使用的是不同类别对应节点输出值的相对大小,有没有softmax层对最后分类结果的
# 计算没有影响。于是在计算整个神经网络的前向传播时可以不加入最后的softmax层。
return tf.matmul(layer1, weights2) + biases2
else:
# 首先使用avg_class.average函数来计算得出变量的滑动平均值,
# 然后再计算相应的神经网络前向传播结果。
layer1 = tf.nn.relu(
tf.matmul(input_tensor, avg_class.average(weights1)) +
avg_class.average(biases1)
)
return tf.matmul(layer1, avg_class.average(weights2)) + \
avg_class.average(biases2)
# 训练模型的过程
# 写TensorFlow程序的时候一定要注意逻辑结构,一般都是下面这个结构:
# 1. 搭建模型:数据输入、数据label、权值初始化、前向传播、反向传播、更新参数
# 2. 运行模型:上面虽然把模型已经搭建好了,但是模型没有真正运行起来
def train(mnist):
# 模型的输入
x = tf.placeholder(tf.float32, [None, INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name='y-input')
# 生成隐藏层的参数
weights1 = tf.Variable(
tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1)
)
biases1 = tf.Variable(
tf.constant(0.1, shape=[LAYER1_NODE])
)
# 生成输出层的参数
weights2 = tf.Variable(
tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1)
)
biases2 = tf.Variable(
tf.constant(0.1, shape=[OUTPUT_NODE])
)
# 注意这里:计算在当前参数下神经网络前向传播的结果。这里给出的用于计算滑动平均的类为None,
# 所以函数不会使用参数的滑动平均值。
y = inference(x, None, weights1, biases1, weights2, biases2)
# 定义存储训练轮数的变量。这个变量不需要计算滑动平均值,所以这里指定这个变量为
# 不可训练的变量(trainable=False)。在使用TensorFlow训练神经网络时,
# 一般会将代表训练轮数的变量指定为不可训练的参数。
# 为什么要把它设为0,参见学习率指数衰减的公式,最开始的指数我们让它为0
# 而且在训练过程中,每一次train_step,global_step都会增加1,所以后面这个值会越来越大
global_step = tf.Variable(0, trainable=False)
# 给定滑动平均衰减率和训练轮数的变量,初始化滑动平均类。在第4章中介绍过给
# 定训练轮数的变量可以加快训练早期变量的更新速度。
variable_averages = tf.train.ExponentialMovingAverage(
MOVING_AVERAGE_DECAY, global_step
)
# 在所有代表神经网络参数的变量上使用滑动平均。其他辅助变量(比如global_step)就
# 不需要了。tf.trainable_variable返回的就是图上集合
# GraphKeys.TRAINABLE_VARIABLES中的元素。这个集合的元素就是所有没有指定
# trainable=False的参数。
variable_averages_op = variable_averages.apply(
tf.trainable_variables()
)
# 注意这个与上面的y有什么区别。计算使用了滑动平均之后的前向传播结果。第4章中介绍过滑动平均不会改变
# 变量本身的取值,而是会维护一个影子变量来记录其滑动平均值。所以当需要使用这个滑动平均值时,
# 需要明确调用average函数。
average_y = inference(
x, variable_averages, weights1, biases1, weights2, biases2
)
# 计算交叉熵作为刻画预测值和真实值之间差距的损失函数。这里使用了TensorFlow中提
# 供的sparse_softmax_cross_entropy_with_logits函数来计算交叉熵。当分类
# 问题只有一个正确答案时,可以使用这个函数来加速交叉熵的计算。MNIST问题的图片中
# 只包含了0~9中的一个数字,所以可以使用这个函数来计算交叉熵损失。这个函数的第一个
# 参数是神经网络不包括softmax层的前向传播结果,第二个是训练数据的正确答案。因为
# 标准答案是一个长度位10的一维数组,而该函数需要提供的是一个正确答案的数字,所以需
# 要使用tf.argmax函数来得到正确答案对应的类别编号。
# 注意这里用的是y来计算交叉熵而不是average_y
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=y, labels=tf.argmax(y_, 1)
)
# 计算在当前batch中所有样例的交叉熵平均值
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# 计算L2正则化损失函数
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
# 计算模型的正则化损失。一般只计算神经网络边上权重的正则化损失,而不使用偏置项。
regularization = regularizer(weights1) + regularizer(weights2)
