目标网址:腾讯新闻,页面如下

1. 寻找json接口
在目标页面点击鼠标右键进行’检查’,然后选择'Network',再点击’网页刷新’按钮,接着在右下区域内弹出的内容上选择具有pull_url标识的文件,最后点击'Preview'选项即可。图解如下:
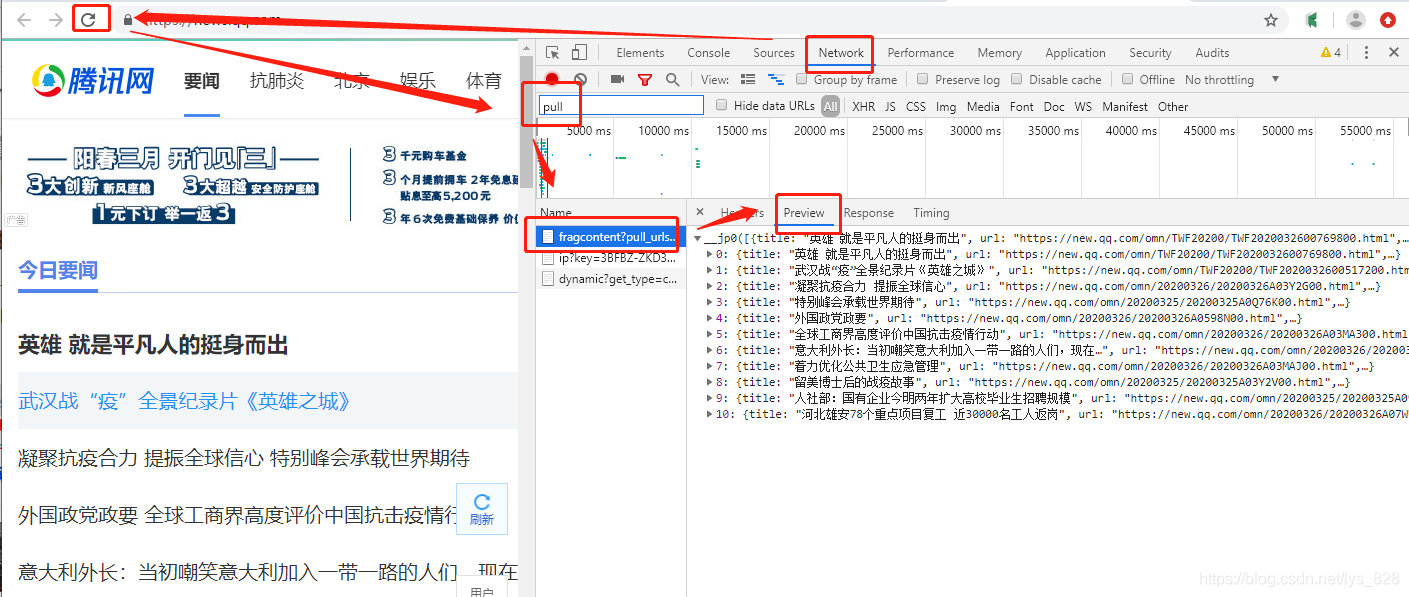
比如就以当前这个页面来看,获取这个json的接口就是点击'Preview'旁边的'Headers',选择’Request URL:'后面的网址,就为请求数据的接口。如下

2. 尝试获取数据
import requests
import json
def get_json():
url = 'https://i.match.qq.com/ninja/fragcontent?pull_urls=news_top_2018&callback=__jp0'
html = requests.get(url)
print(html.text)
get_json()
–> 输出结果为:(可以看到最后输出的结果并不符合json转python数组的格式要求,可以尝试把数据格式转为一致)
__jp0(
[{"title":"\u4e60\u8fd1\u5e73\u56de\u4fe1\u52c9\u52b1\u5317\u5927\u63f4\u9102\u533b\u7597\u961f90\u540e\u515a\u5458","url":"https:\/\/new.qq.com\/omn\/20200316\/20200316A0CI9E00.html","article_id":"20200316a0ci9e00","comment_id":"0","group":"0"},
{"title":"\u4e60\u8fd1\u5e73\u6c42\u662f\u6587\u7ae0\u91cc\u7684\u5173\u952e","url":"https:\/\/new.qq.com\/omn\/TWF20200\/TWF2020031604303300.html","article_id":"twf2020031604303300","comment_id":"0","group":1}
,{"title":"\u82f1\u96c4\uff0c\u5fc5\u987b\u8ba9\u4f60\u4eec\u767b\u201c\u53f0\u201d\u4eae\u76f8\uff01","url":"https:\/\/new.qq.com\/omn\/20200315\/20200315A0GHBK00.html","article_id":"20200315a0ghbk00","comment_id":"0","group":1},
{"title":"\u5b9a\u5411\u964d\u51c6\u7a33\u4fe1\u5fc3 \u5229\u7387\u4e0b\u884c\u6709\u7a7a\u95f4","url":"https:\/\/new.qq.com\/omn\/20200316\/20200316A049RE00.html","article_id":"20200316a049re00","comment_id":"0","group":2},
{"title":"\u75ab\u60c5\u5f71\u54cd\u4e0b\u7684\u4e2d\u56fd\u7ecf\u6d4e\u89c2\u5bdf","url":"https:\/\/new.qq.com\/omn\/20200316\/20200316A04HX200.html","article_id":"20200316a04hx200","comment_id":"0","group":2},
