MINIST | 基于朴素贝叶斯分类器的0-9数字手写体识别
概要: 本实验基于MINIST数据集,采用朴素贝叶斯分类器,实现了0-9数字手写体的识别。本文将简要介绍这一方法的原理、代码实现以及在编程过程中需要注意的若干问题,代码仍然是用MATLAB写成的。
关键字: MATLAB; 图像处理; 数字手写体识别; 朴素贝叶斯分类器
1 背景说明
我的上一篇博客介绍了基于朴素贝叶斯分类器的语音性别识别,用的也是朴素贝叶斯分类器。我在那篇博客中说“之前曾做过用朴素贝叶斯分类器进行数字手写体识别”并且“之后也将整理到此博客上来”——看来这一篇文章是跑不掉了,那还不如尽早写完——好吧,我今天这是履行诺言来了。不过同样地我也不打算介绍“朴素贝叶斯分类器”到底是什么、可以用来干什么了,因为首先它的原理的确too simple,其次网上这方面的资料非常多,而且讲解的水平比我不知道高到哪里去了。大家可以去我的上一篇博客中的“背景说明”中找我推荐的资料链接。
2 关于数据集
2.1 什么是MINIST
这是我在博客中首次提到MINIST,因此有必要向读者作简要介绍。而且我也打算做一个MINIST的专栏,把自己学过的各种各样的方法——包括传统的方法和学习的方法——都在这个数据集上用一遍,也相当于是学以致用了。
MINIST是一个开源数据库,它来自美国国家标准与技术研究所(National Institute of Standards and Technology, NIST)。 其中一共包含了60000条训练集数据和10000条测试集数据。其中训练集由来自 250 个不同人手写的0-9数字构成,其中50%是高中学生,50% 来自人口普查局的工作人员;而测试集的手写数字数据也拥有同样的来源及比例。
2.2 数据集处理
这个数据集显然要比我上一篇博客中提到的kaggle中的数据集更难处理一些。因为数据集的制作者为了方便数据的上传和下载,首先用自己的编码方式将这些图像以字节存储从而变成了4个特殊格式的文件,从而压缩整个数据集的大小。根据MINIST网站的描述,这四个文件分别是:
train-images-idx3-ubyte.gz: 包含60000个训练集图像
train-labels-idx1-ubyte.gz: 包含60000个训练集图像的标记(label)
t10k-images-idx3-ubyte.gz : 包含10000个测试集图像
t10k-labels-idx1-ubyte.gz : 包含60000个训练集图像的标记(label)
这些文件的编码方式在网页上也有详细的介绍,读者只需要根据编码方式反过来操作就可以解码得到图像文件了,至于保存成.png还是.jpg还是其他的什么格式当然任凭读者自己决定了,在MATLAB中也就是一行代码的事儿。
我上传的代码包里有一个名叫“FILE FORMATS FOR THE MNIST DATABASE.txt”的文件,里面就是编解码规则,对上不了外网的读者可能会比较有帮助。
数据集解码的代码MINIST网页上没有提供,不过也不是什么难事。我根据自己的习惯把原始文件解码到了20个.mat数据包内,按照数字和类别命名:前10个是train0.mat-train9.mat,代表数字0-9的训练集;后10个是test0.mat-test9.mat,代表数字0-9的测试集。
最后一步就是将这些.mat数据包中的数据条目一个个转换成图像。每个.mat都是一个 若干行x784 的二维矩阵,其行数代表数据条数,列数的784是28的平方,也就是一张数字手写体图像的像素个数(每张数字手写体是 28x28 的灰度图)。
说道灰度图,那就还有一个问题值得考虑:需不需要转换为二值图呢?请注意二值化本质上是量化阶为2的量化,而灰度图的取值范围是0-255,那也就是量化阶为256的量化。它们的效果谁好谁坏呢,口说无凭,到了后面我们会拿实验结果表态的。
