随着Hadoop成为大数据的事实标准,Hadoop的生态也在不断完善,环境搭建的复杂性,给开发和测试带来了不便。如何用Docker来降低Hadoop开发中的复杂性,本文中Crayon带来了他们的方案。
之前,企业软件厂商都会尽可能多的控制客户的随着Hadoop成为大数据的事实标准,Hadoop的生态也在不断完善,环境搭建的复杂性,给开发和测试带来了不便。基础安装环境,因为如果安装环境出错,就可能引起很多不必要的麻烦,甚至大灾难。
最初,公司提供一个包含定制的操作系统镜像的应用,操作系统镜像作为软件安装的其中一份子,它给予了厂商从硬件到操作系统的对环境的完全的控制力。但即便是这样也很难解决问题。企业软件供应商不得不与其它公司形成合作关系,并且依赖这些公司,来为他们分发硬件平台。他们必须寻找多个合作伙伴关系,以避免被锁定在一个合作伙伴。
服务器虚拟化
服务器虚拟化用来解决多供应商的硬件平台和环境问题。它帮助企业软件供应商有效的发布他们的软件,通过在部分虚拟机管理程序之上进行测试和认证。它提供了一个良好的顶层抽象,企业软件应用能够在其中部署和测试。在我早先工作的组织中,我们使用生成的ova镜像,用来在虚拟机管理程序上创建虚拟机实例,对于一个完全封闭的应用,这有助于创建相同结果,更便于管理。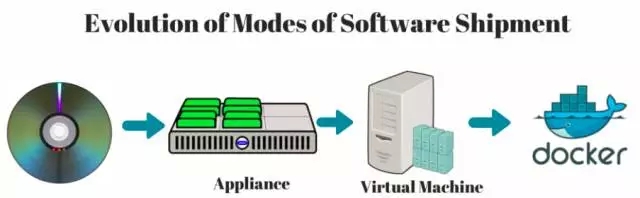
这个模式有几个问题无法解决。首先,构建ova镜像,你需要有大量的系统级的技能。其次是管理分布式环境。当一个软件要求分布式的安装在多节点上,仍然有大量的手工操作包括启动这些虚拟机。随着企业开始使用云作为他们的基础设施,不考虑应用的种类(即使当应用运行在一个节点中),管理一个分布式环境变得更重要。
Docker
Docker 的问世正好解决了这两个问题。Docker允许任何人很简单的快速创建、执行和测试Docker容器。有大量的框架,用于分布式Docker的管理,比如Google 的Kubernetes、CoreOS、Docker编排三剑客等等,这些都很容易和Docker结合。
除了这些,相比于虚拟机,Docker是非常轻量级的。如下图所示,它避免了虚拟机管理程序的附加层,运行一个轻量级的Docker引擎。它支持Windows 和Boot2Docker。
虚拟机和Docker的区别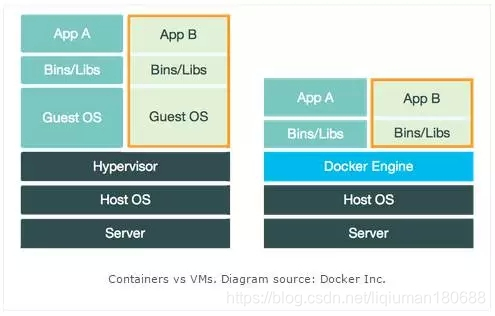
我们如何选择我们的数据处理堆栈
虽然Docker试图解决很多问题,但是我们选择了“构建一致的环境便于去复制”这一方面。
最初在Crayon,在我们的开发周期中,为了测试很少的代码,我们不得不改变我们的MapReduce程序。我们需要将我们的程序放到AWS 环境中的生产集群中,这主要是为了解决配置本地用于测试的Hadoop 环境的时间和精力。当一个POC 仅需要Hadoop生态系统中的一些组件来完成工作时,反复的配置系统是没有效率的,尤其当Hadoop生态系统的组件一直在增加时。
我们使用SequenceIQ提供的工具来开始我们的自动化Hadoop集群之旅,几分钟之内我们就能够启动一个多节点的Hadoop集群。有趣的是,他们采用blueprints 的格式来抽象化集群的配置,通过Docker的帮助来自动化集群的配置和启动。Hortonworks收购SequenceIQ 表明了SequenceIQ所做的自动化Hadoop集群开发这类工作的重要性。
SequenceIQ启发了我们采用Docker。我们通过定制和调整SequenceIQ的Docker镜像取得了一些进展。我们为数据处理构建了一个完全的Docker化平台。
对于我们所有使用Hadoop组件的poc,我们创建了一致的,易于复制的Docker实例,取代了之前人们试着去在本地安装Hadoop生态系统的每个组件,对于开发和测试环境的需要,我们只需要创建一次,便能在任何时间和地点使用它。
这就是我们达到一致的开发,测试,集成和部署的方式之旅,是无缝的。 我们期待让Docker成为我们默认的神器,直到部署阶段。 虽然在企业环境中可能存在一些挑战,我们希望会有一个行业广泛采用Docker。 请继续翻看我们关于我们目前所作的尝试和成就的详细内容。