{"title":"\u5927\u533b\u5f20\u4f2f\u793c\u2014\u2014\u4ed6\u662f\u957f\u8005\uff0c\u662f\u7236\u4eb2\uff0c\u66f4\u662f\u5171\u4ea7\u515a\u5458\uff01","url":"https:\/\/new.qq.com\/omn\/20200316\/20200316A0DS7U00.html","article_id":"20200316a0ds7u00","comment_id":"0","group":"0"},
{"title":"\u4ed6\u4eec\u662f\u8bb0\u8005\uff0c\u4ed6\u4eec\u662f\u6218\u58eb","url":"https:\/\/new.qq.com\/omn\/20200316\/20200316A07XO800.html","article_id":"20200316a07xo800","comment_id":"0","group":3},
{"title":"\u6218\u201c\u75ab\u201d\u4e2d\u7684\u9752\u6625\u4e4b\u6b4c","url":"https:\/\/new.qq.com\/omn\/20200316\/20200316A07ZYG00.html","article_id":"20200316a07zyg00","comment_id":"0","group":3},
{"title":"\u3010\u6218\u201c\u75ab\u201d\u8bf4\u7406\u3011\u4ee5\u4eba\u6c11\u4e3a\u4e2d\u5fc3\uff1a\u75ab\u60c5\u9632\u63a7\u7684\u4ef7\u503c\u903b\u8f91","url":"https:\/\/new.qq.com\/rain\/a\/20200316A07IIW00","article_id":"20200316A07IIW00","comment_id":"0","group":"0"},
{"title":"\u575a\u6301\u5411\u79d1\u5b66\u8981\u7b54\u6848\u8981\u65b9\u6cd5","url":"https:\/\/new.qq.com\/omn\/20200315\/20200315A0FJZO00.html","article_id":"20200315a0fjzo00","comment_id":"0","group":4},
])
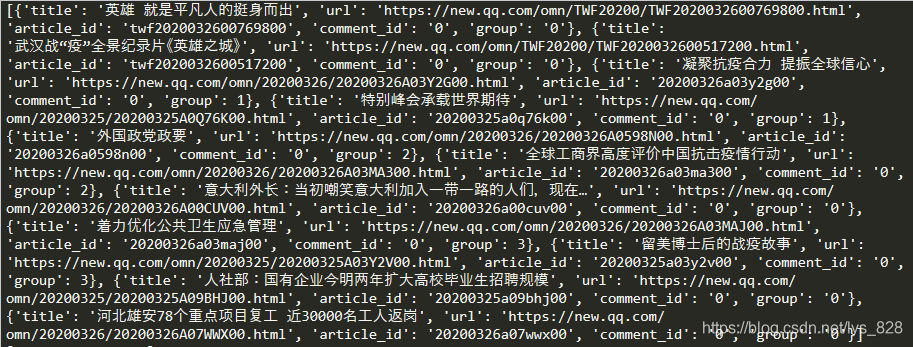
尝试转变数据(去掉列表两侧的多余字符)
print(json.loads((html.text)[6:-2]))
–> 输出结果为:(这里就是进行字符串的切片,将数据转为合适的数据,上下数据一致,均为13条)
3. 获取标题和url
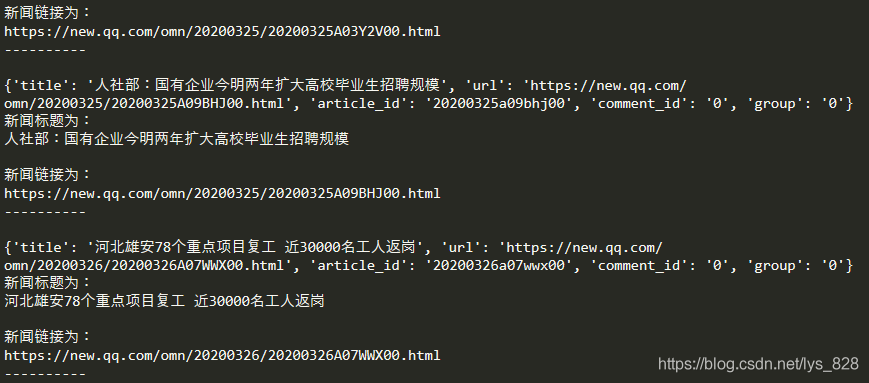
for i in json.loads((html.text)[6:-2]):
# print(i)
print('新闻标题为:\n{}\n'.format(i['title']))
print('新闻链接为:\n{}\n----------\n'.format(i['url']))
–> 输出结果为:(获取的内容和原网页的内容是一致的)
4. 全部代码
import requests
import json
def get_json():
url = 'https://i.match.qq.com/ninja/fragcontent?pull_urls=news_top_2018&callback=__jp0'
html = requests.get(url)
# print(html.text)
# print(json.loads((html.text)[6:-2]))
for i in json.loads((html.text)[6:-2]):
# print(i)
print('新闻标题为:\n{}\n'.format(i['title']))
print('新闻链接为:\n{}\n----------\n'.format(i['url']))
get_json()
