强化学习(RLAI)读书笔记第十六章Applications and Case Studies(不含alphago)
本章描述了强化学习的几个案例研究。主要想表现在实际应用问题中的一些权衡与问题。比如我们很看重专业知识移植到问题的构建和解决方法中的方式。同样我们也很关注对于成功的应用都很重要的问题表达。
16.1 TD-Gammon
强化学习中最惊人的一个应用之一是Gerald Tesauro做的backgammon游戏的算法。他的程序,也就是TD-Gammon,不需要游戏背景知识但是仍然能够接近这个游戏的世界大师级别。TD-Gammon中使用的学习算法是TD( )与非线性函数逼近的直接结合。非线性函数逼近使用的是通过反向传播TD error来训练的多层ANN网络。
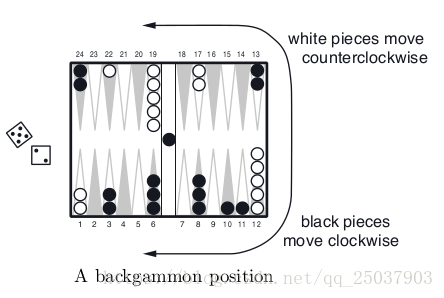
Backgammon是世界上玩的最多的游戏之一。游戏有15个白子15个黑子和一个有24个位置的棋盘,每个位置叫一个点。如图展示了一个游戏的棋盘。棋盘中是从白方的视角,此时白方掷了一次骰子,两个骰子分别是5和2,代表白方能够移动两次单个白子,分别移动5个位置和2个位置。这两次可以选择同一个子。比如他可以从位置12移动一个白子到17,移动另一个到14。白方的目标是把所有的白子都移动到19-24上然后把棋子拿下棋盘。第一个拿掉自己所有棋子的人获胜。还有一些复杂的规则,比如如果黑棋子从24移动到22,那么这个白子会被hit,然后放到中间的长条里,长条里现在有个黑子。但是如果一个点上有两个及以上白子,那么黑子不能移动到这个点。比如白方就不能用5和2这两个数字移动位置1上的白子,因为3和6上都有2个以上黑子。连续制造这种阻碍对方移动的棋子是这个游戏的主要策略。
backgammon还有一些更深的设定这里不提。有30个棋子以及24个位置(考虑棋盘外和长条,有26个),可能的移动方式是非常大的数量,远超物理可实现的计算机可以储存的范围。每一次投骰子都有大约20个合法移动,考虑到未来的移动,那么这个游戏的搜索树可能有超过400个有效分支参数,这是不可能使用传统启发式搜索来实现的。
另一方面,这个游戏和TD算法又很好的匹配。尽管游戏高度随机,但是这个游戏的状态还是可以描述的。每次游戏的最后结果可以看作是一次移动序列的最终反馈。另一方面,目前描述的理论结果不能有效地应用到这个问题。因为游戏的状态太多了不可能建立状态的查找表。另外对手的移动也是一个不确定和时变量的来源。
TD-Gammon使用的是非线性TD( )。评估值 来表示每个状态s下获胜的概率。为了得到这个概率,奖励值设定为每一步都为0,除了最后获胜的那步。TD-Gammon使用了一个标准的多层ANN来实现这个值函数,就像是下图显示的那样(实际使用的网络最后一层网络有两个额外的单元表示每个玩家的获胜率)。
网络有一个输入层一个隐藏层和一个输出层单元组成。输入时backgammon位置状态的表示,输出是那个位置状态的评估值。
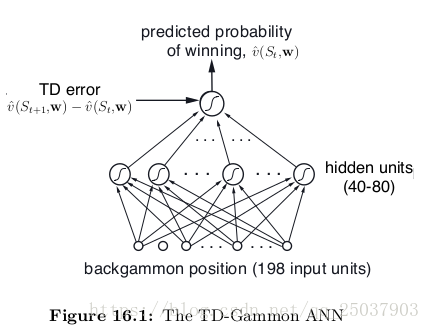
TD-Gammon的第一个版本TD-Gammon 0.0中,位置状态的表示比较直接,没有用到什么游戏背景知识。下面介绍一下输入的特征向量。网络一个有198个特征维度。每个点使用了4个单位来表示白子的数量。对于只有一个白子的点用1000表示,有两个用0100表示,有三个的话用0110表示,多于三个那么用0101表示。
