在本地测试hadoop成功后,我们在多台主机上搭建hadoop集群,用于处理大规模数据…
一、准备工作
1.1 系统环境
三台 Ubuntu 16.04 64位笔记本(一台作为Master节点,另外两台作为Slave节点)
1.2 创建用户
创建用户,并为其添加root权限:
sudo adduser hadoop
sudo vim /etc/sudoers
# 修改内容如下:
root ALL=(ALL:ALL) ALL
hadoop ALL=(ALL:ALL) ALL
给hadoop用户创建目录,并添加到sudo用户组中:
sudo chown hadoop /home/hadoop
# 添加到sudo用户组
sudo adduser hadoop sudo
最后注销当前用户,使用新创建的hadoop用户登陆。
1.3 设置Master与Slave的SSH无密登陆
1.3.1 准备工作
首先要确保你的linux系统中已经安装了ssh,对于ubuntu系统一般默认只安装了ssh client,所以还需要我们手动安装ssh server:
sudo apt-get install openssh-server
1.3.2 SSH基本原理
SSH采用公钥加密来保证安全。过程如下:
1.远程主机收到用户的登录请求,把自己的公钥发给用户;
2.用户使用这个公钥,将登录密码加密后,发送回来;
3.远程主机用自己的私钥,解密登录密码,如果密码正确,就同意用户登录。
1.3.3 基本用法
SSH默认端口号为:22,可以根据自己的需要修改默认端口号。SSH远程登陆:
# 使用默认的22端口
ssh 192.168.0.1
# 若修改过SSH默认端口号(例如:修改为了10000),则登陆时需要指定端口号10000
ssh 192.168.0.1 -p 10000
1.3.4 配置SSH无密登陆
Hadoop运行过程中需要管理远端Hadoop守护进程,在Hadoop启动以后,NameNode是通过SSH(Secure Shell)来启动和停止各个DataNode上的各种守护进程的。这就必须在节点之间执行指令的时候是不需要输入密码的形式,故我们需要配置SSH运用无密码公钥认证的形式,这样NameNode使用SSH无密码登录并启动DataName进程,同样原理,DataNode上也能使用SSH无密码登录到 NameNode。
- 首先,运行
ssh localhost来产生/home/用户名/.ssh目录,然后将生成的 “ id_rsa.pub ” 追加到授权的key里面去。这样的效果是实现了当前用户无密SSH登陆到自己:
cd ~/.ssh # 如果找不到这个文件夹,先执行一下 "ssh localhost"
ssh-keygen -t rsa
# 将id_rsa.pub追加到authorized_keys(切记是追加,不是覆盖)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- 如果要实现无密登陆到其它的主机,只需将生成的 “ id_rsa.pub " 追加到其它主机的 ” ~/.ssh/authorized_keys “ 中去。这里我们使用的方法是先将本机的 ” ~/.ssh/id_rsa.pub “ 拷贝到你想无密登陆的主机上,再在相应的主机上将” ~/.ssh/id_rsa.pub “ 追加到该主机的 ” ~/.ssh/authorized_keys “ 中。
# 假设我们的主机名为:A,用户名:hadoop,ip:192.168.0.1
# 想要无密SSH登陆的主机名为:B, 用户名:hadoop,ip:192.168.0.2
# 首先,我们使用A中的hadoop用户拷贝 " ~/.ssh/id_rsa.pub " 到B的 " /home/hadoop/ " 目录下
scp ~/.ssh/id_rsa.pub [email protected]:/home/hadoop/
# 这里的ip也可以换为主机名
# 然后,ssh登陆B,将 " /home/hadoop/id_rsa.pub " 追加到 " ~/.ssh/authorized_keys " 中去。
cat /home/hadoop/id_rsa.pub >> ~/.ssh/authorized_keys
现在,我们就可以在A中使用SSH无密登陆到B的hadoop用户了,同理如果想无密登陆其它的主机都可以使用此方法。需要注意的是配置hadoop集群时需要Master和Slave可以互相SSH无密登陆。
二、网络配置
这里使用了三台主机搭建集群,选定master后,在该主机的/etc/hostname中,修改机器名为master,将其他主机命名为slave1、slave2等。
接着将"主机名与IP地址对应信息"写入/etc/hosts文件中:
127.0.0.1 localhost
# 填入以下信息:
192.168.199.133 master
192.168.199.204 slave1
192.168.199.194 slave2
注:各台主机(包括Master和Slave)都要进行相应的配置。
配置好之后,在各个主机上执行ping master和ping slave1测试,验证是否相互ping得通。
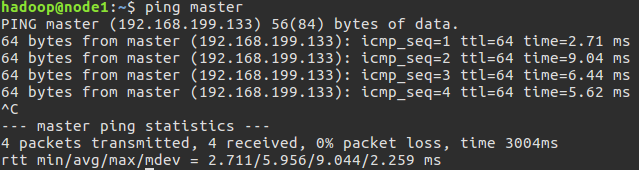 (说明:这里将slave主机命名为node1、node2,只要前后对应即可。)
(说明:这里将slave主机命名为node1、node2,只要前后对应即可。)
三、安装Hadoop
下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/
- 选择下载 hadoop-2.8.0.tar.gz
- 将下载的压缩文件解压至/home/hadoop/目录
四、配置集群/分布式环境
集群/分布式模式需要修改/home/hadoop/hadoop-2.8.0/etc/hadoop/下的5个配置文件。
slaves
将原有的localhost删掉,写入所有slave的主机名,每行一个。例如:
slave1
slave2
core-site.xml
修改如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
mapred-site.xml
这个文件不存在,首先需要从模板中复制一份
cp mapred-site.xml.template mapred-site.xml
然后配置如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置完成后,将master上的hadoop文件复制到其他节点上
# 先压缩
sudo tar -zcf ~/hadoop-2.8.0.tar.gz ~/hadoop-2.8.0
# 再复制
scp ~/hadoop-2.8.0.tar.gz hadoop@slave1:/home/hadoop
# slave端解压
sudo tar -zxf ~/hadoop-2.8.0.tar.gz ~/
# 修改hadoop-2.8.0及其子目录下所有文件的权限
sudo chown -R hadoop:hadoop ~/hadoop-2.8.0
五、启动集群
5.1 删除临时文件
如果之前跑过伪分布模式,在切换到集群模式之前应该先删除临时文件(不然会产生冲突):
rm -rf ~/hadoop/tmp
5.2 启动
在master主机上:
cd ~/hadoop-2.8.0/
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
