1.安装Python依赖库:pytesseract 和 PIL
# 安装pytesseract
pip install pytesseract
# 安装PIL
pip install PIL
#此处如果电脑是window64位系统不能直接使用pip安装,解决方法:
1.先下载:https://www.lfd.uci.edu/~gohlke/pythonlibs/ 根据Python版本下载对应的版本,我的是python3.5所以下载:
Pillow-5.0.0-cp35-cp35m-win_amd64.whl
2.安装wheel依赖,因为安装Pillow-5.0.0-cp35-cp35m-win_amd64.whl需要wheel依赖
pip install wheel
3.切换到Pillow-5.0.0-cp35-cp35m-win_amd64.whl的下载目录,执行安装名称
pip intall Pillow-5.0.0-cp35-cp35m-win_amd64.whl
到此PIL安装完毕
# 安装识别引擎tesseract-ocr
1.下载安装包tesseract-ocr安装包和中文语言包
下载好后直接点击.exe文件安装即可,默认不支持中文,如果想要支持英文需要把中文包复制到tesseract-ocr/tessdata的目录下
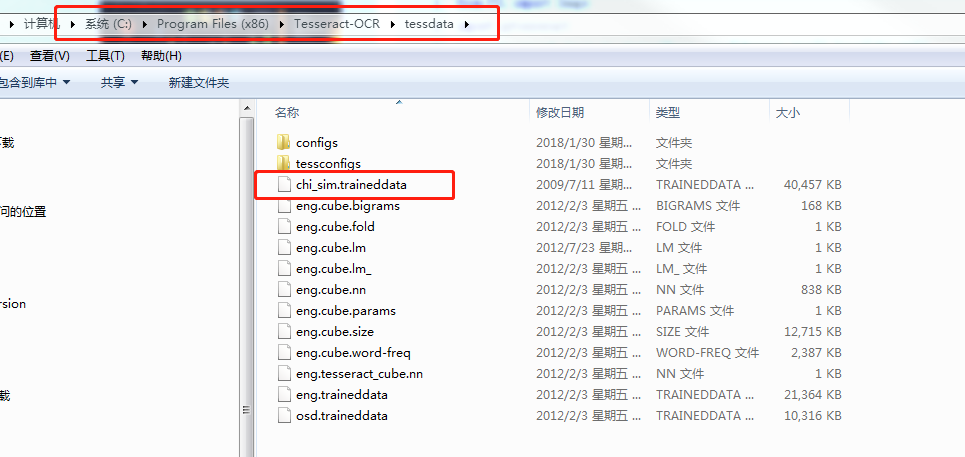
到此就可以使用图片识别文字了,但是只是支持英文
测试图片(test2.png):
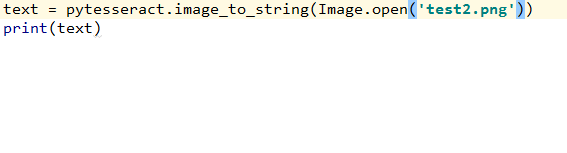
from PIL import Image
import pytesseract
#测试的图片资源
text = pytesseract.image_to_string(Image.open('test2.png'))
print(text)
结果:
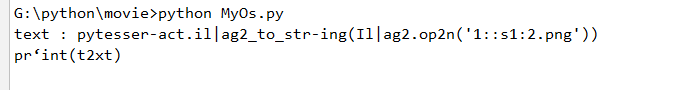
如果需要识别中文需要配置库路径
打开python安装目录,找到并编辑D:\python\Lib\site-packages\pytesseract\pytesseract.py
#tesseract_cmd = 'tesseract'
tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
保存后就可以支持中文识别了
测试图片:
![]()
结果:

可以看出其实中文识别性还是儿童级别的!