3 代码实现
3.1 文件目录
现在来介绍一下代码的文件目录以及各个文件之间的联系。本实验用到的全部程序如图1所示:
看上去代码文件很多,但是有一些代码是准备材料时所用到的,还有一些是辅助性代码,还有一些是为了对比实验结果而另外写的,所以实际上并没有那么夸张。
详细介绍如下:
第一个文件夹matdata里的内容有MINIST原始的4个字节文件、解码所需的.m源代码、1个说明性的.txt文件以及解码得到的20个.mat数据包。
第二个文件夹models里面的内容是在多种参数下训练得到的模型,一共有16个模型。这个文件夹里的内容是可以删除的,只要每次在训练代码Cpic2mat.m或是Dpic2mat.m中改变参数和产生数据包的文件名就可以在这个文件夹下生成新的模型,注意模型的格式也是.mat数据包。
第三个文件夹othertestpic里面的内容是若干张其他来源的0-9数字手写体图片,用以测试训练产生的额模型的识别效果。
第四个文件夹test-images里面的内容是10000张测试图片。
第五个文件夹test-images-smaller是第四个文件夹的子集。
第六个文件夹train-images里面的内容是60000张训练图片。
第七个文件夹train-images-smaller是第六个文件夹的子集。
文件Cpic2mat.m和Dpic2mat.m是训练代码,区别在于前者的训练图像是0-255灰度图,后者训练的是0-1浮点灰度图。
文件CBayesTesting.m和DBayesTesting.m是验证代码。
文件CBTSinglePic.m和DBTSinglePic.m是针对单个目标图像的测试代码。
文件im_pre_here.m是图像预处理代码,功能是将灰度图/黑白图反色。
文件mat2pic.m是辅助代码,功能是将第一个文件夹的处理结果——数据包——转换成图像。
最后2个.m文件都是辅助性代码,功能分别是计算某个取值在某个正态分布下的概率以及对整数矩阵进行数据统计。
最后的.xls文件是实验记录表单,我会直接在后文截图并附上说明的。
需要说明的是:
由于我已经完成了大部分预处理和准备工作,所以读者只需要先运行Cpic2mat.m或Dpic2mat.m得到训练模型(模型以.mat格式存储在文件夹models中),再运行CBayesTesting.m或DBayesTesting.m即可得到每个数字手写体的识别正确率。另外,读者也可以继续运行CBTSinglePic.m或DBayesTesting.m来对单个图像进行检测,包括现场书写的数字(当然别忘了做适当的预处理)。
3.2 核心代码
核心代码其实很简单,就以C字打头的文件为例进行说明。
数据训练步骤的核心代码如下:
% 对于0-9共10个数字
for A1=1:10
% 每个数字有多少个样本
len = length(img_list{A1,1});
% 确定样本训练(学习)样本数目
for A2=1:min(len,train_num)
img_name = img_list{A1,1}(A2).name;
im = imread([prefix,img_name]);
% figure;imshow(im);
% 例如:拆分成7*7=49个小块(Piece),每个小块有4*4=16个元素
Piece = 1;
for A3=1:lPiece:29-lPiece
for A4=1:lPiece:29-lPiece
temp = im(A3:A3+lPiece-1,A4:A4+lPiece-1);
% 例如:只要16个中有超过3个是白色,就标记为1(255*4=1020)
if sum(sum(temp))>= 255*nthres
Pattern(A1).feature(Piece,A2) = 1;