有时会发现slave节点的DataNode启动失败,则可以按如下顺序执行命令:
(原因:namenode启动有一定时间延迟)
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
sbin/start-yarn.sh
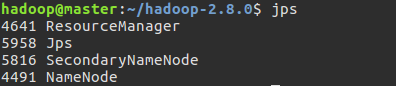
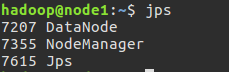
5.3 查看各个节点启动的进程
-
通过jps命令可以查看各个节点启动的进程
master节点:
slave1节点:
-
在master节点通过命令
bin/hdfs dfsadmin -report可以查看DataNode是否正常启动。
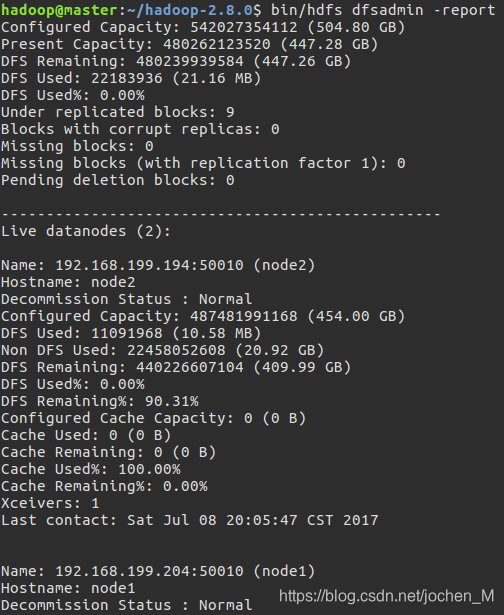
-
也可以通过Web页面查看集群的信息 http://master:50070/

5.4 关闭集群
在master节点执行:
sbin/stop-dfs.sh
sbin/stop-yarn.sh
# 或者
sbin/stop-all.sh
六、示例:运行 WordCount
6.1 上传文件到 HDFS
在本地新建一个文件 words.txt,写入将要分析的内容,如:
When You Are Old
When you are old and grey and full of sleep
And nodding by the fire take down this book
And slowly read and dream of the soft look
Your eyes had once and of their shadows deep
How many loved your moments of glad grace
And loved your beauty with love false or true
But one man loved the pilgrim soul in you
And loved the sorrows of your changing face
And bending down beside the glowing bars
Murmur a little sadly how Love fled
And paced upon the mountains overhead
And hid his face amid a crowd of stars
然后在分布式文件系统中新建一个文件夹/wordcount/input/,用于上传测试文件words.txt:
# 在 hdfs 新建文件夹
bin/hdfs dfs -mkdir /wordcount
bin/hdfs dfs -mkdir /wordcount/input
# 上传文件
bin/hdfs dfs -put words.txt /wordcount/input/
# 查看
bin/hdfs dfs -ls /wordcount/input
6.2 编写 WordCount 程序
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyWordCount {
public static class MyTokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/**
* 将句子分解成单词,并将<word, 1>写入context
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException{
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class MyIntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
/**
* 累计求和,结果写入context
* @param key
* @param values 一个 key 对应一组 value
* @param context
* @throws IOException
* @throws InterruptedException
*/
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException{
int sum = 0;
for(IntWritable val : values){
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration(); // 加载配置信息
Job job = Job.getInstance(conf, "my word count"); // 新建job
job.setJarByClass(MyWordCount.class); // 设置Jar
job.setMapperClass(MyTokenizerMapper.class); // 设置Mapper
job.setCombinerClass(MyIntSumReducer.class); // 设置Combiner
job.setReducerClass(MyIntSumReducer.class); // 设置Reducer
job.setOutputKeyClass(Text.class); // 设置输出的key
job.setOutputValueClass(IntWritable.class); // 设置输出的value
FileInputFormat.addInputPath(job, new Path(args[0])); // 设置输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); // 设置输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1); // 执行job
}
}
6.3 打包并提交任务
# 环境变量配置:(/etc/profile 或 ~/.bashrc)
export JAVA_HOME=/usr/java/default
export PATH=${JAVA_HOME}/bin:${PATH}
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar
# 编译并打包成jar:
bin/hadoop com.sun.tools.javac.Main WordCount.java
jar cf wc.jar WordCount*.class
# 提交任务(在hadoop根目录下执行)
bin/hadoop jar wc.jar WordCount /wordcount/input /wordcount/output
# 查看运行结果:
bin/hadoop fs -cat /wordcount/output/part-r-00000
推荐:
Apache Hadoop: http://hadoop.apache.org/
Hadoop Commands Guide: http://hadoop.apache.org/docs/r2.8.0/hadoop-project-dist/hadoop-common/CommandsManual.html
Apache Hadoop Main 3.0.0-alpha3 API: http://hadoop.apache.org/docs/current/api/