全球人工智能
文章来源:GitHub 作者:Heumi 翻译:马卓奇
文章投稿:[email protected]
相关文章:
导读:本文是基于谷歌大脑(Google Brain)发表在 arXiv 的最新论文《BEGAN:边界平衡生成对抗网络》实现的。该工作针对GAN 面临的一些难题,例如如何衡量收敛,如何控制分布多样性以及如何维持鉴别器和生成器之间的平衡等问题,提出了改善。作者使用了很简单的网络结构以及标准的训练过程,在人脸生成任务中取得了优异的视觉效果,达到了目前最先进水平。
论文摘要
作者提出了一种新的能够促成平衡(Equilibrium)的方法,以及配套的损失函数,这个损失的设计由Wasserstein 距离(Wasserstein distance)衍生而来,Wasserstein 距离是用于训练基于自编码器的生成对抗网络(auto-encoder based Generative Adversarial Networks)的。该方法在训练阶段能够维持生成器和鉴别器之间的平衡。除此之外,该方法还提供了一种新的近似收敛策略,实现了快速稳定的训练,并且达到了很高的视觉质量。作者还推导出一种能够控制图像多样性和视觉质量之间的权衡的方法。该工作中,作者主要关注图像生成任务,即使是在更高分辨率的情况下,也建立了视觉质量的新里程碑。并且仅是使用一个相对简单的模型结构和标准的训练流程就实现了这些。
论文有以下四个创新点:
-
一个简单且鲁棒的 GAN 结构,使用标准的训练步骤实现了快速且稳定的收敛
-
一个平衡的概念,用于平衡判别器和生成器的竞争力
-
一种控制图像多样性和视觉质量之间的权衡的新方法
-
一种近似衡量收敛的方法。目前已发表的这类方法的工作只有一个,就是 Wasserstein GAN(WGAN)
网络设计方法
鉴别器:
在鉴别器的设计上,作者使用自编码器作为生成对抗网络的鉴别器,这一思想最早在EBGAN(Energy-based generative adversarialnetwork)中提出。
生成器:
在生成器的设计上,BEGAN 则借鉴了 Wasserstein GAN 定义损失(loss)的思路。传统的GAN会尝试直接匹配数据分布,作者提出的方法是使用从Wasserstein距离衍生而来的损失去匹配自编码器的损失分布。这是通过传统的GAN目标加上一个用来平衡鉴别器和生成器的平衡项实现的。
平衡:
在深度神经网络中,生成器的函数G和鉴别器的函数D的表示能力是一个必须要考虑的因素。它们由模型实现函数的方法以及参数的数量共同决定。传统情况下,G和D往往不能达到平衡,判别器D往往在训练早期就能竞争过生成器G。为了解决这一问题,作者引入了平衡的概念。
作者提出了一个衡量生成样本多样性的超参数 γ : 生成样本损失的期望与真实样本损失的期望值之比。在作者的模型中,判别器有两个目标:对真实图像自编码,并且将生成图像与真实图像区分开。这个超参数能够平衡这两个目标。γ 值比较低会导致图像多样性较差,因为判别器太过于关注对真实图像自编码。
EBGAN网络结构:
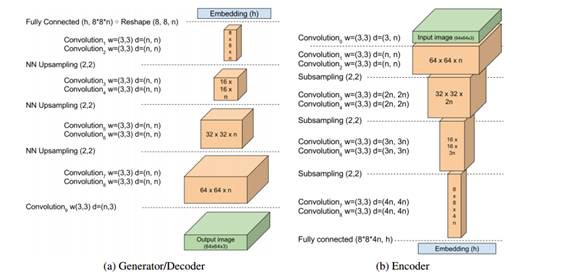
作者使用带有指数线性单元(ELUs)的3x3卷积。每一层都重复2次。每次下采样卷积滤波都线性增加。下采样操作通过子采样完成,采样步长为2,上采样通过最近邻方法实现。在编码器和解码器的边界处,处理过的数据块通过全卷积层,不需要任何非线性操作映射到嵌入态。
作者表示他们的方法训练过程更简单,并且与传统的GAN相比,网络结构也更简单:不需要批归一化(batch normalization),丢弃操作(dropout),反卷积(transpose convolutions),或者卷积滤波的指数增长(exponential growth for convolution filters)。
实验结果
实验数据:来自celeA数据库的360000张名人人脸图像,保证了图像多样性与质量。
基于能量的生成对抗网络(EBGAN)与作者提出的方法结果对比:

