An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
作者是华中科技大学的白翔老师,这个老师还是很厉害的。论文提出的CRNN模型比较简单,并且泛化能力强,在这里进行模型的复现(使用Tensorflow)和训练,并进行测试,刚开始学,有不对的地方还请大神们多多指教。
模型的结构图是这样的:
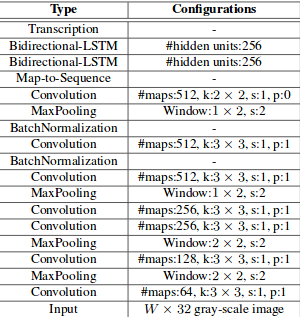
主要分为三个模块:卷积层(主要用来抽取图像特征),双向循环层(用来保存上下文信息),转录层(用来将循环层输出的序列标签预测为结果)
一.转录层
直接上代码,inputs = tf.placeholder(tf.float32, [None, config.IMAGE_HEIGHT,config.IMAGE_WIDTH,1]),高是32,宽是128
def CNNnetwork(inputs): conv1 = tf.layers.conv2d(inputs = inputs, filters = 64, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu) pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2) conv2 = tf.layers.conv2d(inputs = pool1, filters = 128, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu) pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2) conv3 = tf.layers.conv2d(inputs = pool2, filters = 256, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu) conv4 = tf.layers.conv2d(inputs = conv3, filters = 256, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu) pool3 = tf.layers.max_pooling2d(inputs=conv4, pool_size=[1, 2], strides=2) conv5 = tf.layers.conv2d(inputs = pool3, filters = 512, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu) # Batch normalization layer bnorm1 = tf.layers.batch_normalization(conv5) conv6 = tf.layers.conv2d(inputs = bnorm1, filters = 512, kernel_size = (2, 2), padding = "same", activation=tf.nn.relu) #Batch normalization layer bnorm2 = tf.layers.batch_normalization(conv6) pool4 = tf.layers.max_pooling2d(inputs=bnorm2, pool_size=[1, 2], strides=2) //最后一层p是等于0的 h_conv7 = tf.layers.conv2d(inputs = pool4, filters = 512, kernel_size = (2, 2), padding = "valid", activation=tf.nn.relu) return h_conv7
这里还有还有一个map_to_sequence层:也就是将特征图转化为序列
label_seqs=tf.squeeze(cnn_net,axis=1)
这个输出的结果label_seqs才作为双向循环网络的输入。
二.循环层:
这里的循环层是由两个LSTM层组成的。
def BiRNNnetwork(inputs,seq_len):
##这里当初是比较奇怪的地方,因为在tensorflow的实现里,stack_bidirectional_dynamic_rnn也就是下面那个函数,
##输入的tensor必须是[batch_size,max_time,depth],max_time可以简单理解为文本图像的长度width,depth是图像向量的维度。
##这里如果不对inputs进行reshape的话,下面ctc_beam_search的时候会报出sequence(0)<?的错误。因为对其进行reshape了,
##前后数据大小必须一致,所以也是这里的宽度设置成128的原因(原文是100),如果是100的话整除不了,有多的数据,reshape会失败
shape=inputs.get_shape().as_list()
depth=shape[1]*shape[2]/config.IMAGE_WIDTH
batch_size=tf.shape(inputs)[0]
inputs=tf.reshape(inputs,[batch_size,config.IMAGE_WIDTH,depth])
list_n_hidden = [256, 256]
fw_cell_list = [tf.contrib.rnn.BasicLSTMCell(nh, forget_bias=1.0) for nh in list_n_hidden]
bw_cell_list = [tf.contrib.rnn.BasicLSTMCell(nh, forget_bias=1.0) for nh in list_n_hidden]
outputs, _, _ = tf.contrib.rnn.stack_bidirectional_dynamic_rnn(fw_cell_list, bw_cell_list,inputs, dtype=tf.float32)
#测试发现这里的dropout层可有可无,不影响最终效果。
#lstm_net = tf.nn.dropout(outputs, keep_prob=0.5)
lstm_net=tf.concat(outputs,-1)
logits = tf.reshape(lstm_net, [-1, 512])
##这里后面怎么对BLSTM层的输出结果比较不明白,因为原文中对这一部分没有具体说明,只好使用了一个全连接神经网络
##将LSTM输出的512个特征数据再转化为classes数(原文倒是没有提到说要使用全连接神经网络)
W = tf.Variable(tf.truncated_normal([512, config.NUM_CLASSES], stddev=0.1), name="W")
b = tf.Variable(tf.constant(0., shape=[config.NUM_CLASSES]), name="b")
logits = tf.matmul(logits, W) + b
batch_size=tf.shape(inputs)[0]
logits = tf.reshape(logits, [batch_size, -1, config.NUM_CLASSES])
#Final layer, the output of the BLSTM
logits = tf.transpose(logits, (1, 0, 2))
return logits
三.转录层
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(config.INITIAL_LEARNING_RATE,
global_step,
config.DECAY_STEPS,
config.LEARNING_RATE_DECAY_FACTOR,
staircase=True)
targets = tf.sparse_placeholder(tf.int32)
#1维向量 序列长度 [batch_size,]
seq_len = tf.placeholder(tf.int32, [None])
loss = tf.nn.ctc_loss(labels=targets,inputs=logits, sequence_length=seq_len)
cost = tf.reduce_mean(loss)
#这里采用的optimizer策略是Adam算法,原文中采用的是梯度下降,这里我试过,会梯度爆炸。
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss,global_step=global_step)
#这里运行时输出的deceded[0]就是预测结果,不过是个稀疏矩阵,需要转一下,就能看到最终的结果了。
decoded, log_prob = tf.nn.ctc_beam_search_decoder(logits, seq_len,merge_repeated=False)
acc = tf.reduce_mean(tf.edit_distance(tf.cast(decoded[0], tf.int32), targets))
init = tf.global_variables_initializer()
四.模型的训练:
训练模型的时候采用的是跟论文一样的数据,Synth人工合成数据,因为这份数据只有52个英文字母和10个数字的文本图像,所以这里也只训练和测试62个英文字母和数字的文本图像。在训练的时候发现,大概只需要300万张图片就可以收敛了,再多的图片损失都已经降不下来了,这可能是因为原本数据其实都是按几个方式比如旋转之类合成的。函数收敛的过程如下:最终的损失就是在2左右。