对24个位置每个用4位表示白子,4为表示黑子,就有了192个。剩下的6个有两个表示的是中间的白条有几个黑子和白子。两外两个表示成功从棋盘中拿下来的黑子和白子的个数。最后两个表示本方是执黑子还是白子。他使用了非常直接的方式表示棋盘的状态但只是用了较少的变量。还对每个概念上相关的可能性都提供了一位特征,而且把它们都放进了0或1的范围。
有了棋盘状态的表示,值函数的计算就通过标准的算法来进行。从输入开始,每个单元都被加权求和放进隐藏层。隐藏层j的输出h(j)是加权求和后的非线性sigmoid函数结果。sigmoid的输出介于0-1之间,自然的解释是表示一种概率。
TD-Gammon使用了12.2节描述的半梯度形式的TD(
)算法,通过误差后向传播算法来进行梯度的计算。公式为:
表示的是神经网络的权值,
表示资格迹向量,资格迹的更新公式为:
这里设定
为1,而且除了获胜步骤之外的奖励都为0.因此TDerror通常直接就是
。
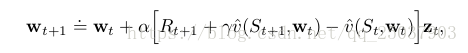

为了应用学习算法我们需要一些游戏对局的数据。Tesauro通过让两个程序进行互相对战获取数据。每次移动TD-Gammon考虑接下来20个可能的骰子情况以及相应的局势。结果位置状态是6.8节讲的afterstates。值函数网络是估计这个状态对应的值。Tesauro把算法实现为完全的增量形式,也就是说每次移动都进行更新。
网络参数初始设定为随机数字,因此刚开始的对局是很随机的,因此刚开始的表现很差,一局要进行上十万次的移动才能结束。但后来性能越来越好。
通过自我对弈300000局,TD-Gammon 0.0据说大致能够打败以前最好的程序。这很惊人因为之前最好的程序用了人类专家的移动方式来进行训练,而TD-Gammon 0.0基本是零背景知识。
它的成功暗示了一个简单的调整:增加backgammon游戏特征来表示但是让它们进行自我对弈。这就是TD-Gammon 1.0。之后的版本TD-Gammon 2.0和2.1又添加了two-ply的搜索过程。最终版本的3.0和3.1使用了160个隐藏层和three-ply的搜索。之后的工作他还加入了Trajectory Sampling的方法而非全量搜索,这带来了更低的错误率但依然保持合理的运行时间。
TD-Gammon对于最好的人类选手如何玩这个游戏也产生很大的影响。
16.2 Samuel’s Checkers Player
在Tesauro的TD-Gammon之前一个重要的先行者是Arthur Samuel在构建学习玩checkers程序时候的研究工作。Samuel是最先使用启发式搜索和现在叫做TD学习法的人之一。我们很重视Samuel的方法和现代强化学习算法之间的关系并尝试表达一部分Samuel使用它们的动机。
Samuel最开始在1952年为IBM701写一个玩checkers的程序。他的第一个学习算法的程序在1955年完成并且在1956年进行电视展示。后来的版本取得了不错的游戏水平,虽然还没到专家级。
Samuel的程序每次在当前位置进行预先的搜索,使用了现在叫做启发式搜索的方法来决定拓展搜索树的方向和何时停止搜索。最终的棋盘位置使用一个线性逼近的值函数来评估。Samuel采用了Shannon的很多建议,而且采用了它的minimax方法来找到当前最优的动作。从最后结果的评估结果开始回溯,棋盘上的每个局势都通过参考一直采用最优动作带来的最终结果来进行评估得分。这一点基于程序会每一步都采取最优动作的假设来决定,而且假设对方会尽可能最小化这个评估得分。当minimax算法到达搜索树的根节点,也就是当前位置的时候,会产生一个在这些假设下的最优动作。当然也采用了一些其它的复杂算法比如alpha-beta剪枝。