# 总损失等于交叉熵损失和正则化损失的和
loss = cross_entropy_mean + regularization
# 设置指数衰减的学习率
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE, # 基础的学习率,随着迭代的进行,更新变量时使用的
# 学习率在这个基础上递减
global_step, # 当前迭代的轮数
mnist.train.num_examples / BATCH_SIZE, # 过完所有的训练数据需要的迭代次数
LEARNING_RATE_DECAY # 学习率的衰减速度
)
# 使用tf.train.GradientDescentOptimizer优化算法来优化损失函数。注意这里损失函数
# 包含了交叉熵损失和L2正则化损失。
# 在这个函数中,每次执行global_step都会加一。注意这个函数优化的损失函数跟y有关,
# 跟average_y无关。
train_step = tf.train.GradientDescentOptimizer(learning_rate)\
.minimize(loss, global_step=global_step)
# 在训练神经网络模型时,每过一遍数据既需要通过反向传播来更新神经网络中的参数,
# 又要更新每个参数的滑动平均值。为了一次完成多个操作,TensorFlow提供了
# tf.control_dependencies和tf.group两种机制。下面两行程序和
# train_op = tf.group(train_step, variables_average_op)是等价的。
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train') # tf.no_op是一个没有实际意义的函数
# 检验使用了滑动平均模型的神经网络前向传播结果是否正确。tf.argmax(average_y, 1)
# 计算每一个样例的预测结果。其中average_y是一个batch_size * 10的二维数组,每一行
# 表示一个样例的前向传播结果。tf.argmax的第二个参数“1”表示选取最大值的操作仅在第一
# 个维度中进行,也就是说,只在每一行选取最大值对应的下标。于是得到的结果是一个长度为
# batch的一维数组,这个一维数组中的值就表示了每一个样例对应的数字识别结果。tf.equal
# 判断两个张量的每一维是否相等,如果相等返回True,否则返回False。
correct_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1))
# 注意这个accuracy是只跟average_y有关的,跟y是无关的
# 这个运算首先讲一个布尔型的数值转化为实数型,然后计算平均值。这个平均值就是模型在这
# 一组数据上的正确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 前面的所有步骤都是在构建模型,将一个完整的计算图补充完了,现在开始运行模型
# 初始化会话并且开始训练过程
with tf.Session() as sess:
# 初始化变量
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 准备验证数据。一般在神经网络的训练过程中会通过验证数据要大致判断停止的
# 条件和评判训练的效果。
validate_feed = {
x: mnist.validation.images,
y_: mnist.validation.labels
}
# 准备测试数据。在真实的应用中,这部分数据在训练时是不可见的,这个数据只是作为
# 模型优劣的最后评价标准。
test_feed = {
x: mnist.test.images,
y_: mnist.test.labels
}
# 认真体会这个过程,整个模型的执行流程与逻辑都在这一段
# 迭代的训练神经网络
for i in range(TRAINING_STEPS):
# 每1000轮输出一次在验证数据集上的测试结果
if i % 1000 == 0:
# 计算滑动平均模型在验证数据上的结果。因为MNIST数据集比较小,所以一次
# 可以处理所有的验证数据。为了计算方便,本样例程序没有将验证数据划分为更
# 小的batch。当神经网络模型比较复杂或者验证数据比较大时,太大的batch
# 会导致计算时间过长甚至发生内存溢出的错误。
# 注意我们用的是滑动平均之后的模型来跑我们验证集的accuracy
validate_acc = sess.run(accuracy, feed_dict=validate_feed)
print("After %d training step(s), validation accuracy "
"using average model is %g " % (i, validate_acc))
# 产生这一轮使用的一个batch的训练数据,并运行训练过程。
xs, ys = mnist.train.next_batch(BATCH_SIZE)
sess.run(train_op, feed_dict={x: xs, y_: ys})
# 在训练结束之后,在测试数据上检测神经网络模型的最终正确率。
# 同样,我们最终的模型用的是滑动平均之后的模型,从这个accuracy函数
# 的调用就可以看出来了,因为accuracy只与average_y有关
test_acc = sess.run(accuracy, feed_dict=test_feed)
print("After %d training step(s), test accuracy using average "
"model is %g" % (TRAINING_STEPS, test_acc))
# 主程序入口
def main(argv=None):
# 声明处理MNIST数据集的类,这个类在初始化时会自动下载数据。
mnist = input_data.read_data_sets("/path/to/MNIST_data", one_hot=True)