end
Piece = Piece+1;
end
end
end
fprintf('Calss %1d:%5d images are written to mat.\n',A1-1,train_num);
end
% ---------至此,结构体数组Pattern写入完毕,即数据集模板已建立-------------
数据验证步骤的核心代码如下:
% 对于每一类数字(0-9)
correct_num_all = 0;
for A1=1:10
% 每个数字的每一个测试样本数
len = length(img_list{A1});
% 对0-9每一个数字设置一个正确判断量
correct_num = 0;
% 对于一个数字的每一个测试样本
for A2=1:len
img_name=img_list{A1}(A2).name;
im=imbinarize(im2double(imread([prefix,img_name])));
% figure;imshow(im);
% 对每一个im分割处理
fe = zeros(nPiece^2,1);
piece=1;
for A3=1:lPiece:29-lPiece
for A4=1:lPiece:29-lPiece
temp=im(A3:A3+lPiece-1,A4:A4+lPiece-1);
fe(piece)=sum(sum(temp));
piece = piece+1;
end
end
% 至此,得到了一个测试样本的特征序列fe,接下来识别该样本
% 用 Bayes 分类器的方法
% 计算10个条件概率,即P(X|wi),i=0,1,...,9
% 而 P(X|wi)=∏(k=1,49)P(xk|wi)
% 可以理解为下面的 P(A2|A1)
% 条件概率
cond_prob = 2*ones(10,1);
% 后验概率
post_prob = zeros(10,1);
% 对于10个数字
for A5=1:10
% 对于待确定数字的每一位 1:49
for A6=1:nPiece^2
cond_prob(A5)=cond_prob(A5)*CPattern(A5).feature_prob(A6,fe(A6)+1)*sqrt(2);
end
% 后验概率
post_prob(A5) = cond_prob(A5)*CPattern(A5).prob;
end
% 取概率最大的
[~,I]=max(post_prob);
% 数字 I-1 就是识别结果,需要和真实数字 A1-1 进行对比
if I==A1
correct_num = correct_num+1;
end
end
correct_rate = correct_num/len;
correct_num_all = correct_num_all+correct_num;
fprintf('Judgment rate of Class %1d is %.2f%%\n',A1-1,100*correct_rate);
end
这就得到了每一条待验证的数据被判断为0-9的概率,通过比较这10个概率值的大小即可得出最终判断。
3.3 注意点
读者可能注意到这一段的架构和我上一篇博客的架构几乎一模一样,解说文字也一样,这并不是我偷懒,而是这两个实验的确非常相似。同样地,这里的注意点也包括了上一篇博客中第3.3章节所提到的那三点需要注意的地方,在此我就不再赘述了。
但是,它们两者之间也有几点重要的不同,而正是这些不同使得这个小项目实际上比上一篇博客中的语音性别识别更难了一些。不同点主要有3个,下面进行简要介绍。
第一、语音性别识别是一个二分类问题,而这是一个10分类问题。
