继上一期的文件压缩之后,遇到两个问题:
- 部分日志数量量较大,一天的量级已经超过100G了,所以通过ftp拉数据到本地,时间太长了,这种方式不太可取。
- 因为日志是spark streaming实时采集的,数据分布不太均匀,大的有5个G,小的只有几十MB,这样即便压缩之后大量小文件对hdfs的读取性能也是有很大影响的。
针对这种情况,给出以下方案:
1.归档
先将这部分数据进行归档,归档可以合并大量小文件,数据量不会改变
原始数据
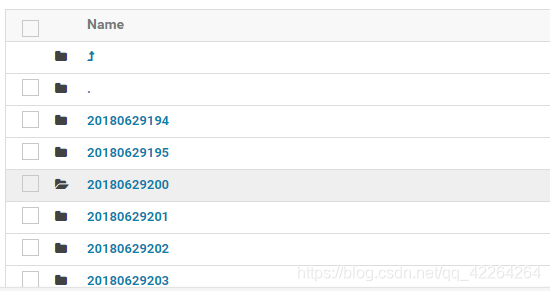
归档之后
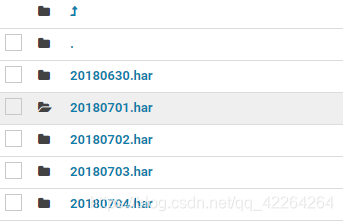
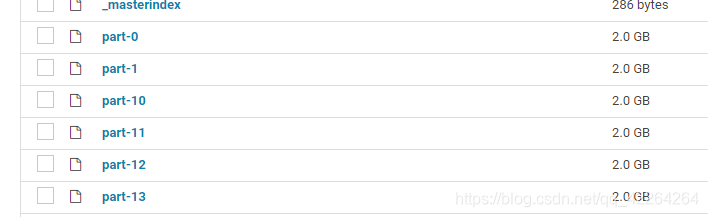
数据分布很均匀
2.压缩
由于数据量较大,ftp方式不可取,故使用程序进行压缩
/**
* Created by wpq on 2019/3/27.
* 压缩测试
*/
public class HdfsCompressTest {
public static void main(String[] args) throws ClassNotFoundException, IOException {
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println("stattime:" + df.format(new Date()));
Class<?> cal = Class.forName("org.apache.hadoop.io.compress.GzipCodec");
Configuration conf = new Configuration();
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(cal, conf);
//指定压缩和被压缩的文件
String inputfile = "/user/hdfs/rsync";
//String inputfile = "/user/hdfs/wpq/tmp";
RemoteIterator<LocatedFileStatus> files = fs.listFiles(new Path(inputfile), true);
while (files.hasNext()) {
LocatedFileStatus next = files.next();
if (next.isFile()) {
Path path = next.getPath();
if (path.toString().endsWith("gz")) {
} else {
//指定压缩输入流
FSDataInputStream in = fs.open(path);
//指定压缩输出流
String outfile = path.toString() + codec.getDefaultExtension();//添加压缩格式为后缀
FSDataOutputStream outputStream = fs.create(new Path(outfile));
CompressionOutputStream out = codec.createOutputStream(outputStream);
IOUtils.copyBytes(in, out, 4096, false);
in.close();
out.close();
fs.delete(path, true);
}
}
}
System.out.println("endtime:" + df.format(new Date()));
}
}
3.校验
抽取每月1号,15号数据各100条以及当天数据的总条数,进行对比,验证ok,干掉源数据即可