分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
Kaggle入门——使用scikit-learn解决DigitRecognition问题
@author: wepon
@blog: http://blog.csdn.net/u012162613
1、scikit-learn简介
scikit-learn是一个基于NumPy、SciPy、Matplotlib的开源机器学习工具包,采用Python语言编写,主要涵盖分类、
回归和聚类等算法,例如knn、SVM、逻辑回归、朴素贝叶斯、随机森林、k-means等等诸多算法,官网上代码和文档
都非常不错,对于机器学习开发者来说,是一个使用方便而强大的工具,节省不少开发时间。

scikit-learn官网指南:http://scikit-learn.org/stable/user_guide.html
2、使用scikit-learn解决DigitRecognition
(1)处理数据
def loadTrainData(): #这个函数从train.csv文件中获取训练样本:trainData、trainLabeldef loadTestData(): #这个函数从test.csv文件中获取测试样本:testDatadef toInt(array):def nomalizing(array): #这两个函数在loadTrainData()和loadTestData()中被调用 #toInt()将字符串数组转化为整数,nomalizing()归一化整数def loadTestResult(): #这个函数加载测试样本的参考label,是为了后面的比较def saveResult(result,csvName): #这个函数将result保存为csv文件,以csvName命名“处理数据”部分,我们从train.csv、test.csv文件中获取了训练样本的feature、训练样本的label、测试样本的feature,在程序中我们用trainData、trainLabel、testData表示。
(2)调用scikit-learn中的算法
#调用scikit的knn算法包from sklearn.neighbors import KNeighborsClassifier def knnClassify(trainData,trainLabel,testData): knnClf=KNeighborsClassifier()#default:k = 5,defined by yourself:KNeighborsClassifier(n_neighbors=10) knnClf.fit(trainData,ravel(trainLabel)) testLabel=knnClf.predict(testData) saveResult(testLabel,'sklearn_knn_Result.csv') return testLabelkNN算法包可以自己设定参数k,默认k=5,上面的comments有说明。
更加详细的使用,推荐上官网查看:http://scikit-learn.org/stable/modules/neighbors.html
#调用scikit的SVM算法包from sklearn import svm def svcClassify(trainData,trainLabel,testData): svcClf=svm.SVC(C=5.0) #default:C=1.0,kernel = 'rbf'. you can try kernel:‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ svcClf.fit(trainData,ravel(trainLabel)) testLabel=svcClf.predict(testData) saveResult(testLabel,'sklearn_SVC_C=5.0_Result.csv') return testLabelSVC()的参数有很多,核函数默认为'rbf'(径向基函数),C默认为1.0
更加详细的使用,推荐上官网查看:http://scikit-learn.org/stable/modules/svm.html
#调用scikit的朴素贝叶斯算法包,GaussianNB和MultinomialNBfrom sklearn.naive_bayes import GaussianNB #nb for 高斯分布的数据def GaussianNBClassify(trainData,trainLabel,testData): nbClf=GaussianNB() nbClf.fit(trainData,ravel(trainLabel)) testLabel=nbClf.predict(testData) saveResult(testLabel,'sklearn_GaussianNB_Result.csv') return testLabel from sklearn.naive_bayes import MultinomialNB #nb for 多项式分布的数据 def MultinomialNBClassify(trainData,trainLabel,testData): nbClf=MultinomialNB(alpha=0.1) #default alpha=1.0,Setting alpha = 1 is called Laplace smoothing, while alpha < 1 is called Lidstone smoothing. nbClf.fit(trainData,ravel(trainLabel)) testLabel=nbClf.predict(testData) saveResult(testLabel,'sklearn_MultinomialNB_alpha=0.1_Result.csv') return testLabel上面我尝试了两种朴素贝叶斯算法:高斯分布的和多项式分布的。多项式分布的函数有参数alpha可以自设定。
svcClf=svm.SVC(C=5.0)svcClf.fit(trainData,ravel(trainLabel))fit(X,y)说明:
testLabel=svcClf.predict(testData)saveResult(testLabel,'sklearn_SVC_C=5.0_Result.csv')(3)make a submission
上面基本就是整个开发过程了,下面看一下各个算法的效果,在Kaggle上make a submission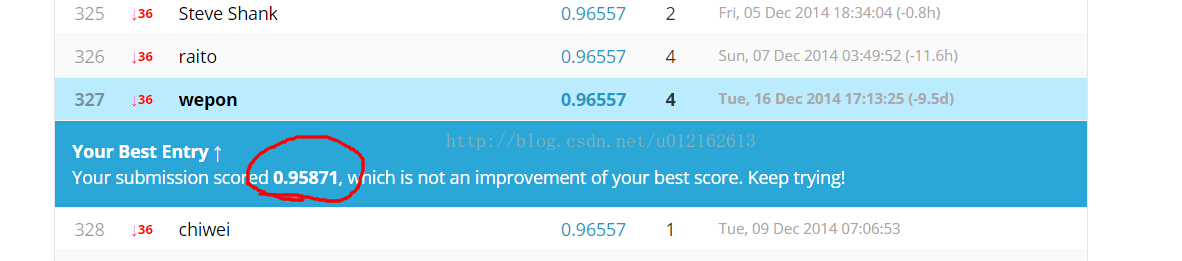