第二、语音性别识别需要考虑的特征有20个,也就是说后面需要计算20个概率连乘;而这里需要考虑的特征最多可以达到 28x28 ,即784个,也就是说最多需要计算784个概率连乘。而这就使得必须进行常数补偿,因为MATLAB也无法表示10的负784次方这种变态数字。
第三、语音性别识别的量化阶可以设置为10或20或更高,但是设置更高已经没有意义;而这里图像的量化阶有可能需要设置成256,因为0-255的灰度图我们经常使用到,不能说没有意义。这一点会直接扩大需要查询的概率表,着实让程序员(也就是我了)痛苦了一翻,尤其是在检查bug的时候。当然了,如果是bw二值图就方便多了,此时每一个像素点非0即1,概率表直接降级为一个一维数组。
第四点是一个说明:为什么上面第二点说“最多”784个,也就是还有可能小于784个。对于一个 28x28 的图像,我们既可以逐像素地处理,也可以“逐组”地处理——每多个像素划分成一组就OK了。例如我可以每 2x2 个像素划为一组,这样一张图就有 14x14 个组,这样就只需要计算 14x14=196 个概率连乘了。那么也可以每 4x4 个像素划为一组,计算 7x7=49 个概率连乘……这样做的好处是可以减少特征数,但是坏处有2个:第一,处理的精细程度下降了,这就相当于把 28x28 的图像resize 变小了,最后的识别效果是会下降的;第二,扩大了需要查询的概率表,对于bw二值图像来说,原来一个像素非0即1,而现在一个 NxN 的“组”的像素取值范围变成了 0-(N^2) 。这之间如何取舍,还得靠实验验证,最后权衡之后选一个最合适的值。
4 实验与结果分析
影响实验结果的因素包含但不限于以下因素:
1. 训练集数量;
2. “组”大小的划分,即下表中的“帧尺寸”;
3. 图像格式,是二值图还是灰度图,实质上是量化阶数量的选取;
4. 每“组”内的像素划分,即下表中的“分类法”,相当于是把每“组”作为一个整体视为二值图还是4/16值图等等;
5. 阈值,即若要二值化处理,怎样判定每“组”是黑还是白。
在进行了若干次有效试验之后,得到如图4所示的实验结果:
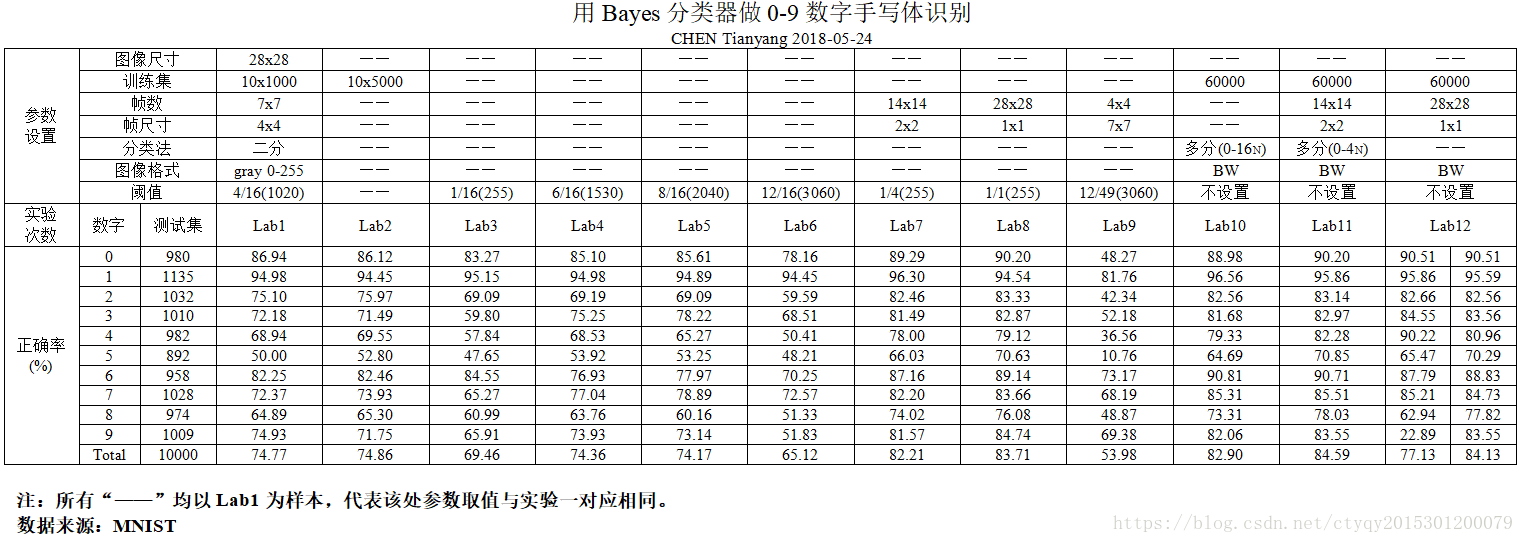
从上图可以得出以下几个结论:
1. 在一定范围内,帧尺寸越小,识别效果越好。当帧尺寸为 1x1 ,即逐像素处理时,识别正确率最高,可以达到84%左右;
2. 在一定范围内,训练集数目越多,识别效果越好。
3. 随着帧尺寸的逐渐减小,识别正确率的提升越来越缓慢。而这也是可以预料的,某单一因素的改善对最终结果的改善总有上限,并且改善效果越来越低;
4. 比较Lab12的两组数据,前者在概率连乘时没有常数补偿,而后者加了乘以sqrt(2)的补偿,最终效果有明显差异,这提醒我们在使用贝叶斯朴素分类器时一定要注意数值计算——尤其是概率连乘——可能带来的问题;
读者可以自行设计更多的实验,可能会发现更多的结果。
5 后记
这是我在18年上半年为《数字图像处理》做的小练习,年代不算久远,而且代码完全是自己写的,所以还记得不少当时的想法。因此,如有读者对代码任何细节有疑问,欢迎随时来与我联系。
代码最终的识别效果84.59%,看上去似乎还不错,但是如果用自己手写的图像一个一个地去测试就会发现,正确率完全达不到这个数据。什么原因呢?我想很可能是因为训练数据太多了,使得训练出来的模型拥有了太多的“个性”,以至于掩盖了我们所希望它所应当具备的“共性”,或者说是“抽象性”。我有一个同学是用CNN来做的MINIST,最后验证集的识别正确率可以达到97%还多,但是最后测试的时候也免不了会遇到这个问题。
由于图像实在太多了(7万张),压缩很耗时,所以图像我就不传了,但是图像解码的代码我会上传的,所谓“授人以鱼不如授人以渔”嘛;另外,models文件夹我也清空了,给读者自己设计实验的空间。
转载时务必注明来源及作者。尊重知识产权从我做起。
代码与其他资料已上传至网络,欢迎下载,密码是hpyx。