参考链接:https://www.missshi.cn/api/view/blog/5a2272ad9112b35ff3000000

最后是代码实战。
1.Mini-Batch梯度下降法:很大的提高了对海量数据的训练速度。
对海量数据进行分为若干组,每次迭代过程中,对其中的一组数据进行计算并进行迭代。而不再是每次迭代过程中使用全量数据。 这些每个小组就是我们称的Mini-Batch。
在MiniBatch梯度下降法中,我们需要选择一个超参数batch-size的值。
首先,我们来考虑两种特殊情况:
当batch-size=样本数量m时:该方法实际为Batch梯度下降法。此时,每个Batch为全量的数据集。
当batch-size=1时:该方法实际为随机梯度下降法。此时,每个Batch为一个样本。

对于Batch梯度下降法而言,其没有发生震荡,稳定逼近最优值,需要的迭代次数最少,但是耗时最多。而对于随机梯度下降法,其波动程度最大,需要的迭代次数最多。而MiniBatch梯度下降法位于两者之间。
计算速度:
对于随机梯度下降法而言,虽然其计算速度很快,但是它忽略了利用向量化带来的速度提升。而是在每次计算中使用当前样本进行训练。 MiniBatch梯度下降法很好地结合了随机梯度下降法、Batch梯度下降法:一方面利用了向量化带来的计算效率提升,寻优过程的减少了迭代次数。另一方面,避免了海量数据造成的计算速度慢的问题。
batch-size的值选择:
当训练样本集不大时(小于2000),可以直接使用Batch梯度下降法。
其他情况下batch-size通常可以选择64,128, 256, 512。(主要考虑计算机内存/显存的影响)
2.指数加权平均法
假设我们拥有了过去180天的伦敦气温,我们需要对后续的每日温度进行预测,主要介绍定义和偏差修正后的指数加权平均,是学习下面这种算法的基础,详情参看原文。
3.momentum梯度下降法:

4.RMSProp梯度下降法

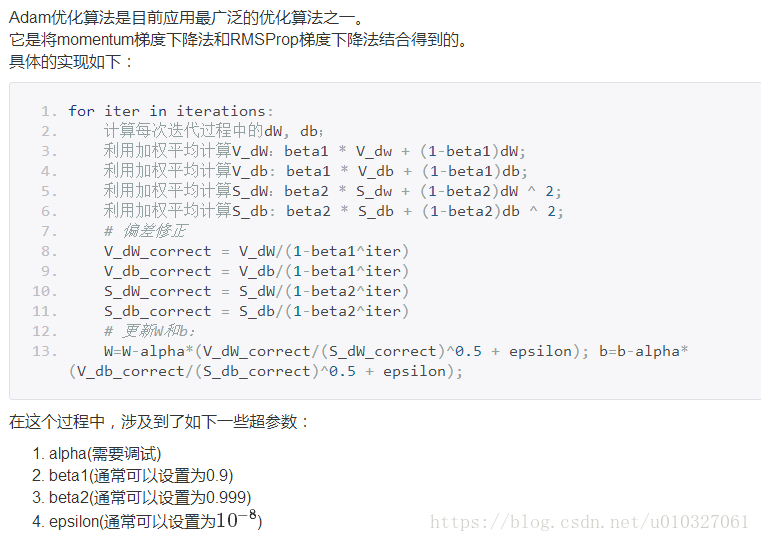
在早期时,保持较大的学习速率加速向最优值逼近。而当其达到最优值附近时,则学习速率不断降低从而导致较小的波动程度。


在深度学习中,由于参数的维度很大,局部最优其实对本身的寻优过程影响并不大。
因为在实际应用中,我们所达到的梯度为0的点通常并不是最不最优点,而是鞍点。对于鞍点而言,其实并没有达到局部最优,梯度下降法仍然后继续进行寻优迭代过程。
假设在一个20000维的空间中,如果想要达到局部最优点,那么就需要所有的维度方向全部达到局部最优值,这种概率往往是非常小的,可以忽略不计。
8.以上的优化算法代码实践:
https://www.missshi.cn/api/view/blog/59bbcae0e519f50d04000204