Samuel使用了两种主要的学习方法,最简单的他叫做rote learning。它很简单,由存储每个之前遇到过的棋盘局势以及评估值和minimax过程组成。结果是如果之前遇到过的局势再次被作为搜索树结束为止被遇到,那么搜索树可以直接利用存储的值进而极大减少搜索树的层数。最初的问题在于这个算法并不是直接朝着能够获胜的方向前进。Samuel通过在每一次从minimax搜索树反馈回评估值时(一个ply)都给当前局势对应的值减去一个小值来给了它一个“方向感”。Samuel觉得这个方法对最终胜利很重要。rote learning算法带来了很缓慢但是连续的进步,特别是对开局和结束的时候很有效果。它的程序后来结果是一个比普通新手要好一些的水平。
Rote learning和Samuel的一些其他工作强烈显示出temporal-difference 学习的重要想法,也就是说一个状态的值应该和可能的以后状态的值相等。他的方法在概念上和Tesauro在TD-Gammon中使用的方法一样。下图表示了Samuel算法的更新过程。每个空心圆表示下一步可能的动作,实心的表示对手的动作。每次更新根据每一次每个人动作之后的状态来决定评估值。更新从第二个人移动后的局势开始向着minimax算法的方向进行。整个过程如图所示:
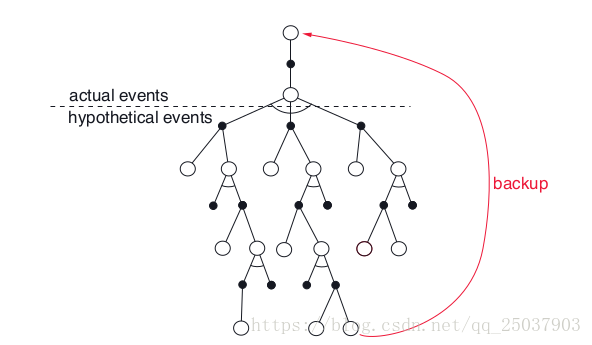
Samuel没有加入显示的奖励。最重要的特征是piece advantage特征,也就是对于当前局势下的每个棋子的数目对比敌方棋子的优势特征。他对于这个特征中每个棋子进行了固定权值的加权求和作为评估值。他的程序目标就是促进本方棋子数目的优势程度,这个优势程度在checkers里和输赢高度相关。
但是Samuel的学习算法可能丢掉了一个完备的TD算法中一个重要的部分。TD学习法可以被看成是一种让它的评估值函数与其自身一致的方式,这在Samuel的算法里可以看出来。但是同样需要一个把值函数和状态的真实值贴近的方法。通过奖励值和discounting法以及给最终状态一个特殊对待都能够促进这个目标。但是Samuel的算法里没有奖励值也没有对于结束状态的特殊对待。Samuel说自己的值函数本来也应该可以仅仅通过对每个局势给出固定的值来和真实值保持一致。他希望通过给每个棋子一个固定的较大的权值来抑制这种结果。但是尽管抑制了找到无用评估函数的概率,却不能够禁止这种结果。(这几句不太懂)
因为Samuel的学习过程没有被限制为只能找到有用的评估函数,因此有可能随着更多经验算法变得更差。Samuel确实也遇到了这个情况。他解释为可能是陷入了本地最优,但实际上有可能是算法结果和一个与输赢无关的评估函数保持了一致。
不考虑这些潜在的问题,Samuel的checkers程序得到了一个比平均更好的结果。这个程序包含了搜索所有的特征来找到对于构成评估函数最有用的特征的能力。Samuel的checker-playing程序被大家看作是人工智能和机器学习的一个重要成就。
16.3 Watson‘s Daily-Double Wagering
无聊跳过
16.4 Optimizing Memory Control
大部分电脑中使用DRAM做内存。Ipek等人设计了一个强化学习算法来改进DRAM的控制器算法,表示这个改进可以极大提高程序执行的效率。他们的想法来源于意识到当前的控制器都没有利用过去对于动作调度的经验以及没有考虑长期的调度决策结果。