train(mnist)
# TensorFlow提供的一个主程序入口,tf.app.run会调用上面定义的main函数
if __name__ == "__main__":
tf.app.run()
After 0 training step(s), validation accuracy using average model is 0.129
After 1000 training step(s), validation accuracy using average model is 0.9752
After 2000 training step(s), validation accuracy using average model is 0.9816
·
·
·After 25000 training step(s), validation accuracy using average model is 0.9862
After 26000 training step(s), validation accuracy using average model is 0.9858
After 27000 training step(s), validation accuracy using average model is 0.986
After 28000 training step(s), validation accuracy using average model is 0.987
After 29000 training step(s), validation accuracy using average model is 0.9862
After 30000 training step(s), test accuracy using average model is 0.9848
3 - 变量管理
在前面的实例中,我们使用了
def inference(input_tensor, avg_class, weights1, biases1,weights1, biases2):
这个函数来得到前向传播的结果。但是从这个函数定义我们不难看出如果当神经网络的结构更加复杂之后,需要传递进去的参数weights和biases也会变多,从而就需要一个更好的方式来传递和管理神经网络中的参数了。
TensorFlow提供了通过变量名称来创建或者获取一个变量的机制。
- tf.get_variable
- tf.variable_scope
通过这个机制,在不同的函数中可以直接通过变量的名字来使用变量。
tf.get_variable函数与tf.Variable函数最大的区别在于指定变量名称的参数。
tf.get_variable函数的变量名称是一个必填的参数。会根据这个名字去创建或获取变量。
通过上面2个函数,对计算前向传播结果的函数做了一些改进。
import tensorflow as tf
def inference(input_tensor,reuse = False):
#定义第一层神经网络的变量和前向传播过程。
with tf.variable_scope('layer1',reuse=reuse):
#根据传进来的reuse来判断是创建新变量还是使用已经创建好的,在第一次构造网络时
#需要创建新的变量,以后每次调用这个函数都直接使用reuse = True就不需要
#每次将变量传进来了
weights = tf.get_variable("weights",[INPUT_NODE,LAYER1_NODE],initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases",[LAYER1_NODE],initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.matmul(input_tensor,weights)+biases)
with tf.variable_scope('layer2',reuse=reuse):
weights = tf.get_variable("weights", [LAYER1_NODE, OUTPUT_NODE],
initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases", [OUTPUT_NODE], initializer=tf.constant_initializer(0.0))
layer2 = tf.nn.relu(tf.matmul(layer1, weights) + biases)
#最后返回前向传播结果
return layer2
new_x = tf.placeholder(tf.float32,[None,INPUT_NODE],name='x-input')
new_y = inference(new_x,True)
使用上面这段代码所示的方式,就不需要需要将所有变量都作为参数传递到不同的函数中了。当神经网络结构更加复杂、参数更多时,使用这种变量管理的方式将大大提高程序的可读性
4 - TensorFlow模型持久化
以上的代码都是在训练完成之后就直接退出了,而且没有将训练得到的模型保存下来方便下次直接使用。为了让训练结果可以复用,TensorFlow可以持久化一个训练好的模型。
4.1 - 持久化代码实现
TensorFlow提供了一个非常简单的API来保存和还原一个神经网络模型。这个API就是tf.train.Saver类。
import tensorflow as tf
#声明两个变量并计算它们的和
v1 = tf.Variable(tf.constant(1.0,shape=[1],name='v1'))
v2 = tf.Variable(tf.constant(2.0,shape=[1],name='v2'))
result = v1 + v2
init_op = tf.global_variables_initializer()
#声明tf.train.Saver类用于保存模型。
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