五.模型测试
训练出的模型大概80M左右,在ICDAR2013的文本识别测试数集,总共1018(除去带有符号的)张,最终测试得到的准确率为68.8%,与原文中的86%还有些差距。。。随机挑选了人工合成数据中的测试集3000张,准确率为74.6%.下表是ICDAR2013部分的识别结果。
图像 |
Ground Truth |
识别结果 |
|
Education |
Education |
|
Auto |
A |
|
Washing |
Washing |
|
XVII |
XvII |
|
London |
benegen |
|
Verbandstoffe |
Verbandestble |
|
family |
frmidy |



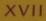


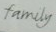
从结果来看,对一些干扰因素少,质量比较高,文字之间少有黏连或倾斜度不大的时候,识别是没有多大问题,但对于一些含复杂背景,像表中的图像London,或者是抖动很厉害,像Verbandstoffe图像,则识别率就比较低了。
总结来看,部分图像识别不正确的原因可归纳为如下几点:
(1)图像本身不容易识别,像表5-2中的Verbandstoffe图像,连人眼都不易识别。不易识别通常是干扰因素多,比如阴影,复杂背景,噪声点,扭曲黏连,旋转等。
(2)识别过程中可能因为一个字符的识别错误进而导致整张图片识别错误,像表中XIVV图像,把字符“I”识别成了小写的字符“i”,类似的错误还比较多,这也可能本身是由于字母大小写不易区分。
(3)训练样本库不够丰富,这一点原因可能是最主要的,因为自然场景中的文字类型千变万化,很难建立一个能包含所有样式的图像数据集。像表中5-2一些测试集上识别错误或几乎无法识别,是因为网络在训练的时候缺乏类似的样本去学习。