3、工程文件
#!/usr/bin/python# -*- coding: utf-8 -*-"""Created on Tue Dec 16 21:59:00 2014@author: wepon@blog:http://blog.csdn.net/u012162613"""from numpy import *import csvdef toInt(array): array=mat(array) m,n=shape(array) newArray=zeros((m,n)) for i in xrange(m): for j in xrange(n): newArray[i,j]=int(array[i,j]) return newArray def nomalizing(array): m,n=shape(array) for i in xrange(m): for j in xrange(n): if array[i,j]!=0: array[i,j]=1 return array def loadTrainData(): l=[] with open('train.csv') as file: lines=csv.reader(file) for line in lines: l.append(line) #42001*785 l.remove(l[0]) l=array(l) label=l[:,0] data=l[:,1:] return nomalizing(toInt(data)),toInt(label) #label 1*42000 data 42000*784 #return trainData,trainLabel def loadTestData(): l=[] with open('test.csv') as file: lines=csv.reader(file) for line in lines: l.append(line)#28001*784 l.remove(l[0]) data=array(l) return nomalizing(toInt(data)) # data 28000*784 #return testData def loadTestResult(): l=[] with open('knn_benchmark.csv') as file: lines=csv.reader(file) for line in lines: l.append(line)#28001*2 l.remove(l[0]) label=array(l) return toInt(label[:,1]) # label 28000*1 #result是结果列表 #csvName是存放结果的csv文件名def saveResult(result,csvName): with open(csvName,'wb') as myFile: myWriter=csv.writer(myFile) for i in result: tmp=[] tmp.append(i) myWriter.writerow(tmp) #调用scikit的knn算法包from sklearn.neighbors import KNeighborsClassifier def knnClassify(trainData,trainLabel,testData): knnClf=KNeighborsClassifier()#default:k = 5,defined by yourself:KNeighborsClassifier(n_neighbors=10) knnClf.fit(trainData,ravel(trainLabel)) testLabel=knnClf.predict(testData) saveResult(testLabel,'sklearn_knn_Result.csv') return testLabel #调用scikit的SVM算法包from sklearn import svm def svcClassify(trainData,trainLabel,testData): svcClf=svm.SVC(C=5.0) #default:C=1.0,kernel = 'rbf'. you can try kernel:‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ svcClf.fit(trainData,ravel(trainLabel)) testLabel=svcClf.predict(testData) saveResult(testLabel,'sklearn_SVC_C=5.0_Result.csv') return testLabel #调用scikit的朴素贝叶斯算法包,GaussianNB和MultinomialNBfrom sklearn.naive_bayes import GaussianNB #nb for 高斯分布的数据def GaussianNBClassify(trainData,trainLabel,testData): nbClf=GaussianNB() nbClf.fit(trainData,ravel(trainLabel)) testLabel=nbClf.predict(testData) saveResult(testLabel,'sklearn_GaussianNB_Result.csv') return testLabel from sklearn.naive_bayes import MultinomialNB #nb for 多项式分布的数据 def MultinomialNBClassify(trainData,trainLabel,testData): nbClf=MultinomialNB(alpha=0.1) #default alpha=1.0,Setting alpha = 1 is called Laplace smoothing, while alpha < 1 is called Lidstone smoothing. nbClf.fit(trainData,ravel(trainLabel)) testLabel=nbClf.predict(testData) saveResult(testLabel,'sklearn_MultinomialNB_alpha=0.1_Result.csv') return testLabeldef digitRecognition(): trainData,trainLabel=loadTrainData() testData=loadTestData() #使用不同算法 result1=knnClassify(trainData,trainLabel,testData) result2=svcClassify(trainData,trainLabel,testData) result3=GaussianNBClassify(trainData,trainLabel,testData) result4=MultinomialNBClassify(trainData,trainLabel,testData) #将结果与跟给定的knn_benchmark对比,以result1为例 resultGiven=loadTestResult() m,n=shape(testData) different=0 #result1中与benchmark不同的label个数,初始化为0 for i in xrange(m): if result1[i]!=resultGiven[0,i]: different+=1 print different给我老师的人工智能教程打call!http://blog.csdn.net/jiangjunshow

新的改变
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- 全新的界面设计 ,将会带来全新的写作体验;
- 在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
- 增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
- 全新的 KaTeX数学公式 语法;
- 增加了支持甘特图的mermaid语法1 功能;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片: 
带尺寸的图片: ![]()
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block var foo = 'bar'; 生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
创建一个自定义列表
- Markdown
- Text-to- HTML conversion tool
- Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。2
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 是通过欧拉积分
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
gantt
dateFormat YYYY-MM-DD
title Adding GANTT diagram functionality to mermaid
section 现有任务
已完成 :done, des1, 2014-01-06,2014-01-08
进行中 :active, des2, 2014-01-09, 3d
计划一 : des3, after des2, 5d
计划二 : des4, after des3, 5d
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图::
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件或者.html文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
注脚的解释 ↩︎