#将模型保存到/path/to/model/model.ckpt文件
saver.save(sess,"/path/to/model/model.ckpt")
上面的代码将模型保存到了/path/to/model/model.ckpt文件中,文件目录下会出现三个文件。因为TensorFlow会将计算图的结构和图上参数取值分开保存。
以下代码给出了加载这个已经保存的TensorFlow模型的方法
import tensorflow as tf
#使用和保存模型代码中一样的方法来声明变量
v1 = tf.Variable(tf.constant(1.0,shape=[1],name='v1'))
v2 = tf.Variable(tf.constant(2.0,shape=[1],name='v2'))
result = v1 + v2
saver = tf.train.Saver()
with tf.Session() as sess:
#加载已经保存的模型,并通过已经保存的模型变量值来计算加法。
saver.restore(sess,"/path/to/model/model.ckpt")
print(sess.run(result))
#将模型保存到/path/to/model/model.ckpt文件
或者是
import tensorflow as tf
#使用和保存模型代码中一样的方法来声明变量
saver = tf.train.import_meta_graph("/path/to/model/model.ckpt.meta")
with tf.Session() as sess:
#加载已经保存的模型,并通过已经保存的模型变量值来计算加法。
saver.restore(sess,"/path/to/model/model.ckpt")
print(sess.run(tf.get_default_graph().get_tensor_by_name("add:0")))
#将模型保存到/path/to/model/model.ckpt文件
上面给出的程序中,默认保存和加载了TensorFlow计算图上定义的全部变量,但有可能只需要保存或者加载部分变量。比如,有可能一个之前训练好的五层神经网络模型,但现在想尝试一个六层的神经网络,那么可以将前面五层神经网络的参数直接加载到新的模型,而仅仅将最后一层神经网络重新训练。
为了保存或者加载部分变量,在声明tf.train.Saver类时可以提供一个列表来指定需要保存或加载的变量。
比如saver = tf.train.Saver([v1]),那么只有变量v1会被加载进来
下面给出一个简单的样例程序说明变量重命名是如何被使用的。
import tensorflow as tf
#这里声明的变量名称已经和保存的模型中的变量名称不同
v1 = tf.Variable(tf.constant(1.0,shape=[1],name='other-v1'))
v2 = tf.Variable(tf.constant(2.0,shape=[1],name='other-v2'))
#如果直接使用tf.train.Saver()来加载模型会报变量找不到的错误。
#那么要使用一个字典(dictionary)来重命名变量
saver = tf.train.Saver({"v1":v1,"v2":v2})
5 - TensorFlow最佳实践样例程序
上面实现了一个完整的TensorFlow程序来解决MNIST问题。但是这个程序的可扩展性不好,而且可读性非常差,有很多的冗余代码,并且没有应用持久化机制,没有保存训练的中间结果会浪费大量的时间和资源。所以,在训练的过程中最好需要每隔一段时间保存一次模型训练的中间结果。
因此,重构之后的程序将拆分为3个子程序,
- mnist_inference.py
它定义了前向传播的过程以及神经网络中的参数。 - mnist_train.py
它定义了神经网络的训练过程 - mnist_eval.py
它定义了测试过程。
mnist_inference.py 代码如下:
# -*- coding: utf-8 -*-
import tensorflow as tf
# 定义神经网络结构相关的参数
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
# 通过tf.get_variable函数来获取变量。在训练神经网络时会创建这些变量;在测试时会通
# 过保存的模型加载这些变量的取值。而且更加方便的是,因为可以在变量加载时将滑动平均变
# 量重命名,所以可以直接通过相同的名字在训练时使用变量自身,而在测试时使用变量的滑动
# 平均值。在这个函数中也会将变量的正则化损失加入到损失集合。
def get_weight_variable(shape, regularizer):
weights = tf.get_variable(
"weights", shape,
initializer=tf.truncated_normal_initializer(stddev=0.1)
)
# 当给出了正则化生成函数时,将当前变量的正则化损失加入名字为losses的集合。在这里
# 使用了add_to_collection函数将一个张量加入一个集合,而这个集合的名称为losses。
# 这是自定义的集合,不在TensorFlow自动管理的集合列表中。
if regularizer != None:
tf.add_to_collection('losses', regularizer(weights))
return weights
# 定义神经网络的前向传播过程
def inference(input_tensor, regularizer):
# 声明第一层神经网络的变量并完成前向传播过程。
with tf.variable_scope('layer1'):
# 这里通过tf.get_variable或者tf.Variable没有本质区别,因为在训练或者测试
# 中没有在同一个程序中多次调用这个函数。如果在同一个程序中多次调用,在第一次
# 调用之后需要将reuse参数设置为True。
weights = get_weight_variable(
