在接触python后想对图片进行一些处理 python实现的代码很简单 但是关键在于一些包的导入
我使用的python 软件是 pycharm 可以在setting中去下载requests这个包
在安装包PIL 和pytesseract这两个包的时候 出现了许多状况 直接影响了我的学习进度
首先 pycharm 在setting中无法直接安装PIL这个包 但是能可以下载pillow这个包 可以说pillow是PIL的升级版吧
然后就是下载pytesseract 这个包了 我们可以选择使用pip 命令行进行下载 : pip install pytesseract
之后就是阻碍我进度的来了
我们下载了PIL 和pytesseract 这两个包后是无法运行程序的 或者说 他依然还会报错 是因为 我们还得下载Tesseract-ocr 这个识别引擎 网上都有安装包 在这里就不详细描述了 下载安装后 因为我们进行的是中文文字的识别 所以还得有一个中文语言包(或着 可以在安装tesseract-ocr时 直接选择下载所有的语言包 等待时间较长):chi_sim.traineddata

然后这样子运行还是会报错 首先你的配置ocr的环境 (最好放在最上面,我的老师告诉我这个还有优先级问题)
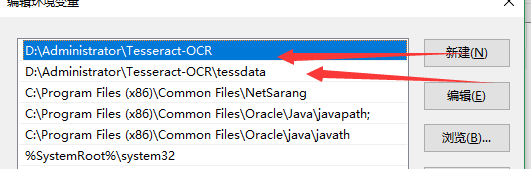
然后在path中新建一个
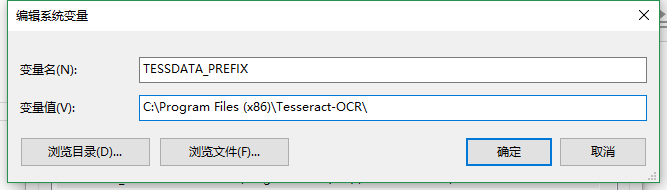
然后进入pytesseract.py文件中进行修改tesseract_cmd
将等号后面的地址 换成在你电脑上的位置 前面加上r 是为了防止转义

# 导入包
import requests
from PIL import Image
import pytesseract
# 模仿浏览器 进行访问
headers = {"User-Agent": " Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"}
# 获取网址 ( 该网址是我所读学校的官网上图片 所以我进行了处理 删掉了一点内容)
url = " http:/*******edu.cn/_upload/article/images/13/d0/55f5bd084947b5f0bd5870f507fd/739926cd-a4ec-4ad9-bec0-d044e3db47c4.jpg"
# 获取图片 对图片进行处理
res =requests.get(url = url , headers =headers)
f = open ("c.jpg", "wb")
f.write(res.content)
f.close()
# 图片文字识别
text = pytesseract.image_to_string(Image.open("c.jpg"),lang = "chi_sim")
print(text)
最后我终于成功地运行出来了 哈哈哈
