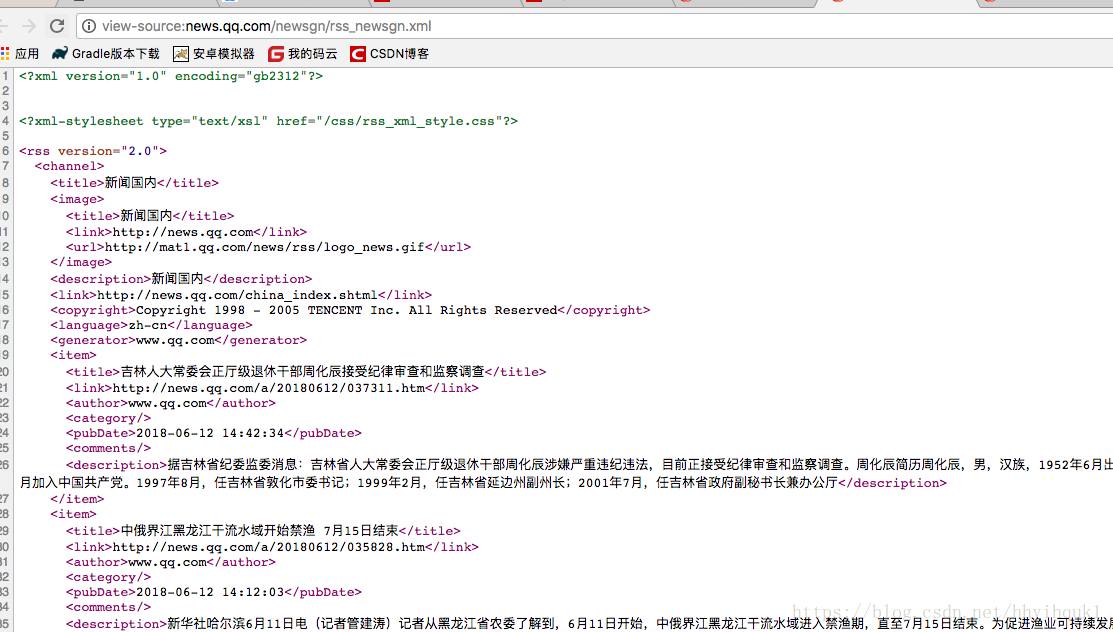
如图为腾讯新闻的xml文件,地址:http://news.qq.com/newsgn/rss_newsgn.xml,源代码如下:
解析方法如下:
while (type!=XmlPullParser.END_DOCUMENT){
switch (type){
case XmlPullParser.START_TAG:
if ("item".equals(parser.getName())){
Log.i("TEST",parser.getName());
newsitem=new News();
}else if ("title".equals(parser.getName())){
Log.i("TEST",parser.getName());
newsitem.setTitle(parser.nextText());
}else if ("description".equals(parser.getName())){
Log.i("TEST",parser.getName());
newsitem.setDescription(parser.nextText());
}
break;
case XmlPullParser.END_TAG:
if ("item".equals(parser.getName())){
news.add(newsitem);
Log.i(TAG,"解析完成");
}
}
type=parser.next();
}
}
return news;
}错误原因:方法的解析顺序为item->title->description,然而在源代码中我们可以看到在第一个item出现的时候就已经出现了title和description了,所以解析会失败。解决办法有两种(针对自己编写的案例):
1、重新部署xml文件,将第一个item前面的标签取消掉
2、按照xml文件的顺序解析