前言
什么是AI?
The theory and development of computer systems able to perform tasks normally requiring human intelligence.(–Oxford Dictionary)
Using data to solve problems.(–cy)
步骤
先导包
import tensorflow as tf
#print(tf.__version__)
from tensorflow.keras import layers
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.models import Sequential
import numpy as np
读取数据
data = np.load('mnist.npz') #从本地读取数据集
train_x, train_y, test_x, test_y = data['x_train'], data['y_train'], data['x_test'], data['y_test']
数据探索
print('train_x: ',type(train_x),train_x.shape)
print('train_y: ',type(train_y),train_y.shape)
print('test_x: ',type(test_x),test_x.shape)
print('test_y: ',type(test_y),test_y.shape)
train_x: <class ‘numpy.ndarray’> (60000, 28, 28)
train_y: <class ‘numpy.ndarray’> (60000,)
test_x: <class ‘numpy.ndarray’> (10000, 28, 28)
test_y: <class ‘numpy.ndarray’> (10000,)
import matplotlib.pyplot as plt
print(train_x[0],type(train_x[0]),train_x[0].shape)
plt.imshow(train_x[0])
print('图片对应的target数字:',train_y[0],type(train_y[0]))

import random
# 随机找其中的几副图像 然后显示出来看看
plt.figure(figsize=(15,2.5))
i=1
for e in [random.randint(1,train_x.shape[0]) for i in range(4)]:#在(1,60000)中间随机的找4个数 然后将图像显示出来 对应的数字也显示
ax=plt.subplot(140+i)#子图141 142 143 144
plt.title('index:'+str(e)+' number:'+str(train_y[e]))
plt.imshow(train_x[e])
i+=1
plt.show()

数据处理
#数据升维
train_x_rsp=train_x.reshape(train_x.shape[0],28,28,1)
print(train_x_rsp[0],type(train_x_rsp[0]),train_x_rsp[0].shape)
plt.imshow(train_x_rsp[0])

#数据规范化一下
train_x_rsp255=train_x_rsp/255 #数据规范化一下,这个除以255不影响数据的维度 只是原来的每个数据的值都缩小了 成小数了
print(train_x_rsp255[0],type(train_x_rsp255[0]),train_x_rsp255[0].shape)
plt.imshow(train_x_rsp255[0])

#同理处理一下 测试集的数据
test_x_rsp=test_x.reshape(test_x.shape[0],28,28,1)#数据升维
test_x_rsp255=test_x_rsp/255 #数据规范化一下,这个除以255不影响数据的维度 只是原来的每个数据的值都缩小了 成小数了
#对比一下处理前后的y
print('train_y ','type:',type(train_y),' shape:',train_y.shape)
print('test_y ','type:',type(test_y),' shape:',test_y.shape)
print('train_y[0]',train_y[0])
train_y_ktc = tf.keras.utils.to_categorical(train_y, 10)#同样y的数据也升维,用来分类
test_y_ktc = tf.keras.utils.to_categorical(test_y, 10)
print('train_y_ktc ','type:',type(train_y_ktc),' shape:',train_y_ktc.shape)
print('test_y_ktc ','type:',type(test_y_ktc),' shape:',test_y_ktc.shape)
print('train_y_ktc[0]',train_y_ktc[0])
train_y type: <class ‘numpy.ndarray’> shape: (60000,)
test_y type: <class ‘numpy.ndarray’> shape: (10000,)
train_y[0] 5
train_y_ktc type: <class ‘numpy.ndarray’> shape: (60000, 10)
test_y_ktc type: <class ‘numpy.ndarray’> shape: (10000, 10)
train_y_ktc[0] [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]

搭建网络模型
# 创建序贯模型
model = Sequential()
# 第一层卷积层:6个卷积核,大小为5∗5, relu激活函数
model.add(Conv2D(6, kernel_size=(5, 5), activation='relu', input_shape=(28, 28, 1)))
# 第二层池化层:最大池化
model.add(MaxPooling2D(pool_size=(2, 2)))
# 第三层卷积层:16个卷积核,大小为5*5,relu激活函数
model.add(Conv2D(16, kernel_size=(5, 5), activation='relu'))
# 第二层池化层:最大池化
model.add(MaxPooling2D(pool_size=(2, 2)))
# 将参数进行扁平化,在LeNet5中称之为卷积层,实际上这一层是一维向量,和全连接层一样
model.add(Flatten())
model.add(Dense(120, activation='relu'))
# 全连接层,输出节点个数为84个
model.add(Dense(84, activation='relu'))
# 输出层 用softmax 激活函数计算分类概率
model.add(Dense(10, activation='softmax'))
# 设置损失函数和优化器配置
model.compile(loss=tf.keras.metrics.categorical_crossentropy, optimizer=tf.keras.optimizers.Adam(), metrics=['accuracy'])
上面的模型示意图如下:
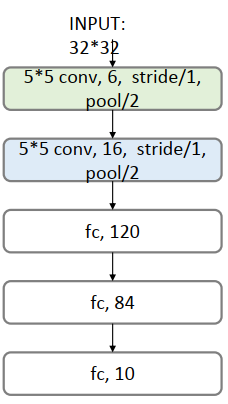
模型训练
# 传入训练数据进行训练
model.fit(train_x_rsp255, train_y_ktc, batch_size=128, epochs=2, verbose=1, validation_data=(test_x_rsp255, test_y_ktc))

模型评估
#模型评估
score = model.evaluate(test_x_rsp255, test_y_ktc)
print('误差:' ,score[0])
print('准确率:', score[1])
误差: 0.059025414288043976
准确率: 0.9821000099182129
总结
一个简单的例子,可以体现深度学习的基本流程(如果您发现我写的有错误,欢迎在评论区批评指正)。