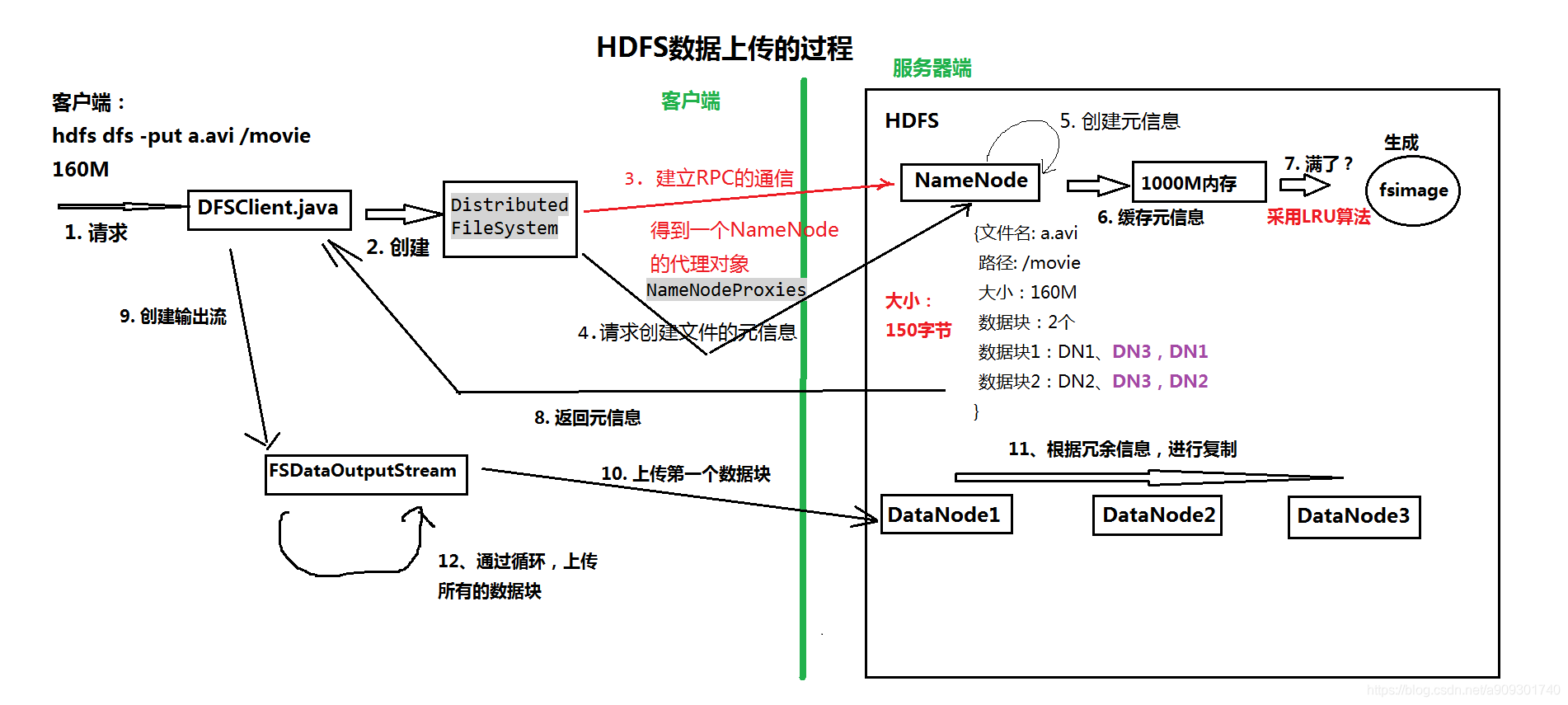
一、客户端发送请求
客户端执行上传文件的命令:hdfs dfs -put a.avi /movie。
二、DFSClient.java 创建 DistributedFileSystem
请求首先被 DFSClient.java 这个类获取到,由该类创建 DistributedFileSystem 对象。
三、建立 RPC 通信,获得 NameNode 的代理对象
DistributedFileSystem 建立与 NameNode 之间的 RPC 通信,并且得到一个 NameNode 的代理对象:NameNodeProxies。
NameNodeProxies 是个复数,是因为我们为了保证 HA(高可用),会使用多个 NameNode 节点。
四、请求创建文件的元信息
由 NameNodeProxies 去请求 NameNode 创建文件的元信息。
五、创建文件的元信息
NameNode 创建文件的元信息,元信息的内容如下:
{
"文件名" : "a.avi",
"路径" : "/movie",
"大小" : "160M",
"数据块数量" : "2个",
"数据块1位置" : "DN1, DN3, DN1",
"数据块2位置" : "DN2, DN3, DN2"
}
关于数据块的位置,可以结合 机架感知 的相关知识去理解。
六、缓存元信息
元信息也就是我们之前提到的 fsimage 文件中的数据,由于文件的元信息经常会被用到,所以 HDFS 会将它们缓存在内存中,内存的默认大小是 1000M。
这个值可以在 hadoop-env.sh 文件中修改:
# The maximum amount of heap to use, in MB. Default is 1000.
#export HADOOP_HEAPSIZE=
#export HADOOP_NAMENODE_INIT_HEAPSIZE=""
七、缓存满了将云信息持久化
将元信息缓存在内存中可以大大提高效率,但是内存空间是有限的,内存满了怎么办?
HDFS 会使用 LRU 算法,将最近未被使用的元信息存储到 fsimage 文件中。
八、返回元信息
创建完元信息之后,NameNode 会将元信息返回给 DFSClient.java。
九、创建输出流
DFSClient 会创建一个输出流 =>FSDataOutputStream。
就像我们代码中所写的那样:
@Test
public void testUpLoad() throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.220.111:9000");
FileSystem client = FileSystem.get(conf);
// 构造一个输入流
InputStream in = new FileInputStream("D:\\TestUpload.java");
// 构造一个输出流,不存在目录则会创建
OutputStream out = client.create(new Path("/tool/upload.java"));
IOUtils.copyBytes(in, out, 1024);
}
调用 create(new Path("/tool/upload.java"))方法获取到的输出流实际上是一个 FSDataOutputStream 对象。
十、上传第一个数据块
然后再通过 IO 操作上传数据到 DataNode。
IOUtils.copyBytes(in, out, 1024);
十一、根据冗余信息进行复制
为了保证数据的可用性,通过水平复制在各个 DataNode 之间复制数据。
十二、通过循环,上传所有数据块
循环操作,将剩余的数据块上传到 DataNode。