DRAM中每个单元阵列都有一个缓存行,它被用来向阵列中传输数据或者从其中读取。激活动作叫做“opens a row”,就是把命令中对应位置的内存数据传输到缓存行中。当一行打开之后我们又可以对其进行读写操作。每个读操作从缓存行中传递一个字长的数据到外部的数据总线中。每个写操作从外部总线中传递一个字长的数据到这个缓存行中。之后会接到另一个激活动作,打开另一个地址读写另外的内存单元。读写当前已经打开的行会比读写新的行更快,因为不需要额外的充能和打开操作。这也叫座row locality性质。一个内存控制器会保有一个内存命令队列,队列里保存从对应的芯片上发来的读写内存的请求。控制器需要处理这个内存系统的指令来解决请求,而且需要很多的时间限制。
控制器的策略极大地影响内存系统的性能。最简单的调度策略就是根据命令到达的先后顺序进行处理。但是有时候调整执行的顺序会取得更高的性能。他们把调度的过程建模为一个MDP过程,状态是指令队列的内容,动作是对于DRAM系统的指令:precharge,activate,read,write和noOp。读写的动作奖励是1,其他动作是0。状态转移被看做是一个随机过程,因为到达指令队列的指令是随机的。对这个系统来说每个状态可行的动作很重要。这里需要保证与 DRAM系统的一致性,因此对于每个状态他们都定义了一组可行的动作。这也解释了为什么有noOp这个动作。
这个调度算法选用了Sarsa算法来进行动作值函数的学习。状态被表示为一个六个整数表达的特征。算法使用了tile coding加hashing实现的线性函数逼近。tile coding有32个方格,每一个表示256个 动作值。
状态特征包括指令队列中的读请求数量,写请求数量等等。一个有趣的事情在于在MDP中使用的状态表示和得到可行动作时使用的状态表示不一致。因为Tile coding的输入是从指令队列的内容中衍生的,因此和硬件实现的很多限制有关。这样动作限制保证了算法的exploration不会影响整个系统的完好。
因为这个任务的目标是完成一个能够及时处理片上指令的调度控制算法,因此需要考虑硬件实现。具体不说了。
Ipek在仿真环境中评估了他们的算法与其他三个控制器算法。最终得到的结果是他们的算法能够极大地提高储存器的性能。但是在片上实现一个机器学习算法代价太大,因此这个算法没有被用到芯片上。尽管如此他也可以说他们的结果能够比较简单地提高内存控制器的性能而不用选择更加复杂更加难以实现的方式来达到同样的效果。
16.5 Human-level Video Game Play
将强化学习算法应用到实际问题中的一个最重要的挑战就是如何表示和储存值函数或者策略。不过不是之前讲的那些能够建立查找表的状态很有限的问题,那么必须要使用参数化的函数逼近方法。无论线性还是非线性,函数逼近都依赖于能够表达问题状态的特征表示。大部分成功的强化学习应用都很大程度归功于基于人类只是或者特定问题了解的精心设计的特征表示。
谷歌DeepMind的一组研究者开发了一个惊人的应用实例。例子中的一个深度多层ANN能够自动化进行特征设计过程。多层ANN从1986年开始就被用在强化学习中用来函数逼近,也通过将反馈传播与强化学习结合取得了一些惊人成就。比如之前讲的TD-Gammon和Watson的例子。这些应用都是受益于多层ANN学习任务相关的特征的能力。但是这些例子里都需要将输入表示为针对特定问题的设计好的特征。