超参数 γ 值分别为0.7,0.5和0.3时的生成结果对比,随着 γ 值增加,多样性也有了增加,但是人工效果也更明显:

空间连续性:
不同生成模型的图像在隐空间的插值结果:

图像质量与收敛性关系图:
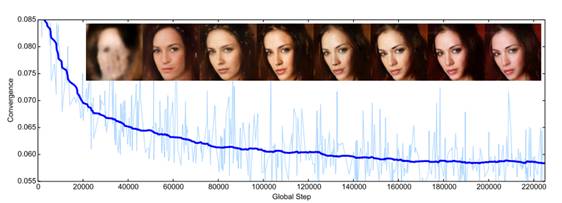
收敛性度量和图像质量评价:从图中可以看出模型收敛很快,我们提出的衡量BEGAN收敛的方法与图像保真度之间有很好的联系。
总结
作者提出了一个新的平衡方法用来平衡对抗网络。使用该方法,网络可以收敛得到多样化且视觉效果喜人的图像。即使在更高的分辨率上进行细小的修改也能保持这一效果。训练过程稳定,快速,并且对参数变化鲁棒,并且不需要进行复杂的迭代训练。
代码实现——BEGAN的Tensorflow实现实现细节:
训练的模型是基于64x64的图像的。128x128的之后会更新。与原文不同的是训练损失更新方法,以及学习速率衰减。首先,论文的损失更新方法是Loss_G以及Loss_D同时进行更迭。但是当我尝试这种方法时,模型会崩溃。所以,这个代码使用了一种替代方法。第二,每2000次迭代,学习速率衰减为0.95。这个参数只是训练经验值,你可以改动或查看论文的设置。
训练过程:
如果想看训练过程,请下载“dropbox”文件夹,并且运行tensorboard--logdir='./',我上传了两个训练好了的模型(64x64 和 128x128)
Kt图。当你训练模型时,可以参考这个结果。达不到1.0.在我的设置下,可以收敛到0.08:
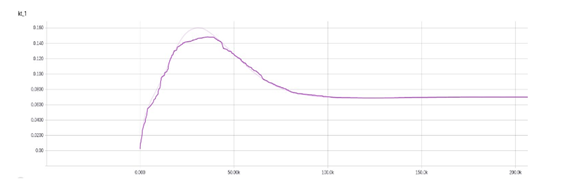
收敛度量(M_global),与论文的图相同:

生成器的输出和解码器输出对比:

使用方法:推荐你下载这个“dropbox”文件夹(https://www.dropbox.com/sh/g72k2crptow3ime/AAAhkGlHCw9zQh0aE-Ggdt3Qa?dl=0)
制作训练数据:
1、下载celeA 数据集(img_align_celeba.zip)(http://pan.baidu.com/s/1eSNpdRG#list/path=%2FCelebA%2FImg)并且解压到 'Data/celeba/raw'
2、运行 ' python ./Data/celeba/face_detect.py '
训练(参考main.py中的began_cmd):

测试(参考main.py中的began_cmd):

环境需求:
-
TensorFlow 1.0.0
-
Python 2.7.12, Opencv, scipy0.18.1, numpy 1.11.2
代码实现结果:
1、这是我训练的模型的随机选取的结果。gamma从0.3到0.5。没有进行择优。Gamma为0.3时,结果很好但是比较偏向女性的脸。gamma为0.4时,效果最佳。gamma为0.5时,纹理很好但是会出现空洞的问题。

2、128x128图像和64x64图像。128x128图像十分震撼。中间四张图像看起来像女性的真实的面孔。

3、从初始图到200000次迭代的结果。

论文地址:https://arxiv.org/pdf/1703.10717.pdf
GitHub资源:https://github.com/Heumi/BEGAN-tensorflow