版权声明:Collected by Bro_Rabbit only for study https://blog.csdn.net/weixin_38240095/article/details/83267933
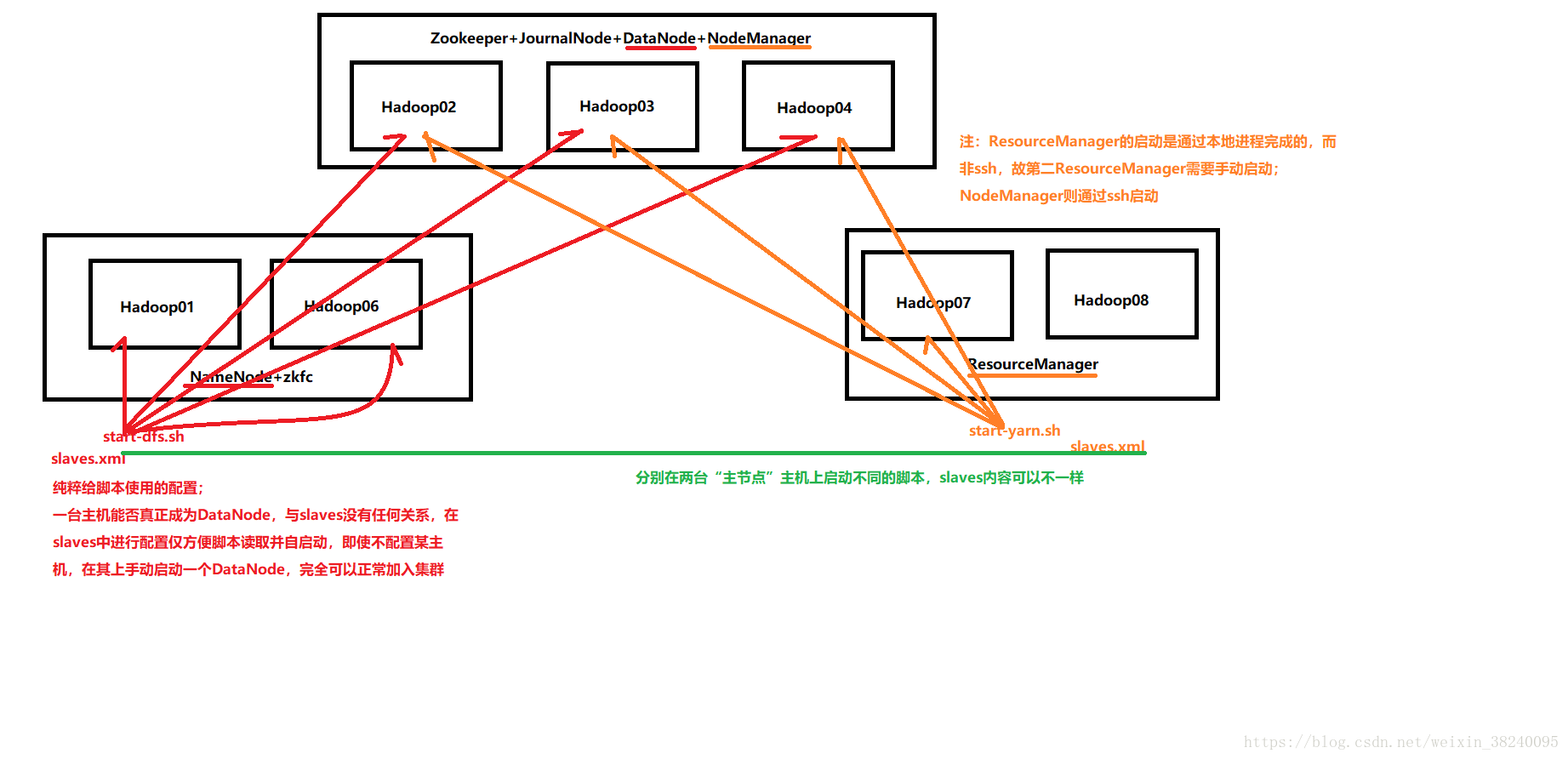
- 节点规划方案
-(NameNode+ZKFC)*2
-(Zookeeper+JournalNode+DataNode+NodeManager)
注:DataNode与NodeManager最好放在一起,符合 “数据不动,计算移动” 的原则
-ResourceManager*2
具体分配如图:
- 修改配置文件(Hadoop01,NameNode+ZKFC主机)
(1)core-site.xml
(2)hdfs-site.xml<configuration> <!-- 指定hdfs对外的NamService标识为ns1 --> <property> <name>fs.defaultFS</name> <value>hdfs://ns1/</value> </property> <!-- 指定hadoop临时目录 --> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoopApp/…/tmp</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>{ZookeeperHost01}:2181,{ZookeeperHost02}:2181,{ZookeeperHost03}:2181</value> </property> </configuration><configuration> <!--指定hdfs的对外NameService的标识为ns1,需要和core-site.xml中的保持一致 --> <property> <name>dfs.nameservices</name> <value>ns1(,ns2,ns3…)</value> </property> <!-- ns1下面有两个NameNode,分别是nn1,nn2(逻辑id)--> <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>Hadoop01:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>Hadoop01:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>Hadoop06:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>Hadoop06:50070</value> </property> <!