Mnih和他的合作者发明了一个强化学习算法叫做deep Q-network(DQN),它结合了Q-learning算法和一个深层卷积ANN。在他之前卷积神经网络也取得了很多惊人结果,但是没有和强化学习广泛结合。他们使用了DQN来表明一个强化学习智能体不需要依赖于针对特定问题的特征集合就能够达到一个很高的能力级别。为了说明这一点,他们使用DQN通过一个游戏模拟器完了49款不同的Atari 2600的游戏。算法对于49款游戏每一款都学出来不同的策略,而算法对于不同的游戏都使用了相同的输入和网络结构以及参数。深度卷积神经网络学习到把原始的对于每个游戏都一样的输入变形为能够针对不同游戏的值函数需要的表达。这些值函数表达对于每个游戏达到高水平是必须的。
DQN和TD-Gammon算法一样都使用了多层ANN来作为一个半梯度形式的TD算法的函数逼近,它们的梯度通过反向传播来计算。但是这里使用的是半梯度形式的Q-learning算法而不是TD( )算法。TD-Gammon算法计算每次动作后的afterstate的值,但这个状态对于Atari游戏很难获得。另一个使用Q-learning的算法的动机在于DQN使用了experience replay的方法,这需要一个off-policy的算法。
在描述DQN算法细节之前先看看它能够到达的游戏水平。Mnih他们比较了DQN和当时纸面成绩最好的人类测试员和随机选择动作进行对比。纸面成绩最好的系统是使用了线性函数逼近加上针对游戏设计特定特征的系统。DQN通过与游戏模拟器进行五千万帧图片的交互来学习一个游戏,这对赢了大概38天的游戏经验。测试的所有游戏中,DQN在除了其中6款外的所有游戏中都比之前最好的系统玩的更好,也在22款游戏中玩的比人类选手好。Mnih总结认为DQN算法学习到的游戏水平在46个游戏中的29个中达到或超过了人类水平。
对于一个人工智能系统,达到这个水平的性能已经非常惊人了,更加惊人的点在于达到这个水平的是同一个学习系统而且不依赖于任何针对游戏的调整。
一个人玩这49款Atari游戏时看到的是210x160像素点的图像帧,刷新频率60Hz且可能有128种颜色。原则上应该就直接输入这些图像,但是为了节省空间,Mnih预处理了这些图像得到了84x84的色彩阵列。因为游戏中很多状态没法从图像上得到,Mnih存储了4个最近的图像帧,所以输入为84x84x4的维度。这没有将所有游戏的部分不可见性去除,但是确实让过程更加的马尔科夫化了。一个重要的一点是,这些预处理对于46个游戏都是相同的。由于没有其它的游戏知识,我们认为这个输入向量对于DQN是原始输入。
DQN的基础结构和深度卷及网络相同。DQN有三个隐藏层,接了一个全连接层,之后是一个输出层。这三个连续的隐藏卷积层制造了32个20x20的特征映射,64个9x9的特征映射,以及64个7x7的特征映射。每个特征映射的激活函数是rectifier函数(max(0,x))。第三个隐藏层的这3136(64x7x7)个单元都连接到全连接层的512个单元,之后都连接到输出层的18个单元。这18个单元每个都对应游戏中的可能动作。可以看作是有18个网络每一个输出都对应着一个动作的概率,实际上这些网络共享前面几层,但是输出层使用不同的方式利用这些共享网络提取出的特征。
DQN的奖励信号表明每一个时间步骤到下一步的游戏得分的变化:增加得到+1奖励,减少-1,不变为0。DQN使用的是 -greedy策略,随着前一百万帧 线性变小,后面不变。其他的参数,比如学习步长,discount rate和一些其它用来搜索之类的参数都固定不变。
DQN在选择一个动作之后,游戏模拟器执行动作然后反馈一个奖励值和下一帧图像。这些图像再放进四帧的栈中之前进行预处理。先不管Mnih对Q-learning算法的改进,DQN使用了以下的半梯度法的Q-learning算法来更新网络的权值:
公式中的梯度使用反向传播算法进行计算。Mnih使用了mini-batch方法在得到了一小个batch(32帧)的图像的梯度之后再更新权值。相比于每个图像都进行一次更新,这能够带来更平滑的样本梯度。他们也采用了叫做RMSProp的算法来加速学习过程。
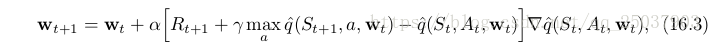
Mnih在基础的Q-learning算法上进行了三种改进。第一,使用了一种叫做experience play的方法。这个方法把以前每个时间步的经验都存起来用来之后的权值更新。每次游戏模拟器在当前状态执行完动作转移到下一个状态,它都会把 四元组存在replay memory里。这个存储空间存储了同一个游戏的很多次游戏经验。每个时间步的Q-learning更新都是通过从这个memory里随机采用出的四元组进行的。状态 的下一个状态不是采取了动作后的 而是随机的一个没有关联的状态。因为Q-learning算法是off-policy算法,因此不需要利用一个有关系的轨迹序列。
这个方法提供了很多优势。能够从经验中更加高效地学习。也能够减小每次更新的方差,因为每次更新一个batch内遇到的都是没有关系的四元组。并且通过移除掉当前连续经验对于当前权重的依赖性,更加减少了不稳定性的来源。
第二点改进也是提高稳定性。像其它bootstrap的算法一样,Q-learning算法的更新目标依赖于当前动作值函数的估计值。如果使用了参数化函数逼近方法,那么正在更新的参数和目标值函数估计使用的是同样的参数。之前11章中讲过这会导致抖动或者发散。
为了解决这个问题,Mnih使用了一个让Q-learning算法更加接近监督学习算法的方式。每次经过一个固定数目C次权值更新,算法都把当前权值w塞到另一个网络中并存起来,在以后C次更新w时保持不变。而这个权值不变的网络的输出作为Q-learning算法更新时的目标值的计算基础。即:
最后一点对于标准Q-learning算法的改进也是为了提高稳定性。他们把每次的TD error限制在
的范围内。
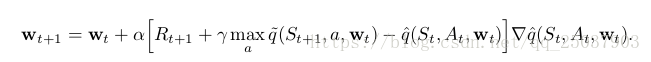
Mnih在其中5个游戏中训练和大量的轮次来对比不同改进对于DQN算法性能的影响。他们使用了四种组合模式,分别对应是否添加experience replay和重复的用来输出更新目标值的网络的组合。数据表明每种改进都能极大提高算法性能,而组合起来提高的最明显。他们还对比了和线性函数逼近的性能,对比结果里深度卷积网络的版本效果提高惊人。
人工智能里一个永恒的目标就是能够制造出能够解决不同任务的智能体。机器学习对于完成这个目标的期望被需要针对问题的特征所打击。而DeepMind的DQN算法作为完成一个单个智能体对应不同任务的目标的里程碑。这个算法并不是学出一个能够解决多种问题的智能体,而是表明深度学习能够减少甚至去掉对于针对问题的设计和调整。但是在一些需要人类额外知识的游戏里DQN算法表现得很差。尽管还有一些局限,但是DQN通过让人印象深刻地展现出组合强化学习和现代深度学习方法的潜力,极大地提高了机器学习的最好表现。
16.6 Matering the Game of Go
单开了一个文章。
16.7 Personalized Web Services
个性化网站服务,比如新闻或者广告的推送是提高网站的用户满意度的一种方式,也是提高一个市场份额的手段。强化学习系统可以通过对用户返回的相应调整来改进推荐策略。
