一、前言
论文 Towards End-to-end Text Spotting with Convolutional Recurrent Neural Networks
在这篇文章中,解决了在基于CRNN自然场景下图像的文本检测与识别的问题。我们提议同时本地化和统一的网络用单个向前通道识别文本,避免中间图像裁剪和特征处理重新计算、单词分离或字符分组。
① 与现有方法相比,考虑到文本检测和识别作为两个不同的任务,解决他们的方案是一个接一个,提议的框架(the proposed framework)解决了这些问题,它是并发两个任务。
② 整个框架可以是训练是的端到端,只要有图像,基础边界框和文本标签(boxes and text labels)。通过端到端训练(end-to-end training),学习的特征可以更丰富,从而提高了整体性能。卷积特征只计算一次并共享通过检测和识别,节省了处理时间。我们提出的方法在几个基准数据集的性能测试上取得了竞争优势。
二、改进之处
(1)设计了一种端到端可训练DNN来优化。整体精度和共享计算。网络集成文本检测和文字识别。两种任务都采用端到端训练方式,学习的特征可以更丰富,既可以提高检测性能,又可以提高整体性能。卷积特征由检测和识别共享,这节省了加工时间。据我们所知,这是集成文本检测与识别的首次尝试进入一个单一的端到端可训练网络。
(2)提出了一种新的区域特征提取方法。在以前的作品〔4, 21〕中,感兴趣区域(ROI)池化层将不同大小和宽高比的区域转换成具有固定大小的特征映射【特征图需要归一化】。考虑文本边界框中纵横比的显著差异,修复后的大小是次优的汇集。适应原始纵横比并且避免失真,ROI池是专门生成的。具有不同长度的特征图。RNN编码器然后被用来编码不同的特征映射长度相同大小。
(3)设计课程学习策略。逐步培养更为复杂的培训体系数据。从简单形象的合成图像开始一个大词汇词典,系统学习了字符级语言模型并找到良好的初始化外观模型。采用真实世界用一个小的词汇后来的图像,系统逐渐学习如何处理复杂的外观模式。我们进行一系列实验来探索能力不同的模型结构。最佳模型优于若干标准的最新结果文本识别基准,包括ICDAR2011 2015。
综合来说就是:
(1) 提出端到端的OCR检测+识别的框架
(2) 改进的ROI pooling。相比于fasterRCNN中ROI pooling 只能产生固定长宽的feature map,本文改进的ROI pooling可以产生固定长度,不同宽度的feature map,更适用于文字这样一个有着不同长度的对象,然后经过LSTM产生固定长度的feature。
(3) 基于本文复杂的网络结构,提出了课程学习策略,一种由易到难的学习策略。先使用简单的在彩色背景上写字的合成图片进行训练,然后使用中等难度的在风景图片上写字的合成图片进行训练,最后使用真实的样本图片进行训练。
三、网络整体结构

从网络结构可以看出和faster RCNN的结构很像。主要由TPN,RFE,TDN,TRN几个部分组成。
其中,基础CNN网络结构和faster RCNN一样,都是修改的VGG16结构。
TPN结构与faster RCNN中的RPN功能一样。
RFE模块类似faster RCNN中的ROI pooling 。与TRN(文本识别)模块都用到了LSTM
TDN模块用于文本框的回归和文本框的分数。
TPN(Text Proposal Network )模块

RFE(Region Feature Encoder )(下图左)

TDN (Text Detection Network)
文本检测网络(TDN)的目的是根据提取的区域特征
,判断提出的RoI是否为文本,并再次细化边界框的坐标。将两个具有 2048 个神经元的完全连接层应用于
,然后分别用两个平行层进行分类和bounding boxes(边界盒)回归。
TDN中使用的分类和回归层与TPN中使用的分类和回归层相似。请注意,整个系统细化文本边界框的坐标两次:一次在TPN中,然后在TDN中。虽然两次使用RFE来计算TPN产生的建议以及后来由TDN提供的检测到的边界框的特征,但是卷积特征仅需要计算一次。
TRN(Text Recognition Network )(上图右)
该模块是一个基于 attention 机制的 seq2seq 模型。最终模型输出38维向量(26个字母,10个数字,1个标点符号的代表,一个结束标志EOS)
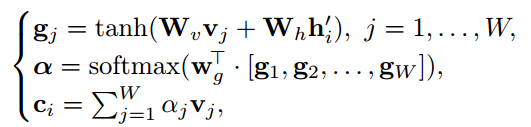
其中,
为特征经过LSTM编码后的输出特征。Hi为解码层的输出值,
为需要学习的嵌入矩阵,
为attention矩阵的权值,
为输入特征的加权求和。
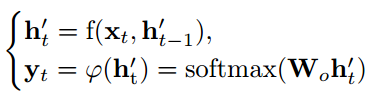
At each time-stept(在每个时间步)
,decoder LSTMs compute their hidden state依据上面公式计算他们的隐藏状态。其中,f()函数为RNN的函数,
为将特征映射到输出空间的映射矩阵。
损失函数
TPN和TDN都采用二分类Logistic损失
进行分类,smoothL1 loss
用于回归。因此training TPN的损失如下:
整个框架的分类为binary_crossentrop,回归为smooth L1
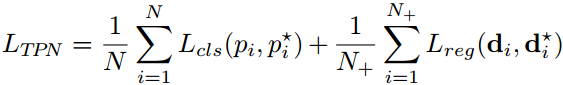
在TPN模块中,正anchor阈值为0.7,负anchor阈值为0.3,N为一个batch中随机选择的anchor个数,为256,N+为正anchor的个数,为128。
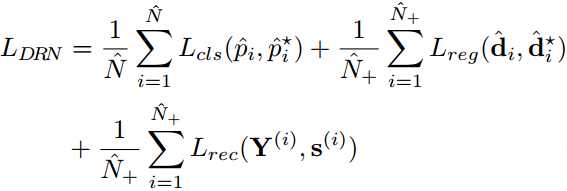
LDR模块中,
为TPN中输出的ROI的个数,为128,
为正的ROI个数,小于等于64。其中,正anchor的阈值为0.6,负anchor的阈值为0.4
Data Augmentation
我们在训练阶段每迭代一个图像。训练图像被调整到600像素的短边和最多1200像素的长边。数据增强也被实现为提高我们的模型的鲁棒性。
- 在不改变图像高度的情况下,将图像的宽度按比例 1或 0.8 随机重新标定,使得边界框具有更多的可变长宽比;
- 随机裁剪包括所有的子图像原始图像中的文本,填充有100个像素每一边,并在短边上调整到600像素。
为了提高课程学习的通用性和加速收敛速度,我们设计了一个课程学习范式来从逐渐复杂的数据中训练模型,详情如下:

模型训练对比
