背景:
presto计算落地出现了大量的小文件,目前暂时没有发现可以通过参数优化解决,所以开发了小文件合并工具
工具架构如下
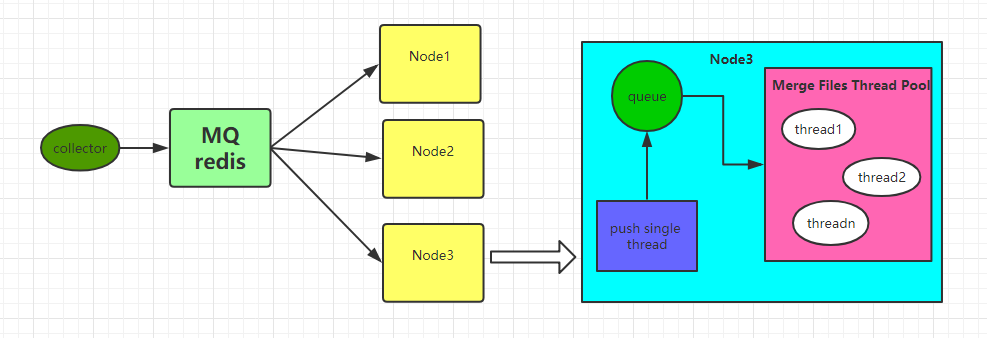
工具主要分为三部分:
collector
负责将合并规则推送到redis队列,合并规则对象定义如下,
public class FileCombineRuleDto {
private int fileSize;//默认单位mb
private String fileDir;//文件路径
private String type;//文件类型:parquet,orc
private int startTime;//开始时间20180101
private int endTime;//结束时间15
}
目前工具支持orc和parquet两种格式文件合并,这也是目前使用最广泛的数据格式,同时支持定义文件大小,这里需要注意的是,如果最后一个文件大小小于fileSize/2,那么这部分数据会合并到上一个文件中,这样做的目的是为了避免再次生成小文件;这样做的效果就是会出现合并的文件大于fileSize的情况[最后一个文件]
同时也支持合并指定时间区间的数据,startTime开始时间,数据格式:20180101,endTime:15[假定今天为20181029],那么数据的合并区间为:20180101 - 20181014
collector对应实现的入口为FileDirCollector.java,这部分用户可以自定义实现,因为功能比较简单,就是将FileCombineRuleDto转换成json字符串扔到redis队列中
消息队列
这里使用的是redis,起初本想将这部分集成到mysql中去,毕竟任务是有状态的[原谅笔者太懒,一切从简]
worker
这个是工具的核心,也就是上图中的Node1,Node2,Node3;有多少个Node取决于你在多少个节点上启动JVM进程,程序入口为
com.fan.merge.AppMain
这些Node同时消费Reids队列中的消息,根据消息规则执行合并文件;这里需要注意的是合并的文件会写在数据的原始目录,也就是小文件所在的目录;文件合并之前会将数据备份一份到指定目录/user/combine;文件合并完后,会将原始目录中的小文件删除;
问题:
1.如果其他用户在目录合并期间读取此数据,可能会出现数据多读的情况
2.目前没有对数据备份目录进行操作,比如备份多久的数据,毕竟合并数据不可能做到百分百执行成功,所以想做备份一份还是比较重要的,删除策略这个笔者还没时间去实现
- 配置文件如下
vi config.properties
redis.host=192.168.120.4
redis.port=6379
#filesize=128m
#文件最后修改时间在20180101之后的会进行合并
start.time=20180101
#距离当前时间多久之前的数据(例如今天是20181015,结合start.time,10代表: 20180101~20181005之间的数据)
end.time=10
#存储用户传递目录参数的Key
file.dir.key=FILEDIRKEY
#队列名
quene.name=FILECOMBINEQUENE
#并行度
default.parallelism=3
#任务队列大小
task.quene.size=10
tmp.dir=/user/combine
#队列阻塞系数[取值0.0~1.0],默认为0.8,线程池线程数poolsize = cpu cores/(1-0.8)
blockage.coefficient = 0.5
再来看下每个Node具体组件
每个Node三部分:push thread,queue,thread pools
为什么这里又使用了queue[LinkedBlockingDeque],起初是直接消费redis中队列的消息,这样有个问题,就是会出现大量的任务堆积在thread pools中队列中,这里线程池使用的是

ExecutorService service = Executors.newFixedThreadPool(poolSize);
线程池使用的链表无界队列,消费redis中的队列中的数据很快,然而真正去执行合并任务的线程是非常耗时,所有等待执行的任务都会存在队列中,这样做的话jvm进程一挂所有的任务都没有了,所以这里加了一个缓冲队列,控制从redis消费消息的速度,队列大小由下面参数控制
task.quene.size=10
push thread 从redis中消费数据,获得需要合并的目录以及合并规则,并将消息推送到queue中,如果queue中数据满了,则push thread [Produce2Quene.java]就开始sleep,直到queue有剩余空间存放消息;接下来就是主线程将task提交到线程中去执行
到这里,整体设计就就完成了,代码写的比较仓促,难免有些bug,其是主要的合并主体逻辑实现为:
com.fan.merge.transform.OrcCombine
com.fan.merge.transform.ParquetCombine
大家可以围绕这两个实现类定制自己的合并规则
说一下自定义实现的一点小建议【这也是我没有实现的】:
- 任务状态保存,任务start,running,peding,success
- 失败任务重跑规则设计,重试次数
- kerberos认证登陆
苦于csdn下东西都需要积分,积分要的不多[5分],所以多多理解,哈哈
https://download.csdn.net/download/woloqun/10750290
代码写得仓促,有问题留言