[INPUT_NODE, LAYER1_NODE], regularizer
)
biases = tf.get_variable(
"biases", [LAYER1_NODE],
initializer=tf.constant_initializer(0.0)
)
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights)+biases)
# 类似的声明第二层神经网络的变量并完成前向传播过程。
with tf.variable_scope('layer2'):
weights = get_weight_variable(
[LAYER1_NODE, OUTPUT_NODE], regularizer
)
biases = tf.get_variable(
"biases", [OUTPUT_NODE],
initializer=tf.constant_initializer(0.0)
)
layer2 = tf.matmul(layer1, weights) + biases
# 返回最后前向传播的结果
return layer2
** mnist_train.py代码如下**
import os
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#加载mnist_inference.py中定义的常量和前向传播的函数。
import mnist_inference
BATCH_SIZE = 100 # 每个Batch的大小
LEARNING_RATE_BASE = 0.8 # 最开始的学习率
LEARNING_RATE_DECAY = 0.99 # 在指数衰减学习率的过程中用到
REGULARIZATION_RATE = 0.0001 # 描述模型复杂度的正则化项在损失函数中的系数
TRAINING_STEPS = 30000 # 训练轮数,注意,训练一个Batch就是一个step
MOVING_AVERAGE_DECAY = 0.99 # 滑动平均模型的衰减率,最后我会讲解滑动平均模型
#模型保存的路径和中文名
MODEL_SAVE_PATH = "/path/to/model/"
MODEL_NAME = "model.ckpt"
def train(mnist):
# 定义输入输出placeholder。
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
# 直接使用mnist_inference.py中定义的前向传播过程
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
# 定义损失函数、学习率、滑动平均操作以及训练过程
variable_averages = tf.train.ExponentialMovingAverage(
MOVING_AVERAGE_DECAY, global_step
)
variable_averages_op = variable_averages.apply(
tf.trainable_variables()
)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=y, labels=tf.argmax(y_, 1)
)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY
)
train_step = tf.train.GradientDescentOptimizer(learning_rate)\
.minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
# 初始化TensorFlow持久化类
saver = tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
# 在训练过程中不再测试模型在验证数据上的表现,验证和测试的过程将会有一个独
# 立的程序来完成。
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, step = sess.run([train_op, loss, global_step],
feed_dict={x: xs, y_: ys})
# 每1000轮保存一次模型
if i % 1000 == 0:
# 输出当前的训练情况。这里只输出了模型在当前训练batch上的损失
# 函数大小。通过损失函数的大小可以大概了解训练的情况。在验证数
# 据集上正确率的信息会有一个单独的程序来生成
print("After %d training step(s), loss on training "
"batch is %g." % (step, loss_value))
# 保存当前的模型。注意这里给出了global_step参数,这样可以让每个
# 被保存的模型的文件名末尾加上训练的轮数,比如“model.ckpt-1000”,
# 表示训练1000轮之后得到的模型。
saver.save(
sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME),
global_step=global_step
)
# 主程序入口
def main(argv=None):
# 声明处理MNIST数据集的类,这个类在初始化时会自动下载数据。
mnist = input_data.read_data_sets("/path/to/MNIST_data", one_hot=True)
train(mnist)
# TensorFlow提供的一个主程序入口,tf.app.run会调用上面定义的main函数
if __name__ == "__main__":
tf.app.run()
After 1 training step(s), loss on training batch is 2.823.
