本篇文章主要参考了 python图像处理之识别图像中的文字 这篇文章,在实现的过程中出现了些偏差,特此记录。因为此时笔者不是第一次安装,所展示的结果会和首次安装的结果有所差别。
1.安装PIL
以管理员的身份打开命令提示符,输入:pip install pillow.
(注:PIL是python平台事实上的图像处理标准库,但PIL仅支持到python2.7,加上年久失修,于是在PIL的基础上创建了兼容的版本pillow,支持最新的python3.X。)
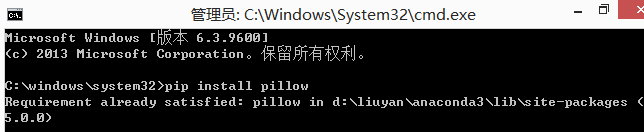
2.安装pytesser3
打开命令提示符,输入:pip install pytesser3
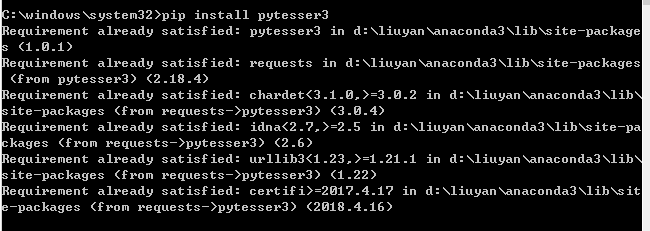
3.安装pytesseract
打开命令提示符,输入:pip install pytesseract

4.安装autopy3
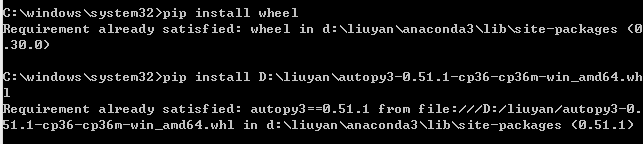
先安装wheel,即先在命令提示符中输入pip install wheel。
下载autopy3-0.51.1-cp36-cp36m-win_amd64.whl。点击此处下载,此时该文件所在目录为D:\liuyan\autopy3-0.51.1-cp36-cp36m-win_amd64.whl。
在命令提示符中输入: pip install D:\liuyan\autopy3-0.51.1-cp36-cp36m-win_amd64.whl
5.安装Tesseract-OCR
5.1 下载安装包
百度搜索Tesseract-OCR下载 Tesseract-orc-setup-3.02.02.exe 。要记得自己的安装目录(博主的安装路径为:C:\Program Files(x86)\Tesseract-OCR),等会配置环境变量要用。
如果不是做英文的图文识别,还需要下载其他语言的识别包 其他语言各版本的识别包下载 ,如简体字识别包对应的是chi_sim.traineddata ,繁体字识别包对应的是chi_tra.traineddata 。
5.2 安装
具体安装步骤可参考光学字符识别引擎Tesseract-ocr安装过程 。
5.3 配置环境变量
博主的安装路径为:C:\Program Files(x86)\Tesseract-OCR。电脑属性--高级系统设置--环境变量,进入如下界面。
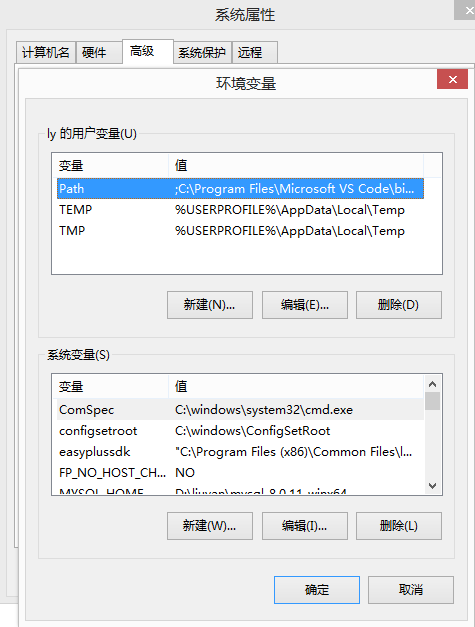
把刚刚的安装路径"C:\Program Files(x86)\Tesseract-OCR"添加到用户变量和系统变量的path中,注意,添加的时候开头用";"跟之前的变量隔开,以";"结尾。配置好后点击确定。
打开命令终端,输入:tesseract -v,可以看到版本信息。