在市场营销中有一个用了很久的方法叫做A/B测试法。这是一种简化的强化学习算法,就像是一个有两个按钮的老虎机,选择A或B两种形式哪种是用户更喜欢的。因为它是non-Associative的,所以无法个性化内容推送。通过添加用户的画像可以支持个性化服务。这样就可以构成一个contextual bandit问题来提高用户的点击率。就像Li等人(2010)年通过用户点击过的新闻故事作为特征进行个性化雅虎的一个主页内容一样。他们的目标是最大化click-through rate(CTR)。
Theocharous等人认为通过将个性化推荐构建为MDP且以最大化用户重复访问下点击的数量为目标可以得到更好的结果。通过contextual bandit问题设定中得到的策略是贪心的,因为它没有考虑动作的长期影响。这些策略对待每一次的访问都像是这是一个随机挑选的全新的访问者一样。
Theocharous等人用一个买车的例子来对比长期策略和一个贪心策略。当一个打折广告使用贪心策略进行展示时,用户可能立即进行点击购买。用户可能接收广告或者离开,但是如果他们离开之后回来,还会看到同样的广告。而一个长期策略可以在展示最终的打折之前为用户提供沉浸式体验。可能先展示一个金融政策,然后称赞产品有很好的售后,最后在展示打折信息。这种策略可以带来重复用户更多的点击。
作为Adobe公司的员工,Theocharous做了个实验来观察设计的策略能不能在长期视角下获得更多点击。这个实验的一个重要部分就是线下的评估。他们希望能够尽量提高这个策略的可信程度来降低应用一个新策略的风险。尽管高可信的线下评估是这个工作的重要部分,我们这里只关注算法和结果。
他们比较了两种算法。第一种是叫做greedy optimization,最大化即时点击率。另一种算法是基于MDP结构的强化学习算法,为了提高每个用户多次访问网页的点击率。后一个算法叫做life-time-value(LTV)optimization。两种算法都要面临奖励稀疏的问题,会带来反馈值很大的方差。
银行系统的数据集被用来训练和测试这些算法。greedy optimization算法基于用户特征来做一个预测点击的映射函数。这个映射通过监督学习来训练,使用的是随机森林算法(RF)。这个算法被广泛用在工业中,因为很有效,且不易过拟合而对outlier不敏感。
LTV optimization算法使用一个batch模式的强化学习算法叫做fitted QIteration(FQI)。这是fitted value iteration算法的一个q-learning算法变体。batch模式意味着这些数据从一开始就是都可以获得的,和本书之前讲的在线形式的需要等待学习算法执行动作生成数据的算法不同。
为了评估策略的表现,他们使用了一个CTR指标和LTV指标来进行评估。他们分别是:
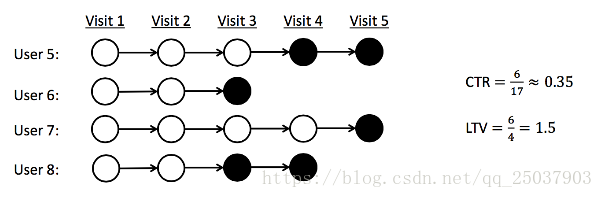
下图表示了这两种描述的不同点:
实心圆表示了用户的一次点击。下图中CTR指标是0.35而LTV是1.5。因为LTV对于个人用户重复访问时更大,它是表示一个策略促进用户与网站进行更多交互的成功程度指示指标。
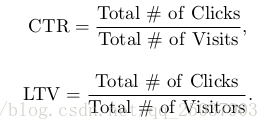
结果显示greedy optimization算法在CTR评估时表现得更好,而LTV optimization在使用LTV评估时更好。另外off-policy评估方法的高可信程度保证了LTV optimization算法能够得到对于实施的策略改进。