After 1001 training step(s), loss on training batch is 0.236903.
After 2001 training step(s), loss on training batch is 0.248572.
·
·
·
After 26001 training step(s), loss on training batch is 0.0374676.
After 27001 training step(s), loss on training batch is 0.0378088.
After 28001 training step(s), loss on training batch is 0.0375806.
After 29001 training step(s), loss on training batch is 0.0363075.
可以看到误差从2.8经过训练下降到0.036
在训练代码中,不再将训练和测试跑在一起,训练过程中,每1000轮输出一次在当前训练batch上损失函数的大小来大致估计训练的效果。在上面的程序中,每1000轮保存一次训练好的模型,这样可以通过一个单独的测试程序,更加方便的滑动平均模型上做测试。
# -*- coding: utf-8 -*-
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 加载mnist_inference.py 和mnist_train.py中定义的常量和函数。
import mnist_inference
import mnist_train
# 每10秒加载一次最新的模型,并且在测试数据上测试最新模型的正确率
EVAL_INTERVAL_SECS = 10
def evaluate(mnist):
with tf.Graph().as_default() as g:
# 定义输入输出的格式。
x = tf.placeholder(
tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input'
)
y_ = tf.placeholder(
tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input'
)
validate_feed = {x: mnist.validation.images,
y_: mnist.validation.labels}
# 直接通过调用封装好的函数来计算前向传播的结果。因为测试时不关注ze正则化损失的值
# 所以这里用于计算正则化损失的函数被设置为None。
y = mnist_inference.inference(x, None)
# 使用前向传播的结果计算正确率。如果需要对未知的样例进行分类,那么使用
# tf.argmax(y,1)就可以得到输入样例的预测类别了。
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 通过变量重命名的方式来加载模型,这样在前向传播的过程中就不需要调用求滑动平均
# 的函数来获取平均值了。这样就可以完全共用mnist_inference.py中定义的
# 前向传播过程。
variable_averages = tf.train.ExponentialMovingAverage(
mnist_train.MOVING_AVERAGE_DECAY
)
variables_to_restore = variable_averages.variables_to_restore()
saver = tf.train.Saver(variables_to_restore)
# 每隔EVAL_INTERVAL_SECS秒调用一次计算正确率的过程以检验训练过程中正确率的
# 变化。
while True:
with tf.Session() as sess:
# tf.train.get_checkpoint_state函数会通过checkpoint文件自动
# 找到目录中最新模型的文件名。
ckpt = tf.train.get_checkpoint_state(
mnist_train.MODEL_SAVE_PATH
)
if ckpt and ckpt.model_checkpoint_path:
# 加载模型。
saver.restore(sess, ckpt.model_checkpoint_path)
# 通过文件名得到模型保存时迭代的轮数。
global_step = ckpt.model_checkpoint_path\
.split('/')[-1].split('-')[-1]
accuracy_score = sess.run(accuracy,
feed_dict=validate_feed)
print("After %s training step(s), validation "
"accuracy = %g" % (global_step, accuracy_score))
else:
print("No checkpoint file found")
return
time.sleep(EVAL_INTERVAL_SECS)
#主程序入口
def main(argv=None):
# 声明处理MNIST数据集的类,这个类在初始化时会自动下载数据。
mnist = input_data.read_data_sets("/path/to/MNIST_data", one_hot=True)
evaluate(mnist)
# TensorFlow提供的一个主程序入口,tf.app.run会调用上面定义的main函数
if __name__ == "__main__":
tf.app.run()