到这里,我们就算安装完成了。但是,我们的系统还是无法识别中文的,要去下载简体汉字、繁体汉字语言包(其他语言各版本识别包下载),下载好之后放到安装目录的tessdata目录下即可。
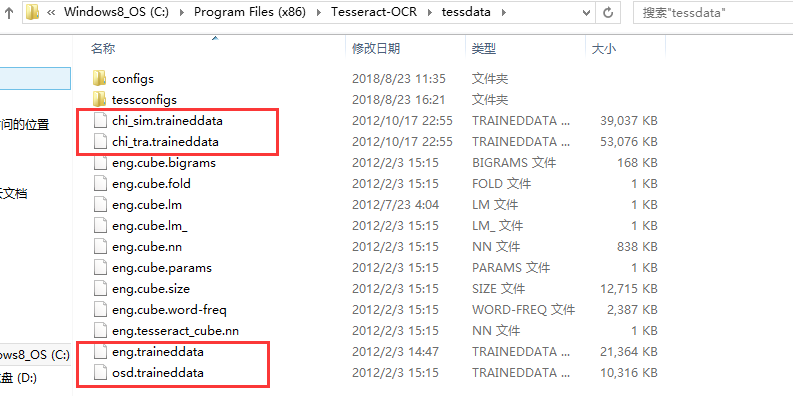
注:此处的安装过程参考Window环境安装tesseract-ocr 4.00并配置环境变量 。
5.4 验证是否安装成功
进入cmd窗口,敲入命令cd C:\Program Files (x86)\Tesseract-OCR,再输入tesseract,若有如下信息则表示安装成功。
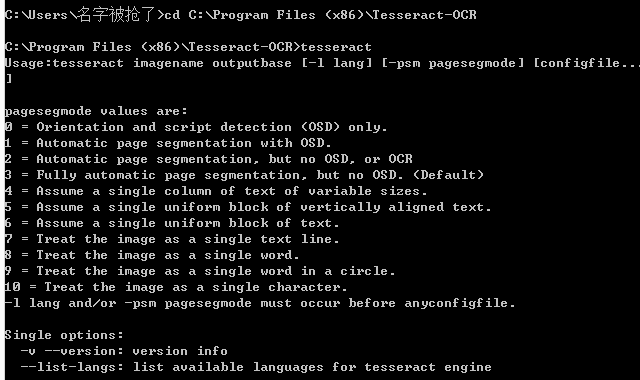
还可以用命令tesseract --list-langs来查看Tesseract-OCR支持的语言。
入门使用
window中运行tesseract(参考 OCR开源软件Tesseract的下载和入门使用)
1.tesseract是一个命令行OCR程序,打开一个终端(Win+R),输入语法如下:
tesseract 输入图片的文件名 输出文件的文件名 [-l lang][-psm pagesegmode][configfile...]例如:识别 微信图片5.png 图像,将识别结果存入 out2.txt,如下

2.用pycharm进行图像中的汉字识别
要识别的原图如下:(来自小华的《烟火里的尘埃》)

实现的代码如下:
import pytesseract
from PIL import Image
im=Image.open(r'C:\Users\名字被抢了\desktop\图片2.png')
print(pytesseract.image_to_string(im,lang='chi_sim'))效果图
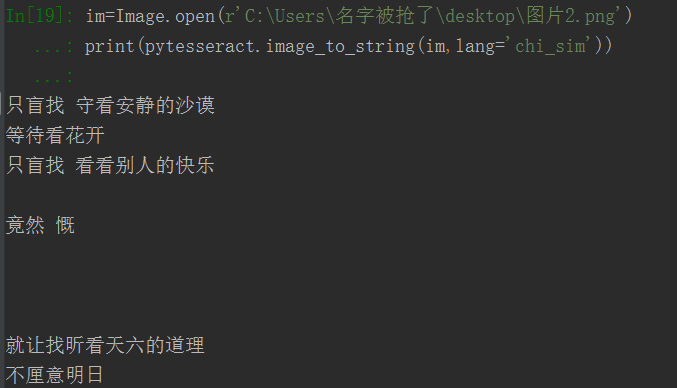
识别的效果不是很好,有待于进一步提高正确率。