-- 指定NameNode的元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://{QJHost01}:8485;{QJHost02}:8485;{QJHost03}:8485/ns1</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/hadoopApp/…/journaldata</value> </property> <!-- 开启NameNode失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式(默认是apache) --> <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置fencing机制方法,多个机制用换行区分,即每个机制占用一行--> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence <!--sshfence超时后,调用shell保底切换,最好配置--> {shell}(处理脚本的路径) </value> </property> <!-- 使用sshfence隔离机制时需要ssh免密登录 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间,ms --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> </configuration>
(3)mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(4)yarn-site.xml
<configuration>
<!-- 开启ResourceManager高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定ResourceManager的Cluster-id(自定义) -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定ResourceManager的id(自定义) -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>Hadoop07</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>Hadoop08</value>
</property>
<!-- 指定Zookeeper集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>ZookeeperHost01:2181,ZookeeperHost02:2181,ZookeeperHost03:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(5)slaves
slaves指定子节点的位置,因此在HDFS节点(Hadoop1,Hadoop06)上指定为DataNode的位置,在Yarn节点(Hadoop07,Hadoop08)上指定为NodeManager的位置
(6)zoo.cfg没有额外改动,使用上一节配置
-
SSH配置
(1)在Hadoop01(NN1)上#生成密钥对 ssh-keygen -t rsa #自动设置免密授权信息 ssh-copy-id Hadoop01/Hadoop06/Hadoop02/Hadoop03/Hadoop04(2)在Hadoop06(NN2)上,NameNode需要双向通信
ssh-keygen -t rsa ssh-copy-id Hadoop01 -
分发配置
注:修改slaves为对应的子节点scp -r /home/hadoopApp/Hadoop-2.9.0 Hadoop06:/home/Hadoop/hadoopApp/ -
集群启动(必须严格按照步骤)
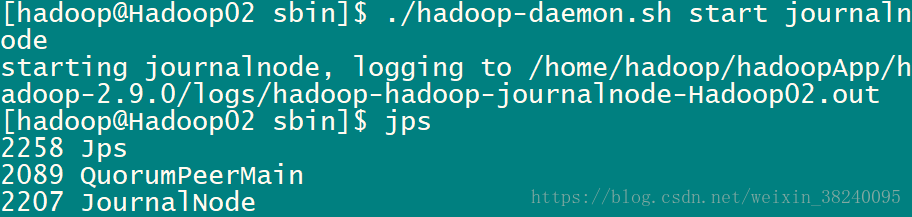
(1)启动Zookeeper集群 (分别在Hadoop02/Hadoop03/Hadoop04上启动)cd /…/zookeeper-3.4.5/bin/ ./zkServer.sh start #查看状态:一个leader,两个follower ./zkServer.sh status(2)启动JournalNode(分别在Hadoop02/Hadoop03/Hadoop04上启动,第一次必须手动,之后自动加入hdfs-start.sh)
cd /…/hadoop-2.4.1/sbin ./hadoop-daemon.sh start journalnode(3)格式化HDFS(仅第一次启动前需要格式化)
#在任一个指定的NameNode上执行命令: hdfs namenode -format #格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成文件,这里配置的是/hadoop/hadoop-2.9.0/tmp,然后将/hadoop/hadoop-2.9.0/tmp拷贝到另一个NameNode的/hadoop/hadoop-2.9.0/下。 scp -r tmp/ Hadoop06:/home/hadoop/app/hadoop-2.9.0/ ##建议hdfs namenode -bootstrapStandby(4)格式化ZKFC(在Hadoop01上执行,仅第一次需要格式化,之后自动加入hdfs-start.sh)
hdfs zkfc -formatZK(5)启动HDFS(在Hadoop1上执行,或有slaves的节点)
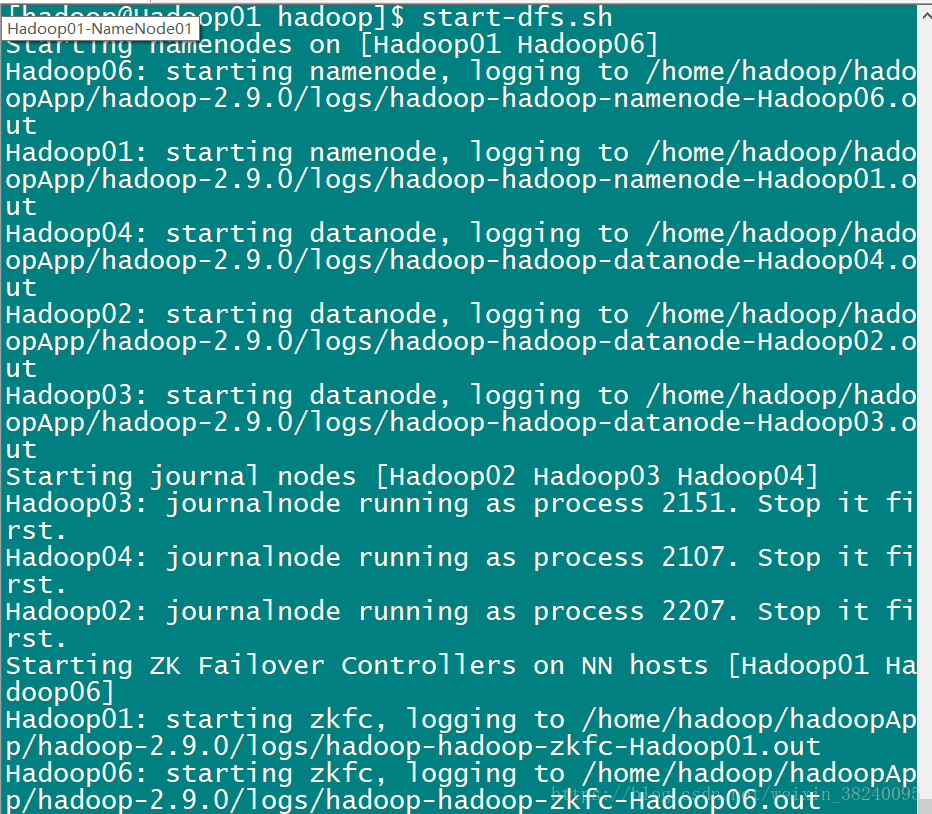
start-dfs.sh
(6)启动Yarn(在Hadoop07上执行,启动本地进程并根据slaves启动NodeManager节点)start-yarn.sh另一个ResourceManager需要在Hadoop08上执行yarn-daemon.sh
-
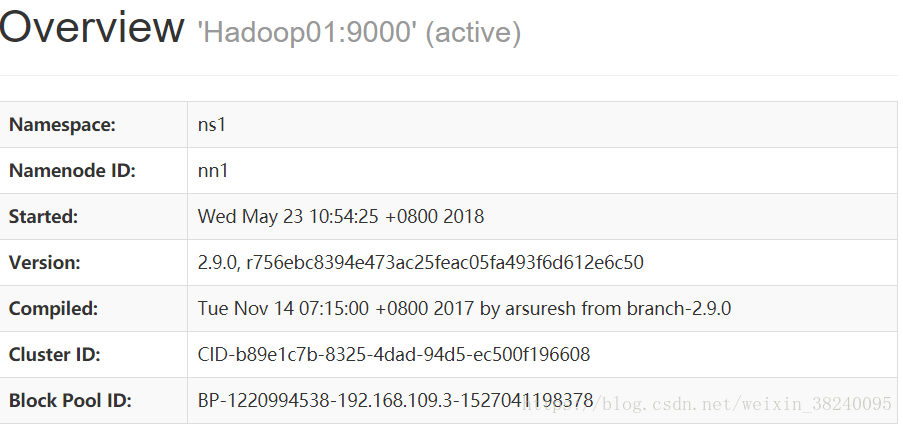
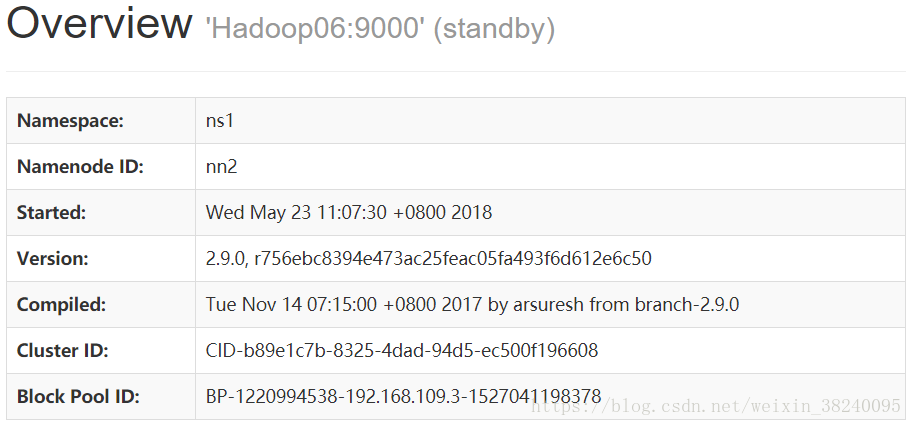
通过浏览器访问50070